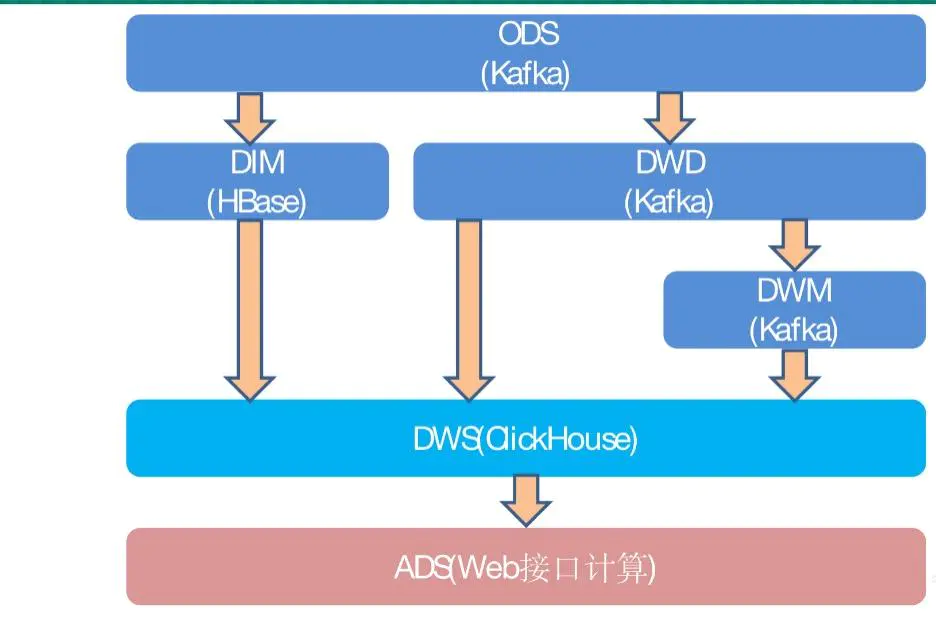
- 数据源层: ODS(Operational Data Store)
ODS 层, 是最接近数据源中数据的一层, 为了考虑后续可能需要追溯数据问题,ODS层原封不动地接入原始数据。比如从监听数据库变更的Canal读取数据后放入kafka - 数据明细层: DWD(Data Warehouse Detail)
该层一般保持和 ODS 层一样的数据粒度,并且提供一定的数据质量保证。DWD 层要做的就是将数据清理、整合、规范化、脏数据、垃圾数据、规范不一致的、状态定义不一致的、命名不规范的数据都会被处理。在该层也会做一部分的数据聚合,将相同主题的数据汇集到一张表中,提高数据的可用性。这一层也是为了提高复用性。比如DWS层有多个主题要统一,可能都要用到DWD的某表,所以独立出DWD层有助于数据复用,里面数据叫事实表,跟DIM维度表相对应 - 维表层: DIM(Dimension)
如果维表过多,也可针对维表设计单独一层,维表层主要包含两部分数据:比如枚举值含义,SPU,SKU具体内容,省份等 - 数据中间层: DWM(Data WareHouse Middle)
该层会在 DWD 层的数据基础上,数据做轻度的聚合操作,生成一系列的中间表,提升公共指标的复用性,减少重复加工。直观来讲,就是对通用的核心维度进行聚合操作,算出相应的统计指标。比如订单宽表,支付宽表等,当然数据源是可以直接从DWM结合DIM取到,只是为了减少聚合提高复用增加了这一层 - 数据服务层: DWS(Data WareHouse Service)
DWS 层为公共汇总层,会进行轻度汇总,粒度比明细数据稍粗,基于 DWD 层上的基础数据,整合汇总成分析某一个主题域的服务数据,一般是宽表。DWS 层应覆盖 80% 的应用场景。又称数据集市或宽表, 主要提供主题域查询 - ADS: 也叫APP数据应用层,全称可能是Application Data Service
大屏直接从直接获取数据,ADS从DWS获取数据
链接:https://www.jianshu.com/p/2ba9c348db10