作者:Syn良子 出处:http://www.cnblogs.com/cssdongl 欢迎转载
抽空用kettle配置了一个Mapreduce的Word count,发现还是很方便快捷的,废话不多说,进入正题.
一.创建Mapper转换
如下图,mapper读取hdfs输入,进行word的切分,输出每个word和整数常量值
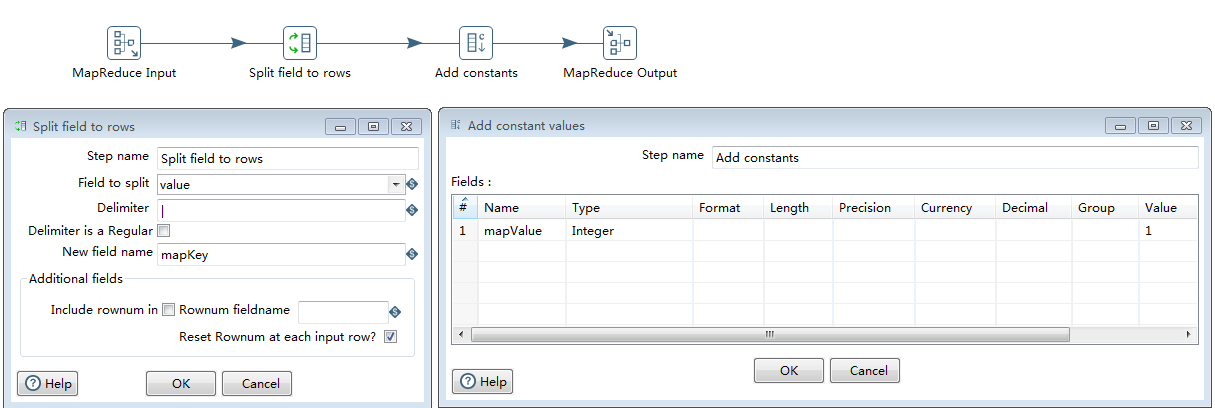
1>MapReduce Input:Mapper输入,读取HDFS上的输入文件内容以键值对存储;
2>Spit filed to rows:读取value值以分隔符 "|" 进行切分(注意我这里hdfs文件中的word是以"|"隔开的)
3>Add constants:给每次出现的word追加一个常量字段mapValue,值为整数1.
4>MapReduce Output:Mapper输出,key为每个word,这里为mapKey,value为常量值mapValue.
二.创建Reducer转换
如下图,Reducer读取mapper的输出.按照每个key值进行分组,对相应的常量值字段进行聚合,这里是做sum,然后最终输出到hdfs文件中去.
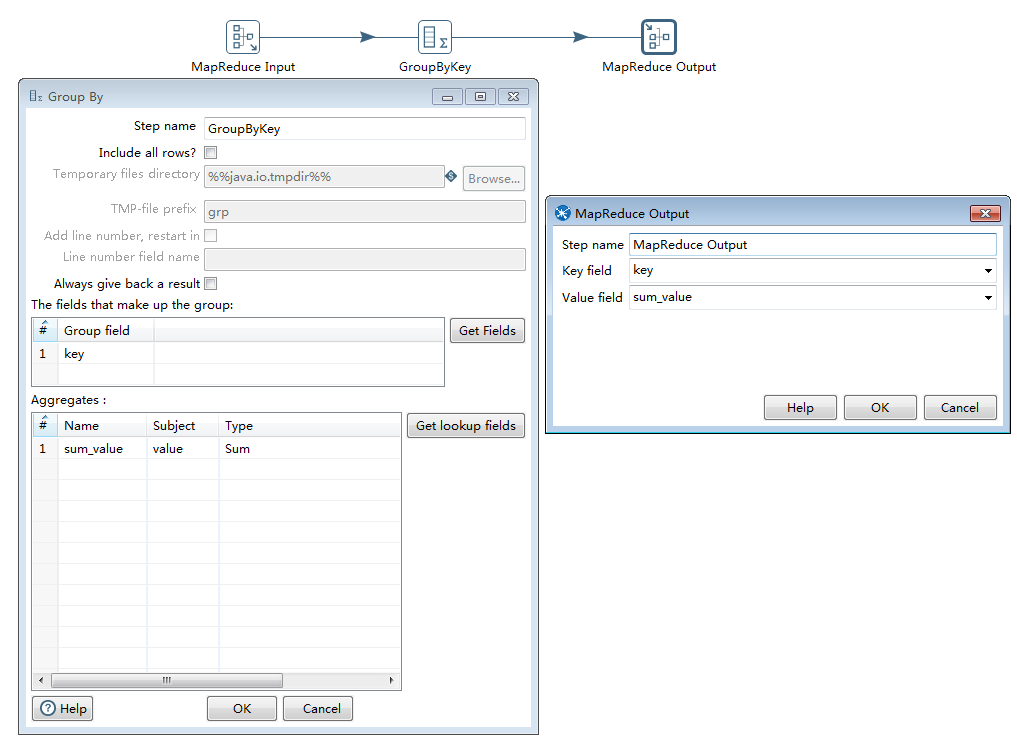
1>MapReduce input:读取Mapper中的输出作为Reducer的输入
2>GroupByKey:按照key进行分组(这里key是每个word), 然后对value进行聚合sum,求出每个word出现的总次数;
3>MapReduce Output:最终的键值对,每行以<单词,总次数>来输出到hdfs上去.
三.创建MapReduce Job.
创建最终的MapReduce Job,配置相应参数,调用Mapper和Reducer,见下图
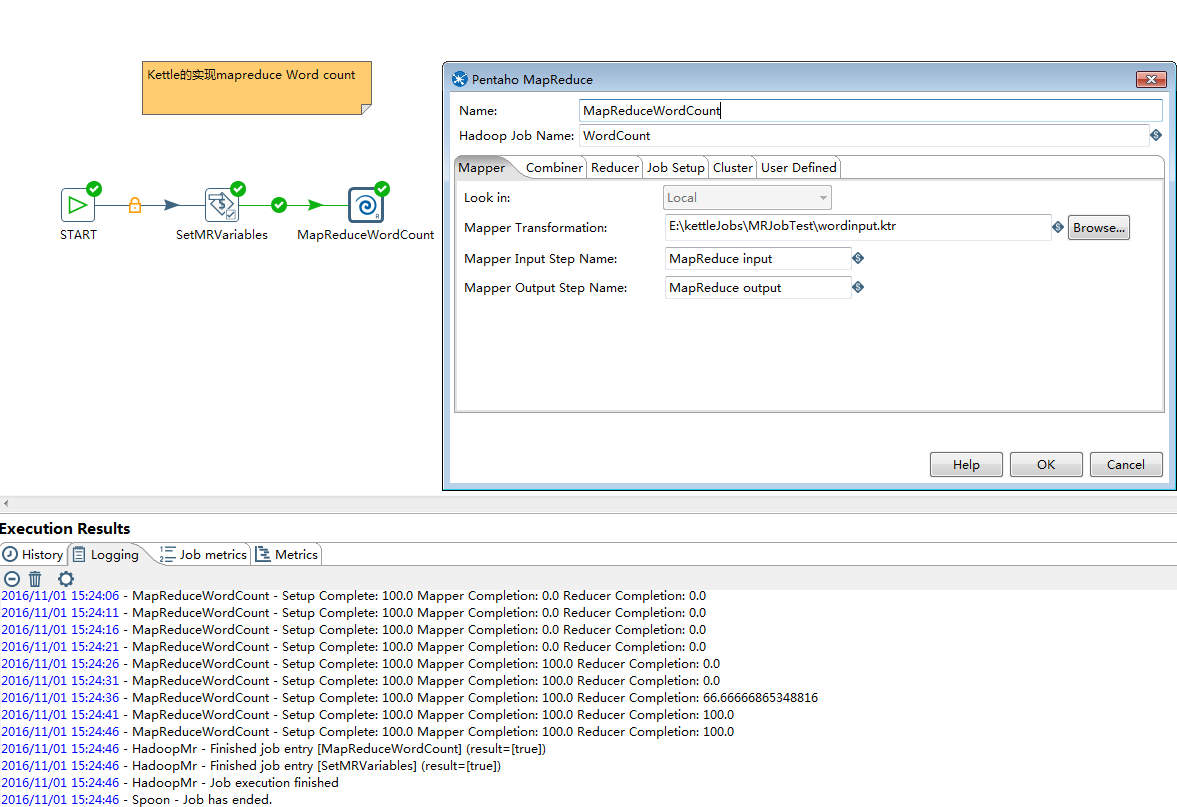
1>START:表示job的开始
2>SetMRVariables:组件是set variables,用于设置一些MapReduce执行所需要的参数的全局变量值,如hdfs input path等;
3>MapReduceWordCount:组件是Pentaho MapReduce组件,用来配置需要调用的Mapper和Reducer以及集群相关信息.
以上配置好以后执行MapReduce Job,会提交至Hadoop集群并运行成功,如上图,可以同时看到MapReduce的执行进度。
鉴于kettle能对字段做各种切分,组合以及正则等处理,还可以自定义java class,所以基本的MR程序都可以快速配置出来.
以上配置的Job下载链接:http://files.cnblogs.com/files/cssdongl/MRJobTest.7z
参考资料:http://wiki.pentaho.com/display/BAD/Understanding+How+Pentaho+works+with+Hadoop