最近可能又是闲着没事干了,就想做点东西,想着还没用JAVA弄过数据结构,之前搞过算法,就试着写写哈夫曼压缩了。
本以为半天就能写出来,结果,踩了无数坑,花了整整两天时间!!orz。。。不过这次踩坑,算是又了解了不少东西,更觉得在开发中学习是最快的了。
注:代码已上传至github:https://github.com/leo6033/Java_Project
话不多说,进入正题
首先先来讲讲哈夫曼树
哈夫曼树属于二叉树,即树的结点最多拥有2个孩子结点。若该二叉树带权路径长度达到最小,称这样的二叉树为最优二叉树,也称为哈夫曼树(Huffman Tree)。哈夫曼树是带权路径长度最短的树,权值较大的结点离根较近。

哈夫曼树的构造
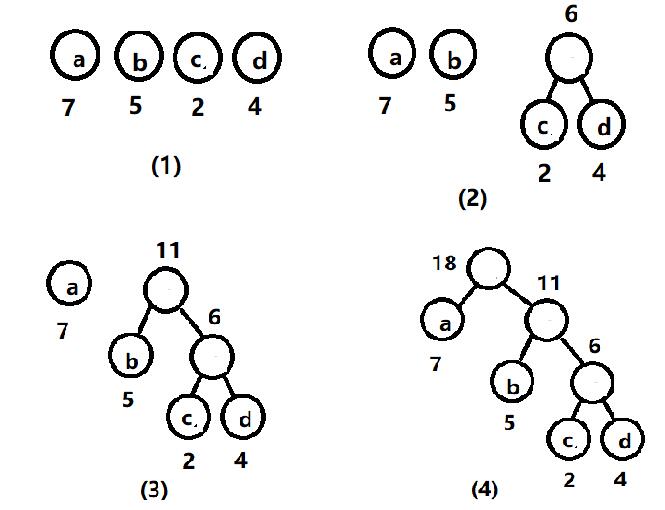
假设有n个权值,则构造出的哈夫曼树有n个叶子结点。 n个权值分别设为 w1、w2、…、wn,则哈夫曼树的构造规则为:
(1) 将w1、w2、…,wn看成是有n 棵树的森林(每棵树仅有一个结点);
(2) 在森林中选出两个根结点的权值最小的树合并,作为一棵新树的左、右子树,且新树的根结点权值为其左、右子树根结点权值之和;
(3)从森林中删除选取的两棵树,并将新树加入森林;
(4)重复(2)、(3)步,直到森林中只剩一棵树为止,该树即为所求得的哈夫曼树。
哈夫曼编码
在数据通信中,需要将传送的文字转换成二进制的字符串,用0,1码的不同排列来表示字符。例如,需传送的报文为“HELLO WORLD”,这里用到的字符集为“D,E,H,L,O,R,W”,各字母出现的次数为{1,1,1,3,2,1,1}。现要求为这些字母设计编码。要区别7个字母,最简单的二进制编码方式是等长编码,固定采用3位二进制,可分别用000、001、010、011、100、101、110对“D,E,H,L,O,R,W”进行编码发送,当对方接收报文时再按照三位一分进行译码。显然编码的长度取决报文中不同字符的个数。若报文中可能出现26个不同字符,则固定编码长度为5。然而,传送报文时总是希望总长度尽可能短。在实际应用中,各个字符的出现频度或使用次数是不相同的,如A、B、C的使用频率远远高于X、Y、Z,自然会想到设计编码时,让使用频率高的用短编码,使用频率低的用长编码,以优化整个报文编码。

此时D->0000 E->0001 W->001 H->110 R->111 L->01 0->02
固定三位时编码长度为30,而时候哈夫曼编码后,编码长度为27,很明显长度缩小了,得到优化。
下面就是代码实现
HuffmanCompress.java
package 哈夫曼; import java.io.DataInputStream; import java.io.DataOutputStream; import java.io.File; import java.io.FileInputStream; import java.io.FileNotFoundException; import java.io.FileOutputStream; import java.util.Arrays; import java.util.HashMap; import java.util.PriorityQueue; public class HuffmanCompress { private PriorityQueue<HufTree> queue = null; public void compress(File inputFile, File outputFile) { Compare cmp = new Compare(); queue = new PriorityQueue<HufTree>(12, cmp); // 映射字节及其对应的哈夫曼编码 HashMap<Byte, String> map = new HashMap<Byte, String>(); int i, char_kinds = 0; int char_tmp, file_len = 0; FileInputStream fis = null; FileOutputStream fos = null; DataOutputStream oos = null; HufTree root = new HufTree(); String code_buf = null; // 临时储存字符频度的数组 TmpNode[] tmp_nodes = new TmpNode[256]; for (i = 0; i < 256; i++) { tmp_nodes[i] = new TmpNode(); tmp_nodes[i].weight = 0; tmp_nodes[i].Byte = (byte) i; } try { fis = new FileInputStream(inputFile); fos = new FileOutputStream(outputFile); oos = new DataOutputStream(fos); /* * 统计字符频度,计算文件长度 */ while ((char_tmp = fis.read()) != -1) { tmp_nodes[char_tmp].weight++; file_len++; } fis.close(); // 排序,将频度为0的字节放在最后,同时计算除字节的种类,即有多少个不同的字节 Arrays.sort(tmp_nodes); for (i = 0; i < 256; i++) { if (tmp_nodes[i].weight == 0) { break; } HufTree tmp = new HufTree(); tmp.Byte = tmp_nodes[i].Byte; tmp.weight = tmp_nodes[i].weight; queue.add(tmp); } char_kinds = i; if (char_kinds == 1) { oos.writeInt(char_kinds); oos.writeByte(tmp_nodes[0].Byte); oos.writeInt(tmp_nodes[0].weight); } else { // 建树 createTree(queue); root = queue.peek(); // 生成哈夫曼编码 hufCode(root, "", map); // 写入字节种类 oos.writeInt(char_kinds); for (i = 0; i < char_kinds; i++) { oos.writeByte(tmp_nodes[i].Byte); oos.writeInt(tmp_nodes[i].weight); } oos.writeInt(file_len); fis = new FileInputStream(inputFile); code_buf = ""; while ((char_tmp = fis.read()) != -1) { code_buf += map.get((byte) char_tmp); while (code_buf.length() >= 8) { char_tmp = 0; for (i = 0; i < 8; i++) { char_tmp <<= 1; if (code_buf.charAt(i) == '1') char_tmp |= 1; } oos.writeByte((byte) char_tmp); code_buf = code_buf.substring(8); } } // 最后编码长度不够8位的时候,用0补齐 if (code_buf.length() > 0) { char_tmp = 0; for (i = 0; i < code_buf.length(); ++i) { char_tmp <<= 1; if (code_buf.charAt(i) == '1') char_tmp |= 1; } char_tmp <<= (8 - code_buf.length()); oos.writeByte((byte) char_tmp); } oos.close(); fis.close(); } } catch (Exception e) { // TODO Auto-generated catch block e.printStackTrace(); } } public void extract(File inputFile, File outputFile) { Compare cmp = new Compare(); queue = new PriorityQueue<HufTree>(12, cmp); int i; int file_len = 0; int writen_len = 0; FileInputStream fis = null; FileOutputStream fos = null; DataInputStream ois = null; int char_kinds = 0; HufTree root=new HufTree(); byte code_tmp; try { fis = new FileInputStream(inputFile); ois = new DataInputStream(fis); fos = new FileOutputStream(outputFile); char_kinds = ois.readInt(); // 字节只有一种 if (char_kinds == 1) { code_tmp = ois.readByte(); file_len = ois.readInt(); while ((file_len--) != 0) { fos.write(code_tmp); } } else { for (i = 0; i < char_kinds; i++) { HufTree tmp = new HufTree(); tmp.Byte = ois.readByte(); tmp.weight = ois.readInt(); System.out.println("Byte: "+tmp.Byte+" weight: "+tmp.weight); queue.add(tmp); } createTree(queue); file_len = ois.readInt(); root = queue.peek(); while (true) { code_tmp = ois.readByte(); for (i = 0; i < 8; i++) {
//这里为什么是&128呢?
//我们是按编码顺序走的,1向右,0向左,对于一串byte编码有8位,那最高位就是2^7,就是128
//所以通过位运算来判断该位是0还是1
//之前我想错了,从后面开始走,结果乱码,压缩在这块也卡了好久orz
if ((code_tmp&128)==128) { root = root.rchild; } else { root = root.lchild; } if (root.lchild == null && root.rchild == null) { fos.write(root.Byte); ++writen_len; if (writen_len == file_len) break; root = queue.peek(); } code_tmp <<= 1; } if (writen_len == file_len) break; } } fis.close(); fos.close(); } catch (Exception e) { // TODO Auto-generated catch block e.printStackTrace(); } } public void createTree(PriorityQueue<HufTree> queue) { while (queue.size() > 1) { HufTree min1 = queue.poll(); HufTree min2 = queue.poll(); System.out.print(min1.weight + " " + min2.weight + " "); HufTree NodeParent = new HufTree(); NodeParent.weight = min1.weight + min2.weight; NodeParent.lchild = min1; NodeParent.rchild = min2; queue.add(NodeParent); } } public void hufCode(HufTree root, String s, HashMap<Byte, String> map) { if (root.lchild == null && root.rchild == null) { root.code = s; System.out.println("节点" + root.Byte + "编码" + s); map.put(root.Byte, root.code); return; } if (root.lchild != null) { hufCode(root.lchild, s + '0', map); } if (root.rchild != null) { hufCode(root.rchild, s + '1', map); } } }
Compare.java
package 哈夫曼; import java.util.Comparator; public class Compare implements Comparator<HufTree>{ @Override public int compare(HufTree o1, HufTree o2) { if(o1.weight < o2.weight) return -1; else if(o1.weight > o2.weight) return 1; return 0; } }
这里涉及到JAVA中优先对列的重载排序,我之前一直按照C++中的重载来写,结果发现发现压缩后的大小是原文件的3倍!!!!然后还一直以为是压缩过程的问题,疯狂看压缩过程哪里错了,最后输出了下各字符的编码才发现问题,耗了我整整一天TAT。。附上一个对优先队列重载讲解的链接https://blog.csdn.net/u013066244/article/details/78997869
HufTree.java
package 哈夫曼; public class HufTree{ public byte Byte; //以8位为单元的字节 public int weight;//该字节在文件中出现的次数 public String code; //对应的哈夫曼编码 public HufTree lchild,rchild; } //统计字符频度的临时节点 class TmpNode implements Comparable<TmpNode>{ public byte Byte; public int weight; @Override public int compareTo(TmpNode arg0) { if(this.weight < arg0.weight) return 1; else if(this.weight > arg0.weight) return -1; return 0; } }
test.java
package 哈夫曼; import java.io.File; public class test { public static void main(String[] args) { // TODO Auto-generated method stub HuffmanCompress sample = new HuffmanCompress(); // File inputFile = new File("C:\Users\long452a\Desktop\opencv链接文档.txt"); // File outputFile = new File("C:\Users\long452a\Desktop\opencv链接文档.rar"); // sample.compress(inputFile, outputFile); File inputFile = new File("C:\Users\long452a\Desktop\opencv链接文档.rar"); File outputFile = new File("C:\Users\long452a\Desktop\opencv链接文档1.txt"); sample.extract(inputFile, outputFile); } }