简介
上篇Python爬虫爬取动态页面思路+实例(一)提到,爬取动态页面有两种方法
- 分析页面请求
- selenium模拟浏览器行为(这篇介绍这个)
理论上来讲,这种方法可以应对各种动态加载,因为模拟人的行为嘛,如果人自己用浏览器来看网页都加载不出数据来,这网站吃枣药丸。但是它的显著缺点就是——慢。所以一般情况下,这是一种万不得已的方法。
selenium是一种自动化测试的工具(话说这方面我并不懂),懂自动化测试的同学不用我介绍,不懂的同学,跟着我的思路走就好了,不影响我们写爬虫。
如何安装selenium我就不介绍了,网上很多教程,如果你在调用Firefox的时候出现了问题,那么请留意一下本文参考资料1。
首先说一下整体的思路,我们知道,动态加载的数据都是用户通过鼠标或键盘执行了一定的动作之后加载出来的。所以我们通过selenium提供的webdriver工具调用本地的浏览器,让程序替代人的行为,滚动页面,点击按钮,提交表单等等。从而获取到想要的数据。所以我认为,使用selenium方法爬取动态页面的中心思想是模拟人的行为。
这里举一个例子,爬取自己QQ空间的说说。
说说
在模拟人的行为的中心思想指导下,我们首先来一步一步的分析出,人都需要做什么。这个过程中不放代码了,代码最后贴出来,注释也很详细,不想看分析的直接看代码也OK。
百度qq空间,进入qq空间的登陆页面,发现默认是快速登陆方式,所以得先点击账号密码登陆,检查元素,发现这个按钮有id,好办。得出第一步:点击账号密码登陆。
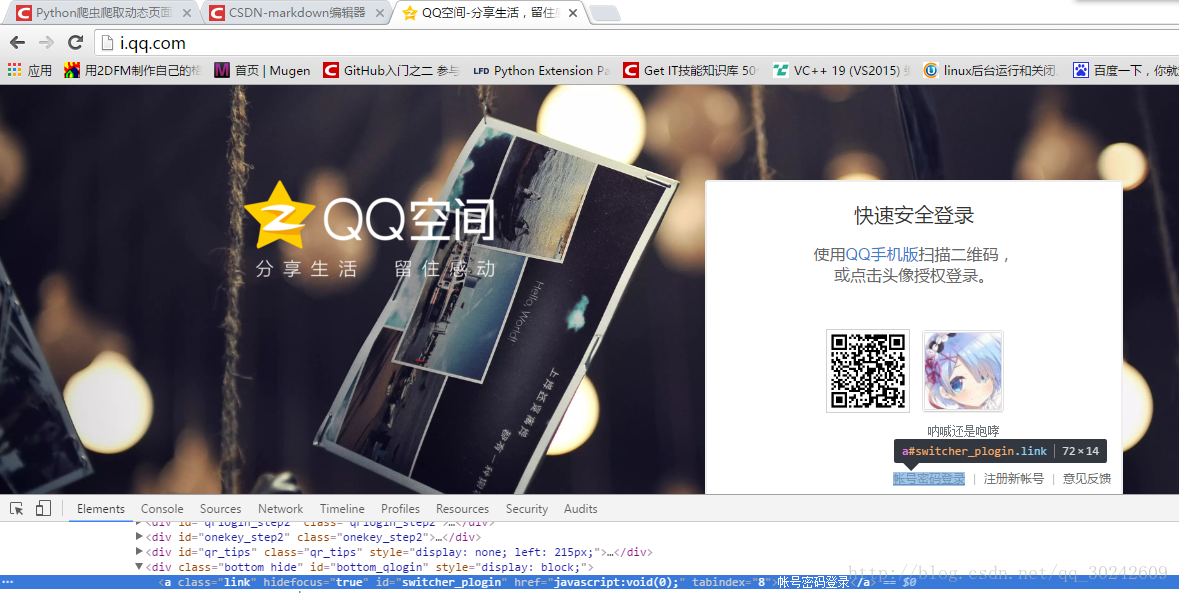
点过之后,该填写表单了,填完之后点击登陆按钮,这里的帐号密码框和登陆按钮通过检查元素也可以发现都是有id的,获取很方便。第二步:填写表单并点击登陆按钮。
登陆成功后就进入了最近消息的页面,然后找到说说按钮,点进去(你的空间主题可能跟我不一样,不过点进去的url除了qq号部分不同,其它地方应该是相同的)。
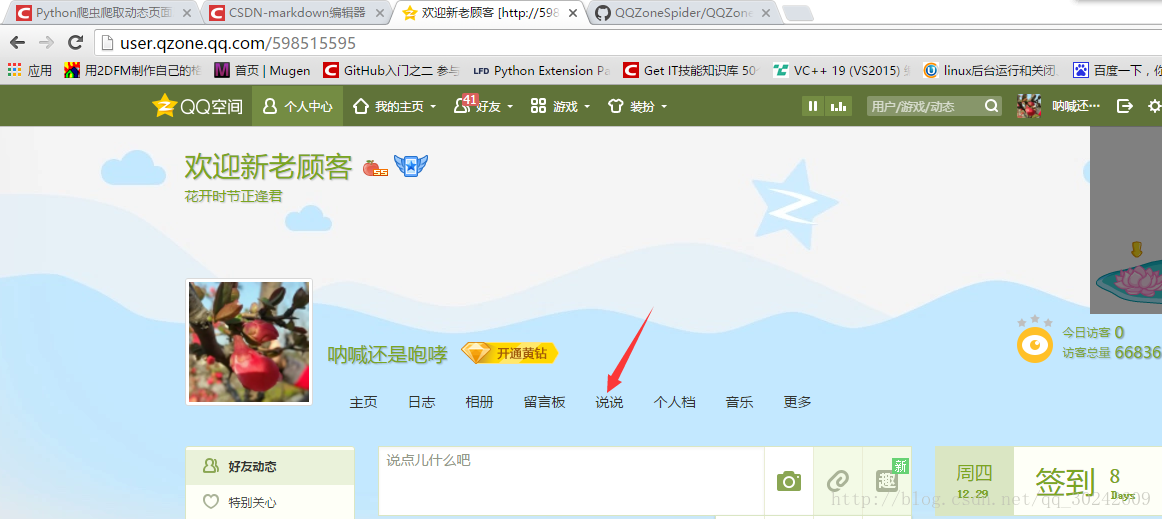
可以看到说说页的url格式是
http://user.qq.com/qq号/311- 1
第三步:找到说说所在的url
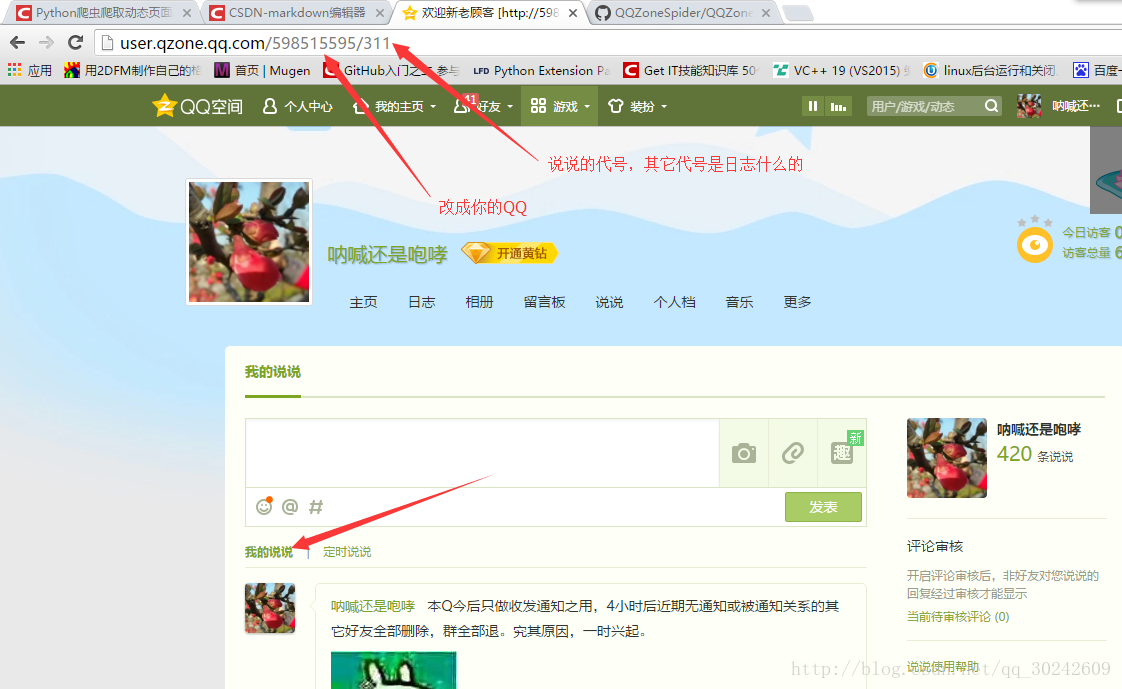
然后我们就下拉滚动条,可以直观的看到说说是动态加载的,大概加载个四五次,就出现了分页的按钮。而且检查元素后发现十分感人,“下一页”按钮也有id。
不过注意了,经过我的分析,这个id会随着你的点击次数逐次加一,不妨试一下,下两张图是没点过和点过一次的id。
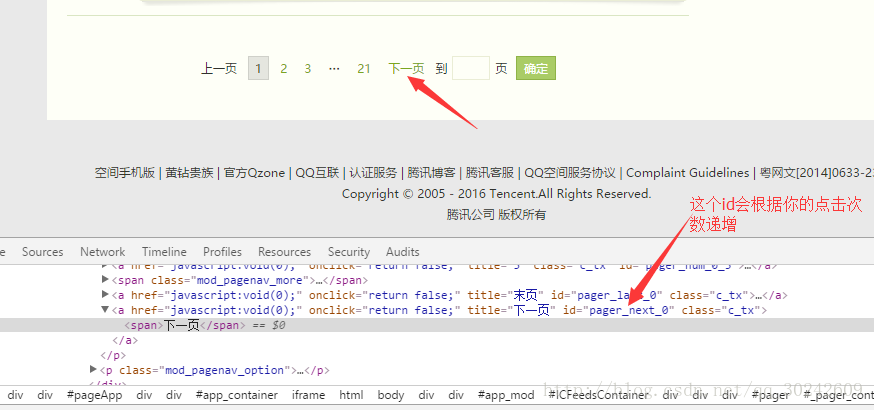
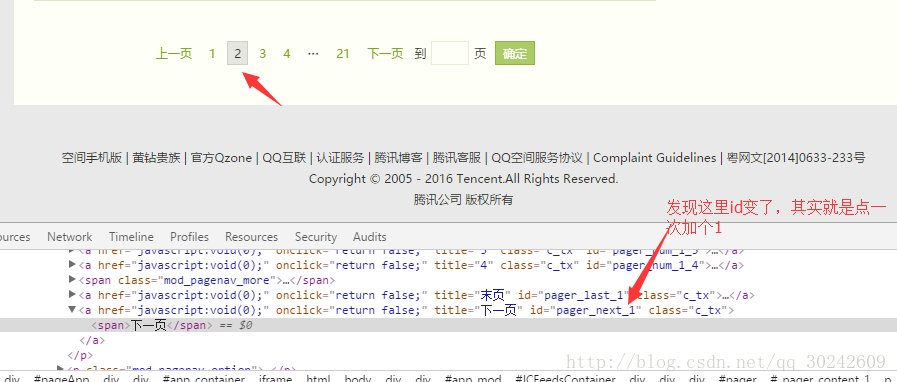
得出第四步:拖到页面末尾,点击“下一页”。
当页面到达最后一页,”下一页”按钮的id就消失了,也就是说程序里就查不到这个元素了,所以停止就好了。
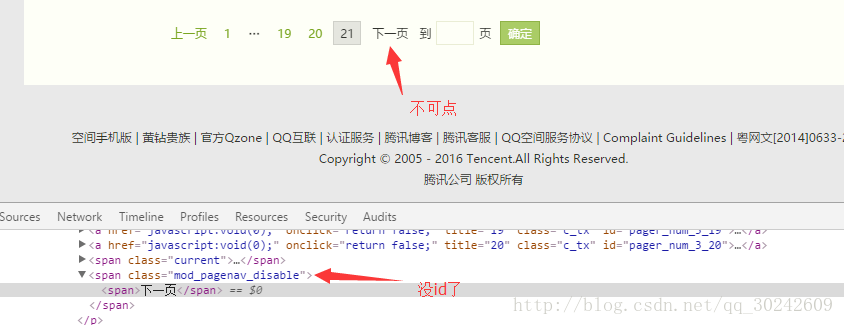
第五步:重复第四步,直到“下一页”按钮不可点
根据以上得出的五步,再结合一下selenium的简单语法,就能实现获取动态加载的说说的功能。从下面的代码里可以看出,程序的流程就是再模拟我们上面分析的五步。
代码:
几点说明:
- 注意注释中解释的frame的选择问题
- 注意注释中登陆处的手动处理
- 因为QQ空间里的id实在太好用了,我都是用的通过id查找,元素,其实selenium还可以用其它的方式,比如xpath,css等等
- unittest模块是python的一个内置测试模块,详情参考下面的资料5
- 目前我只实现了孤零零的爬说说(而且还没爬回复),如果你实现了爬别人的说说或者自动留言,自动评论等有趣的功能(有空我会搞搞这些),欢迎pull request
- github地址kongtianyi/QQZoneSpider
#coding:utf-8
import unittest
import time
from selenium import webdriver
from bs4 import BeautifulSoup
class seleniumTest(unittest.TestCase):
user = 'xxxxxxxx' # 你的QQ号
pw = 'xxxxxx' # 你的QQ密码
def setUp(self):
# 调试的时候用firefox比较直观
# self.driver = webdriver.PhantomJS()
self.driver = webdriver.Firefox()
def testEle(self):
driver = self.driver
# 浏览器窗口最大化
driver.maximize_window()
# 浏览器地址定向为qq登陆页面
driver.get("http://i.qq.com")
# 很多时候网页由多个<frame>或<iframe>组成,webdriver默认定位的是最外层的frame,
# 所以这里需要选中一下frame,否则找不到下面需要的网页元素
driver.switch_to.frame("login_frame")
# 自动点击账号登陆方式
driver.find_element_by_id("switcher_plogin").click()
# 账号输入框输入已知qq账号
driver.find_element_by_id("u").send_keys(self.user)
# 密码框输入已知密码
driver.find_element_by_id("p").send_keys(self.pw)
# 自动点击登陆按钮
driver.find_element_by_id("login_button").click()
# 如果登录比较频繁或者服务器繁忙的时候,一次模拟点击可能失败,所以想到可以尝试多次,
# 但是像QQ空间这种比较知名的社区在多次登录后都会出现验证码,验证码自动处理又是一个
# 大问题,本例不赘述。本例采用手动确认的方式。即如果观察到自动登陆失败,手动登录后
# 再执行下列操作。
r = ''
while r != 'y':
print "Login seccessful?[y]"
r = raw_input()
# 让webdriver操纵当前页
driver.switch_to.default_content()
# 跳到说说的url
driver.get("http://user.qzone.qq.com/" + self.user + "/311")
# 访问全部说说需要访问所有分页,需要获取本页数据后点击“下一页”按钮,经分析,“下一页”
# 按钮的id会随着点击的次数发生变化,规律就是每点一下加一,所以需要在程序中动态的构造
# 它的id。(或者不用id改用xpath)
next_num = 0 # 初始“下一页”的id
while True:
# 下拉滚动条,使浏览器加载出动态加载的内容,可能像这样要拉很多次,中间要适当的延时(跟网速也有关系)。
# 如果说说内容都很长,就增大下拉的长度。
driver.execute_script("window.scrollBy(0,10000)")
time.sleep(3)
driver.execute_script("window.scrollBy(0,20000)")
time.sleep(3)
driver.execute_script("window.scrollBy(0,30000)")
time.sleep(3)
driver.execute_script("window.scrollBy(0,40000)")
time.sleep(5)
# 很多时候网页由多个<frame>或<iframe>组成,webdriver默认定位的是最外层的frame,
# 所以这里需要选中一下说说所在的frame,否则找不到下面需要的网页元素
driver.switch_to.frame("app_canvas_frame")
soup = BeautifulSoup(driver.page_source, 'xml')
contents = soup.find_all('pre', {'class': 'content'}) # 内容
times = soup.find_all('a', {'class': 'c_tx c_tx3 goDetail'}) # 发表时间
for content, _time in zip(contents, times): # 这里_time的下划线是为了与time模块区分开
print content.get_text(), _time.get_text()
# 当已经到了尾页,“下一页”这个按钮就没有id了,可以结束了
if driver.page_source.find('pager_next_' + str(next_num)) == -1:
break
# 找到“下一页”的按钮
elem = driver.find_element_by_id('pager_next_' + str(next_num))
# 点击“下一页”
elem.click()
# 下一次的“下一页”的id
next_num += 1
# 因为在下一个循环里首先还要把页面下拉,所以要跳到外层的frame上
driver.switch_to.parent_frame()
def tearDown(self):
print 'down'
if __name__ == "__main__":
unittest.main()
结语
在测试的时候使用selenium+Firefox,在写好了代码实际运行的时候不妨换成selenium+PhantomJS,后者是一个无界面的浏览器,效率会高些。
本人于selenium也是初窥门径,如有不正确或不清晰之处,请各位大侠不吝批评指正!