前言:前段时间在网上看到腾讯后台开发总监bison分享的一篇文章《浅谈过载保护》,读来受益匪浅。
刚好自己也在处理系统请求过载的问题,把自己的一些心得体会总结出来拿来与大家一起探讨。
在bison的文章中谈到:对于延时敏感的服务,当外部请求超过系统处理能力,如果系统没有做相
应保护,可能导致历史累计的超时请求达到一定的规模,像雪球一样形成恶性循环,由于系统处理的每个
请求都因为超时而无效,系统对外呈现的服务能力为0,且这种情况不能自动恢复。我们的系统就是要尽
量避免这种情况的出现,下面将详细来分析一个现实中的案例。
一 有过载问题的系统

数据处理流程:
1) 前端将请求发送给数据解析及转发系统,
2)数据解析及转发系统将封装好的数据发送后台数据请求,设置超时时间(假设300ms),线程同步等待处
理结果从后台返回。
3)在300ms内正确返回结果后,则将处理的结果返回给前端,如果在300ms内超时,则将数据发送到一次超
时处理系统(假设设置超时时间500ms),线程同步等待结果返回。
4)在500ms内正确返回结果后,则将处理的结果返回给前端,如果再一次超时,返回一个默认的处理结果给前
端,后端对数据进行本地化,然后可以将数据发送到离线处理系统进行二次处理。
数据解析的机器为多核,数据解析及转发系统采用的是单进程多线程模型,在前一篇文章《海量数据处理系列
之Java线程池使用》详细描述了多线程处理的实现,采取的是无界队列线程池的实现,这样从客户端来的请求,会被
这样处理:
1) 如果线程池中有空闲线程,会将请求直接交给线程处理。
2) 如果没有空闲线程,就将请求保存到任务队列。
假设开50个线程,每个线程秒平均处理一个请求,那么系统每秒可以处理的最大请求数是50个。一旦前端数据请求超
过50个每秒,在任务队列中将会堆积大量的请求,前台不断发送过来,后来处理不过来,前端又设置了套接字超时,导
致队列中的大量请求超时,直接使得后端线程从队列中取出套接字解析的时候,套接字已经被前台关闭了,引发I/O异常。
堆积的量一旦雪崩,将使前台发送过来的请求全部I/O异常,后台处理系统跟挂掉无异了。
二 相对完善的系统
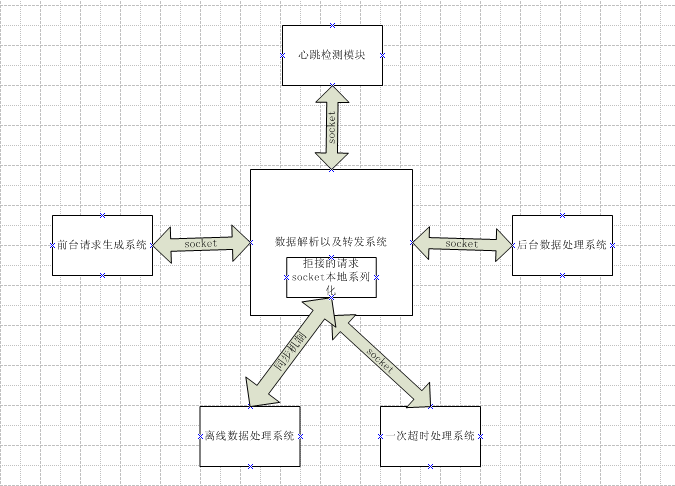
在上面的系统中,对请求是来者不拒的状态,具体来讲就是将所有的请求都保存到任务队列。请求堆积到一定程度,
队列中的很多请求都超时,这是可以采取清空请求队列的方式,这个可以通过采取一定的监控方式来实现。例如上图
中的心跳监控模块,它可以通过这样的方式来实现,就是模拟客户端的请求,每隔一定时间发送一些请求过去,如果
有大部分都正常返回,说明后端处理系统正常;当出现大部分超时的时候,说明后台系统已经挂掉了,这时候重启数
据解析及转发系统,清空系统中的任务请求队列,这样可以暂时处理请求高峰期的情况。
但是这个方式也是治标不治本的,后台最多只能处理这么多请求,重启后照样会导致大量堵塞导致系统又挂掉,
然后监控系统又重启,这样会使得很多的请求没有得到有效的处理,大大降低系统的处理能力。为了保证后台系统每
时每刻都最大限度的发挥自己的处理能力,当负载超过系统自身的处理能力时,拒绝该请求。拒绝后可以将该请求本
地系列化,保存相关的数据发送到离线数据处理系统进行处理。
在前一篇文章《海量数据处理系列之Java线程池使用》第四节中有界队列线程池使用中有提到这种方式的具体实现。
以上面的系统为例,有界线程池可以这样配置,corePoolSize为30,maximumPoolSize为50,有界队列为
ArrayBlockingQueue<Runnable>(100)。
这样系统在处理请求的时候采用如下策略:
1) 当一个请求过来,线程池开启一个线程来处理,直到30个线程都在处理请求。
2) 当线程池中没有空闲线程了,就将请求添加到有界队列当中,直到队列满为止。
3) 当队列满以后,在开启线程来处理新的请求,直到开启的线程数达到maximumPoolSize。
4) 当开启的线程数达到maximumPoolSize后,任务队列又已经满了后,此时再过来的请求将被拒绝,被拒绝的请求
在本地系列化,将保存的数据同步到离线数据系统进行处理。
海量数据处理都是采用分布式的,每台机器的处理能力有限,可以将请求分布到不同的机器上去。如果每台机器被
拒绝的请求数过多的时候,就要考虑添加处理的机器了。
参考文献:
1. Bison《浅谈过载保护》http://djt.qq.com/article-156-1.html