目标:爬取湖南大学2018年在各省的录取分数线,存储在txt文件中
部分表格如图:
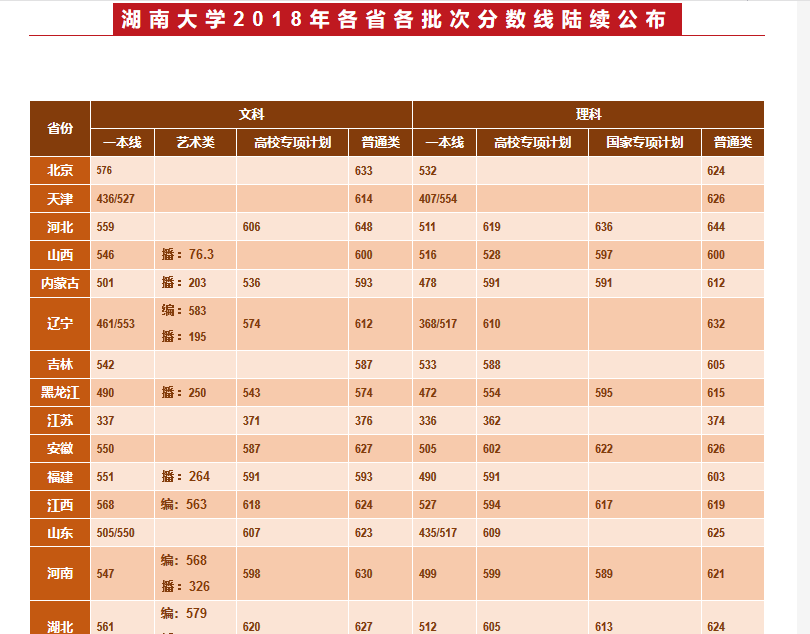
部分html代码:
<table cellspacing="0" cellpadding="0" border="1">
<tbody>
<tr class="firstRow" >
<td rowspan="2" ><p ><strong><span >省份</span></strong></p></td>
<td colspan="4" ><p ><strong><span >文科</span></strong></p></td>
<td colspan="4" ><p ><strong><span >理科</span></strong></p></td>
</tr>
<tr >
<td ><p ><strong><span >一本线</span></strong></p></td>
<td ><p ><strong><span >艺术类</span></strong></p></td>
<td ><p ><strong><span >高校专项计划</span></strong></p></td>
<td ><p ><strong><span >普通类</span></strong></p></td>
<td ><p ><strong><span >一本线</span></strong></p></td>
<td ><p ><strong><span >高校专项计划</span></strong></p></td>
<td ><p ><strong><span >国家专项计划</span></strong></p></td>
<td ><p ><strong><span >普通类</span></strong></p></td>
</tr>
<tr >
<td ><p ><strong><span >北京</span></strong></p></td>
<td valign="middle" align="left"><p ><span ><strong><span lang="EN-US">576</span></strong></span></p></td>
<td valign="middle" align="left"><br></td>
<td valign="middle" align="left"><br></td>
<td valign="middle" align="left"><p ><span ><strong><span lang="EN-US">633</span></strong></span></p></td>
<td valign="middle" align="left"><p ><span ><strong><span lang="EN-US">532</span></strong></span></p></td>
<td valign="middle" align="left"><br></td>
<td valign="middle" align="left"><br></td>
<td valign="middle" align="left"><p ><span ><strong><span lang="EN-US">624</span></strong></span></p></td>
</tr>
<tr >
<td ><p ><strong><span >天津</span></strong></p></td>
<td valign="middle" align="left"><p ><span ><strong><span lang="EN-US">436/527</span></strong></span></p></td>
<td valign="middle" align="left"><br></td>
<td valign="middle" align="left"><br></td>
<td valign="middle" align="left"><p ><span ><strong><span lang="EN-US">614</span></strong></span></p></td>
<td valign="middle" align="left"><p ><span ><strong><span lang="EN-US">407/554</span></strong></span></p></td>
<td valign="middle" align="left"><br></td>
<td valign="middle" align="left"><br></td>
<td valign="middle" align="left"><p ><span ><strong><span lang="EN-US">626</span></strong> </span></p></td>
</tr>
......
<tr >
<td ><p ><strong><span >上海</span></strong></p></td>
<td colspan="8" valign="top"><p ><strong><span >本科线</span></strong><strong><span lang="EN-US">/</span></strong><strong><span >自主招生参考线:</span></strong><strong><span lang="EN-US">401/502</span></strong><strong><span >;</span></strong><strong><span lang="EN-US"> </span></strong><strong><span >(专业组)最低投档线:<span >533</span></span></strong></p></td>
</tr>
<tr >
<td ><p ><strong><span >浙江</span></strong></p></td>
<td colspan="8" valign="top"><p ><strong><span >本科线</span></strong><strong><span lang="EN-US">/</span></strong><strong><span >一段线:</span></strong><strong><span lang="EN-US">344/588</span></strong><strong><span >;</span></strong><strong><span lang="EN-US"> </span></strong><strong><span >(专业)最低投档线:639</span></strong></p></td>
</tr>
</tbody>
</table>
代码:
import requests from lxml import etree # 设置URL地址和请求头 url = 'http://admi.hnu.edu.cn/info/1024/3094.htm' headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.92 Safari/537.36', 'Cookie': 'ASP.NET_SessionId=yolmu555asckw145cetno0um' } # 发送请求并解析HTML对象 response = requests.get(url, headers=headers) html = etree.HTML(response.content.decode('utf-8')) # 数据解析 table = html.xpath("//table//tr[position()>2]") # XPath定位到表格,因为页面只有一个表格,所以直接//table, # 如果有多个表格,如取第二个表格,则写为//table[1] 偏移量为1 。我们不取表头信息,所以从tr[3]开始取,返回一个列表 dep = [] for i in table: # 遍历tr列表 p = ''.join(i.xpath(".//td[1]//text()")) # 获取当前tr标签下的第一个td标签,并用text()方法获取文本内容,赋值给p sl = ''.join(i.xpath(".//td[6]//text()")) sc = ''.join(i.xpath(".//td[9]//text()")) ll = ''.join(i.xpath(".//td[2]//text()")) lc = ''.join(i.xpath(".//td[5]//text()")) print(p, sl, sc, ll, lc) data = { # 用数据字典,存储需要的信息 '省份': ''.join(p.split()), # .split()方法在此处作用是除去p中多余的空格 'xa0' '理科一本线': ''.join(sl.split()), '理科投档线': ''.join(sc.split()), '文科一本线': ''.join(ll.split()), '文科投档线': ''.join(lc.split()) } print(data) dep.append(data) #数据存储 with open('2018enro.txt', 'w', encoding='utf-8') as out_file: out_file.write("湖南大学:"+"2018年各省录取分数线: ") for i in dep: out_file.write(str(i)+' ')
注:原本数据字典是这样写的:
for i in table: data = { # 用数据字典,存储需要的信息 '省份': ''.join(i.xpath(".//td[1]//text()")), '理科一本线': ''.join(i.xpath(".//td[6]//text()")), '理科投档线': ''.join(i.xpath(".//td[9]//text()")), '文科一本线': ''.join(i.xpath(".//td[2]//text()")), '文科投档线': ''.join(i.xpath(".//td[5]//text()")) }
输出结果有很多‘xa0’,其实就是空格,源网页中就字段里就存在很多空格:


plus:解析表格有更好的方法,比如pandas,一步到位!非常方便。
详情请看我的另一篇文章: