第三章 PE头文件
本章是全书重点,所以要好好理解,概念比较多,但是非常重要。
PE头文件记录了PE文件中所有的数据的组织方式,它类似于一本书的目录,通过目录我们可以快速定位到某个具体的章节;通过PE文件头部分对某些数据结构的描述,我们也可以定位到那些不在头文件部的信息,比如导入表数据、导出表数据、资源表数据等。
3.1 PE的数据组织方式
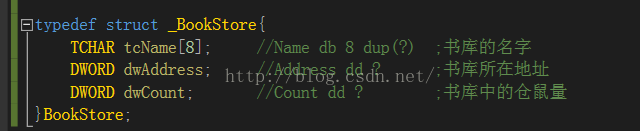
这一节说了很多,举了两个例子,分别是图书馆存书1和图书馆存书2,细节我不介绍了,是基本的数据结构应用,没有难点。最后说PE数据组织方式类似于存书2的例子。那么说下存书2的例子:
为了方便图书馆更好的管理书籍(为了方便查找),我们可以定义两个数据结构,一个是BookStore,另一个是Book。(书中都是用汇编写的,我用C++翻译一下吧,方便看)。
BOOKSTORE
BOOK

找书的时候,我们可以通过BookStore遍历书库位置中的所有书找到存储指定的书的信息的变量的地址(某个Book地址),然后我们在根据这个地址找到Book结构,然后再根据这个结构去找到这本书。
对应的结构图
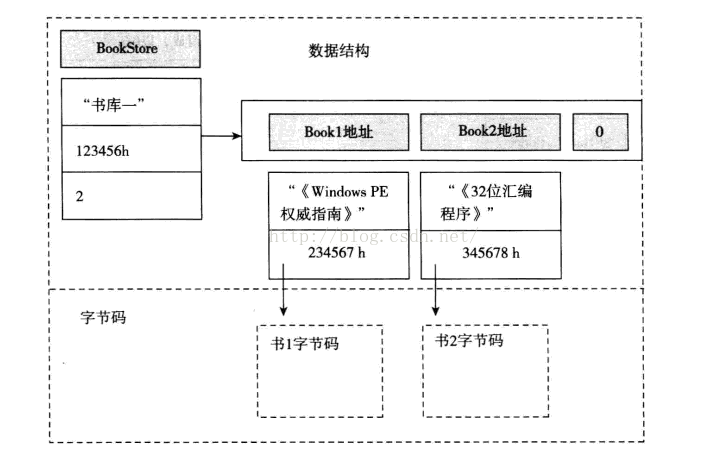
PE文件结构基本采用了类似的阻止方式。
3.2 与PE有关的基本概念
在详细了解PE文件结构之前,先学习几个基本概念。
3.2.1 地址
PE中设计的地址有四类,它们分别是:
1.虚拟内存地址(VA)
2.相对虚拟内存地址(RVA)
3.文件偏移地址(FOA)
4.特殊地址
要想了解这些概念,需要先简单了解一下32位环境下Windows对内存的管理,以及分页机制的原理。(这个地方请自行百度补脑)。
1.虚拟内存地址
用户的PE文件被操作系统加载进内存后,PE对应的进程支配了自己独立的4GB虚拟空间。在这个空间中定位的地址称为虚拟内存地址(Virtual Address,VA),所以虚拟内存地址的范围是00000000h~ffffffffh。在PE中,进程本身的VA被解释为:VA=进程的基地址+相对偏移内存地址。
2.相对虚拟内存地址
一个进程被操作系统加载到虚拟内存空间后,其相关的动态链接库也会被加载。这些同时加载到进程地址空间的文件被称为模块。每个模块在加载时都会有一个基址,也就是预先告操作系统:它会占用4GB空间的哪个部分(即从哪里开始存储该模块)。不同模块的基地址一般不一样,如果两个模块的基地址相同,就由操作系统决定这两个模块在虚拟空间中的具体位置。
相对虚拟内存地址(Reverse Virtual Address ,RVA)是相对于基地址的偏移,即RVA是虚拟内存中用来定位某个特定位置的地址,该地址的值是这个特定位置距离某个模块基地址的偏移量,所以说RVA是针对某个模块而存在的。
关于VA和RVA的概念,如下图:

上图假设模块2的基地址为0x01000000,而模块2中的某个位置距离模块2的基地址偏移为400h,那么值0x00000400就是模块2中某个位置的RVA,而值0x01000400是该位置的VA。记住,RVA是相对于模块而言的,VA是相对于整个地址空间而言的。[RVA与具体模块相关,它有一个范围,该范围从模块的开始到结束,脱离这个范围的RVA是无效的,称为越界。越界的RVA地址没有任何意义。]
3.文件偏移地址
文件偏移地址(File Offset Address,FOA)和内存无关,它是只某个位置距离文件头的偏移。
4.特殊地址
在PE结构中海油一种特殊地址,其计算方法并不是从文件头算起,也不是从内存的某个模块的基地址算起,而是从某个特定的位置算起。这种地址在PE结构中很少见,如在资源列表里出现过这样的地址。
3.2.2 指针
PE数据结构中的指针的定义:如果数据结构中某个字段存储的值为一个地址,那么这个字段就是一个指针。
3.2.3 数据目录
Windows下的可执行文件是PE中的一种,这种文件出了包含代码及数据段的相关数据以外,还包含许多与文件执行有关的其他数据,比如引用外部函数的信息、PE程序的图标、内部到处函数等,这些数据可能会随着操作系统的新特性出现而增加。
PE中有一个数据结构成为数据目录,其中记录了所有可能的数据类型。这些类型中,目前已定义的有15种,包括导出表、导入、资源表、异常表、属性证书表、重定位表、调试数据、Architecture、Global Ptr 、线程局部存储、加载配置表、绑定导入表、IAT、延迟导入表和CLR运行时头部。
3.2.4 节
无论是结构化程序设计,还是面向对象程序设计,都抵偿数据与程序独立性,因此,程序中的代码和数据通常是分开存放的。为了保证程序执行的安全,保障内核的稳定,Windows操作系统通常对不同用途的数据设置不同的访问权限。比如,代码段中的字节码在程序运行的时候,一般不允许用户进行修改,数据段则允许在程序运行过程中读和写,常量只能读等。Windows操作系统在加载可执行程序时,会为这些具有不同属性的数据分配标记有不同属性的页面(当然,相同属性的数据可能会被放到同一个页面中),以确保程序运行时的安全。正式基于这个原因,PE中才错线了所谓的节的概念。
节就是存放不同类型数据(比如代码、数据、常量、资源等)的地方,不同的节具有不同的访问权限。节是PE文件中存放代码或数据的基本单元。例如,一个目标文件中的所有代码可以组合成单个节,或者每个函数单独占一个节(如果编译器行为允许)。增加节的数目会增加文件的开销,但是链接器在链接代码时会有更大的选择余地。一个节中的所有原始数据必须被加载到连续的内存空间中。
从操作系统加载角度来看,节是相同属性的组合。与数据目录不同的是,尽管有些数据类型不同,分别属于不同的数据目录,但由于其访问属性相同,便被归类到同一个节中。这个节最终可能会占用一个或多个页面;但无论多少个,所有相关页面均会被赋予相同的页属性。这些属性包括只读、只写、可读、可写等。
汇编语言中以‘.’开头的一些伪指令其实就是在声明不同数据类型。比如.data声明的是初始化的数据,.data ? 声明的是未初始化的数据,.code声明的是可执行的代码等。Windows操作系统在装载PE文件时会对这些数据执行抛弃、合并、新增、复制等操作。这些不同的操作交叉组合导致了内存的节和文件的节会出现很大的不同。例如.data?的数据在磁盘中不存在,但在内存中存在,。reloc重定位表数据却恰恰相反。
3.2.5 对齐
对齐这个概念并非只是在PE结构冲出现,许多文件格式都会有对齐的要求。有的对齐是为了美观,有的对齐是为了效率。PE中规定了三类对齐:数据在内存中对齐、数据在文件中对齐、资源文件中资源数据的对齐。
1.内存对齐
由于Windows操作系统对内存属性的设置以页为单位,所以通常情况下,节在内存中的对齐单位必须至少是一个页的大小。对32位的系统来说是4KB(1000h),而对于64位操作系统来说,这个值就是8KB(2000h)。
2.文件对齐
相对来说,节在磁盘文件中的对齐尺寸没有那么严格。为了提高磁盘利用率,通常情况下,定义的节在文件中的对齐单位要远小于内存对齐的单位;通常会以一个屋里扇区的大小作文对齐粒度的值,即512字节,十进制表示为200h。这就是我们在第一章中看到的数据段、代码段等其实地址都是200h的倍数的原因了。
出于节约资源的考虑,操作系统允许节在内存和文件中的对齐尺寸不一致。这就直接造成了PE在文件中和在内存中的大小也会不一致。通常情况下,PE在内存中的尺寸要比文件的尺寸大。用户可以自己定义这些对齐的值。
[如果内存对齐被定义为小于操作系统页的大小,则文件对齐和内存对齐的值必须一致!]
3.资源数据对齐
资源文件中,资源字节码部分一般要求以(4个字节)方式对齐,在资源表部分(详见7章)我们会详细解释。
3.2.6 Unicode字符串
基本概念,略,请自行百度。
本书的所有程序都使用一个字节来表示字符串中的字符,称为ACSI字符串。PE格式中设计字符串的部分云彩用ANSI字符串。然而在资源表中,对菜单名、对话框标题等的表述则全部使用Unicode字符串。所以,在读取这些资源的字符串时,首先要使用一些API进行转换。

3.3 PE文件结构
PE经历了从16位系统到32位系统的过渡,因此,32位系统下的每一个PE文件都可以在16位系统下运行。尽管PE文件的结构一样,但从不同的角度来看其结构的划分却并不一样。
3.3.1 16位系统下的PE结构
DOS头部分的存在见证了PE的强大兼容性。为了保持与16位系统的兼容,在PE里依旧保留了16位系统下的标准可执行程序执行时所必须的文件头部(DOS MZ头)和指令代码(DOS Stub)。
在16位系统下,PE结构可以大致分为两部分:DOS头和荣誉数据:

如上图所示,在16位系统下,PE的四部分内容被重新组合成两部分-可以在16位系统下运行的DOS头和冗余数据。把Windows下的PE文件存储到DOS系统并运行,它就是DOS系统下的一个EXE文件。
DOS头分为两部分,DOS MZ头和DOS Stub(即指令字节码)。大部分情况下,这些指令实现的功能都非常简单,根本不会涉及到重定位信息。在往后的PE头和PE数据去可以看做是16位系统下的可执行文件的冗余数据。
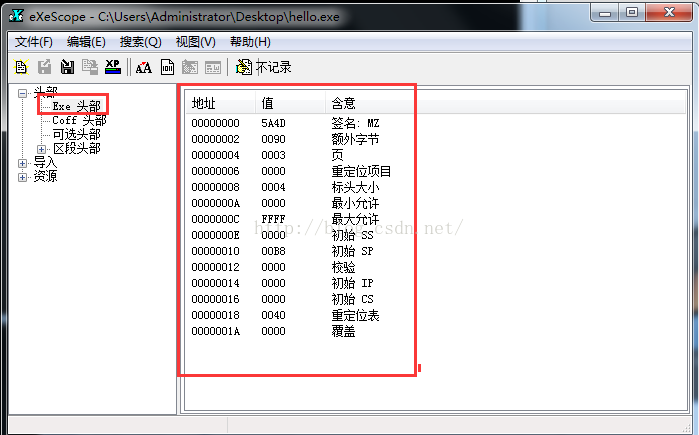
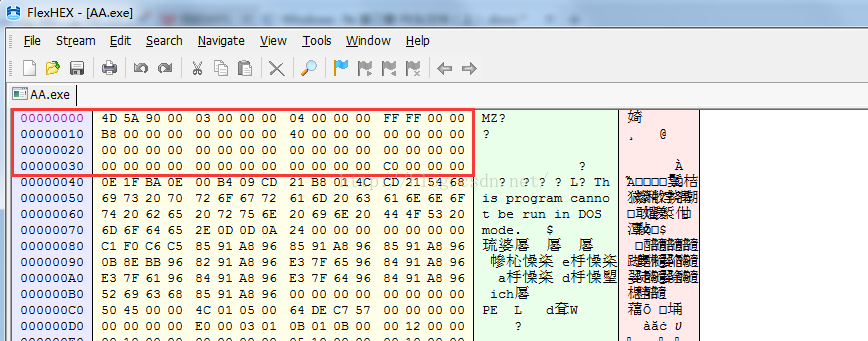
1.DOS MZ头
在Windows的PE格式中,DOS MZ头的定义如下:

如上所示,加粗部分在16位系统下是没有定义的。由于其开始的标志为“MZ”,所以称它为DOS
MZ 头。
2.DOS Stub
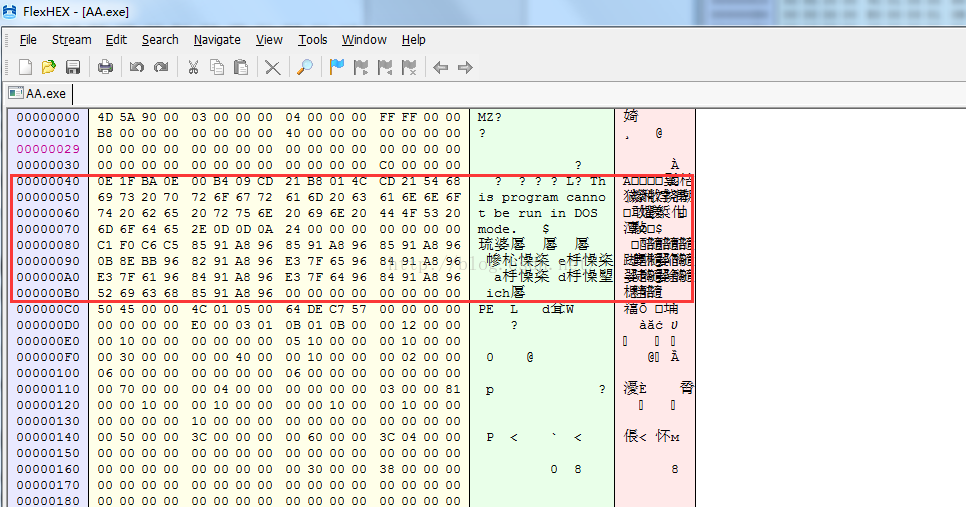
由于DOS Stub的大小不固定,因此DOS头的大小也是不固定的。DOS Stue部分是该程序在DOS系统下运行的指令字节码。
3.3.2 32位系统下的PE结构
在16位系统中,PE头和PE数据部分被当成是用于数据;在32位系统中,刚好相反,即DOS头称为冗余数据。所谓冗余,是针对DOS头不参与32位系统运行过程而言的。尽管该部分不参与运行,但是也不能把这些数据从PE结构中出去。因为在DOS MZ头中有一个字段非常重要,即IMAGE_DOS_HEADER.e_ifanew,如果没有它操作系统就定位不到标准的PE头部,可执行程序也就会被操作系统认为是非法的PE映像。
1.定位标准PE头
由于DOS Stub的长度不固定,导致了DOS头也不是一个固定大小的数据结构,那么,在Windows PE中,既然把DOS头放在了PE的起始位置,如何去定位后面的标准PE头所在的位置呢?字段e_ifanew即起这个作用。该字段的值是一个相对偏移量,绝对定位时需要增加上DOS MZ 头的基地址。也就是说,通过以下公式可以得出PE头的绝对位置:
PE_start=DOS MZ基地址+IMAGE_DOS_HEADER.e_ifanew
该节是以PE开头的。

2.PE文件结构
在32位系统下,最重要的部分就是PE头和PE数据区。随着讲解不断深入,下图也会被不断第细化和丰富。
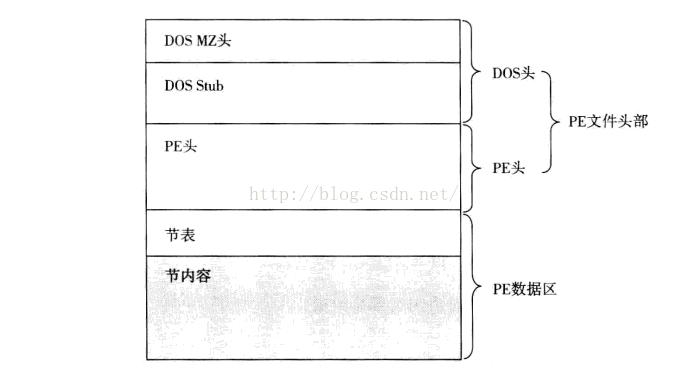
如上图所示,32位系统下的PE文件结构被划分为5个部分,包括:
DOS MZ头、DOS Stue 、PE头 、节表和节内容。
节表和节内容两部分其实就是之前图中所示的PE数据区。DOS MZ头的大小是64个字节,PE头的大小是456个字节(由于数据目录项不一定是16个,所以准确地说,PE头也是一个不能确定大小的结构,该结构的实际大小由字段IMAGE_FILE_HEADER.SizeOfOptionalHeader来确定)。节表的大小之所以不固定,是因为每个PE中节的数量是不固定的。每个节的表述信息则是个固定值,共40个字节,节表是有不确定数量的节表述信息组成的,其大小等于节的数量*40,节的数量字段IMAGE_FILE_HEADER.NumberOfSections来定义。DOS Stue和节内同都是大小不确定的。
节表是PE中所有节的目的,每个目录都是一个BookStore,其字节码就是节内容。它按照目录里的指针指向的地址,分别将节的字节码放在文件空间中排列起来,从而组成了一个完整的PE文件。PE文件头部等于DPS头+PE头。
3.3.3 程序员眼中的PE结构
在程序员眼中,PE文件格式是有许多数据结构组成的,数据结构是一系列有组织的数据的集合:

如图所示,一个标准的PE文件一般有四大部分组成:
DOS头
PE头(IMAGE_NT_HEADERS)
节表(多个IMAGE_SECTION_HEADER结构)
节内容
其中,PE头的数据结构最为复杂。简单来说,PE头包含:
4个字节的表示符号(Signature)
20个字节的基本头信息(IMAGE_FILE_HEADER)
216个字节的扩展头信息(IMAGE_OPTIONAL_HEADER32)
[
PE文件头部=DOS头+PE头+节表
PE文件身体=节内容
]
节内容中会出现各种不同的数据结构,如导入表、导出表、资源表、重定位表等。这些后续介绍。