一、生成HTML字符串
//生成DOM字符串结构
HtmlNode container = HtmlNode.CreateNode("<div />");
HtmlNode title = HtmlNode.CreateNode("<h3 />");
title.InnerHtml = "张三丰";
HtmlNode link = HtmlNode.CreateNode("<a />");
link.InnerHtml = "点击进入";
link.SetAttributeValue("href", "http://wwww.gongjuji.net");
container.AppendChild(title).AppendChild(link);
Console.WriteLine(container.OuterHtml);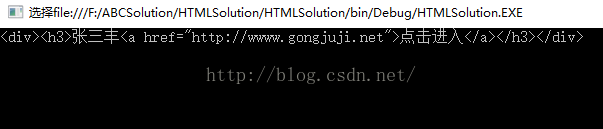
二、解析HTML字符串或本地html文件
//解析html 字符串或者本地html文件
HtmlDocument doc = new HtmlDocument();
string html = "<div id="demo"><span style="color: red; "><h1>Hello</h1> </span></div>";
doc.LoadHtml(html);
HtmlNode demo = doc.GetElementbyId("demo");
Console.WriteLine(demo.InnerHtml);
//注:InnerText中会有换行或空格等,需要特殊处理
Console.WriteLine(demo.InnerText);
Console.WriteLine(demo.InnerText.Length);
三、解析处理结合XPath使用更加方便
XPath简明介绍
XPath 使用路径表达式来选取 XML 文档中的节点或节点集。节点是通过沿着路径 (path) 或者步 (steps) 来选取的。
下面列出了最有用的路径表达式:
nodename:选取此节点的所有子节点。
/:从根节点选取。
//:从匹配选择的当前节点选择文档中的节点,而不考虑它们的位置。
.:选取当前节点。
..:选取当前节点的父节点。
<?xml version="1.0" encoding="utf-8"?>
<Articles>
<Article>
<Title>在ASP.NET中使用Highcharts js图表</title>
<Url>http://zhoufoxcn.blog.51cto.com/792419/537324</Url>
<CreateAt type="en">2011-04-07</price>
</Article>
<Article>
<Title lang="eng">Log4Net使用详解(续)</title>
<Url>http://blog.csdn.net/zhoufoxcn/archive/2010/11/23/6029021.aspx</Url>
<CreateAt type="zh-cn">2010年11月23日</price>
</Article>
<Article>
<Title>J2ME开发的一般步骤</title>
<Url>http://blog.csdn.net/zhoufoxcn/archive/2011/06/12/6540223.aspx</Url>
<CreateAt type="zh-cn">2011年06月12日</price>
</Article>
<Article>
<Title lang="eng">PowerDesign高级应用</title>
<Url>http://zhoufoxcn.blog.51cto.com/792419/166415</Url>
<CreateAt type="zh-cn">2007-09-08</price>
</Article>
</Articles>