XML被设计为“什么都不做”,XML只用于组织、存储数据,除此之外的数据生成、读取、传送等等的操作都与XML本身无关!
XML语法:**<?xml version="1.0" encoding="utf-8" standalone="no"?>
- version:版本号
- encoding:编码
- standalone:yes/no 是否独立使用,默认 no
- 文档声明时,属性的位置不能变
元素:xml中的元素和标签指的是一个东西
注意:XML语法是规范的不能乱写
属性:XML元素的一部分,命名规范和元素一样
<!--属性名是name,属性值是china-->
<中国 name="china">
</中国>
注释和XML一样
CDATA:包裹的内容不会被解析,原封不动得输出*,语法:
<![CDATA[
...内容
]]>
处理指令(PI)用来只会解析引擎如何解析xml内容
如:<?xml-stylesheet type="text/css" href="1.css"?>使用xml-stylesheet指令,通知XML解析引擎,应用css文件显示xml文档内容
JDK中的XML API
- JAXP:负责解析XML
- JAXB:负责将XML映射为java对象
什么是XML解析
解析方式
- dom:文档对象模型
- sax:是XML社区的标准
解析操作
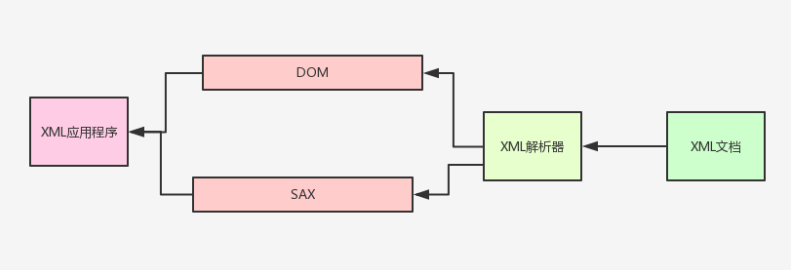
看出程序要访问XML文档的过程是先由解析器对文档进行分析,然后程序通过解析器所提供的DOM接口或SAX接口对分析结果进行操作,从而间接实现了对XML文档的访问
常用解析开发包
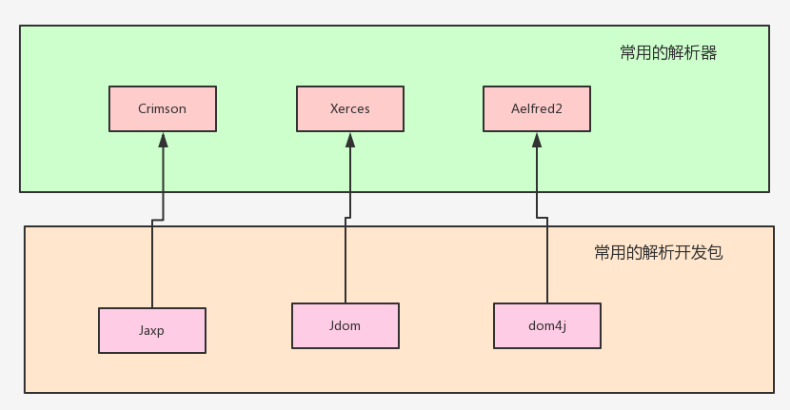
实际常用的是第三方解析,dom4j(对jdom进行了封装,他又对DOM进行了封装)
jaxp(JDK内置的开发包)
DOM解析操作
DOM解析是一个基于对象的API,它把XML的内容加载到内存中,生成与XML文档内容对应的模型!当解析完成,内存中会生成与XML文档的结构与之对应的DOM对象树,这样就能够根据树的结构,以节点的形式对文档进行操作!
简单来说:DOM解析会把XML文档加载到内存中,生成DOM树的元素都是以对象的形式存在,通过对象来操作XML文档,DOM树:
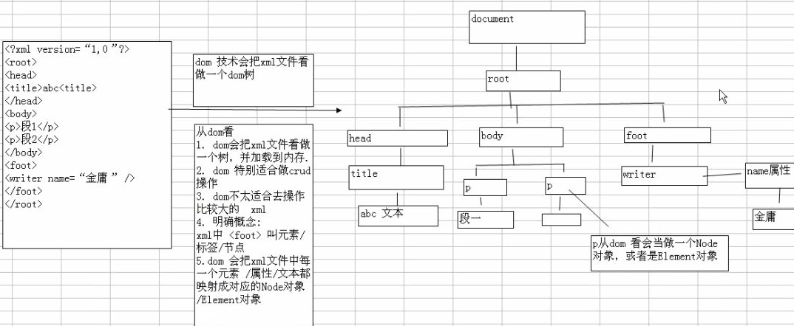
XML文档的数据时带有关系型的,所以上面的DOM存在父节点、子节点、兄弟节点、后代和祖先的关系
核心接口
- Document:代表整个XML文档(也可表示HTML文档),通过Document节点可以访问XML文件中所有的元素内容
- Node:Node节点在XML操作接口中相当于普通Java类的Object(XML接口中的爸爸),很多核心接口都实现了它
- NodeList:代表一个节点的集合,通常是一个节点中子节点的集合
- NameNodeMap:主要用于属性节点的表示,表示一组节点和其唯一的名称的对应关系
节点之间的关系:
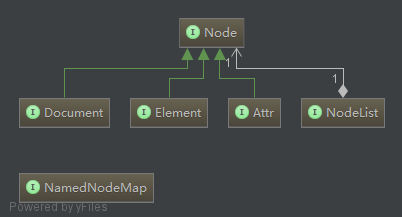
Document也实现了Node接口,一个Document由多个Node组成,这样看来Document本身也是一个Node,就像java中类也是一个对象
dom4j解析技术
基本操作
public void Test1() throws DocumentException {
// 第一步,通过创建SAXReader读取xml文件,获取Document对象
SAXReader reader = new SAXReader();
Document doc = reader.read("x.xml");
// 第二步,通过Document对象,拿到XML的根元素对象
Element root = doc.getRootElement();
// 第三步,通过根元素获取所有的book标签对象
//elements("标签名")它可以拿到当前元素下指定的子元素集合
//此参数不能使用最大的那个闭合标签
List<Element> list = root.elements("Person");
// 第四步,遍历每个book标签对象,然后获取到book标签对象内的一个元素
//element("标签名")获取指定的标签对象(就是Element元素对象)
//通过getText()方法拿到起始标签和结束标签之间的文本内容
for(Element e : list){
System.out.println(e.element("boy").getText());
//asXML()方法将元素对象转换成字符串形式
System.out.println(e.asXML());
System.out.println(e.element("boy").asXML());
//elementText就()方法直接获取标签内的文本内容
System.out.println(e.elementText("boy"));
}
}