目录
requests
requests库是 python中非常优秀的第三方库(python2和python3中均有requests库),它使用 Apache2 Licensed 许可证的 HTTP 库,用 Python 编写。requests 使用的是 urllib3(python3.x中的urllib),因此继承了它的所有特性。Requests 会自动实现持久连接keep-alive,requests 支持 HTTP 连接保持和连接池,支持使用 cookie 保持会话,支持文件上传,支持自动确定响应内容的编码,支持国际化的 URL 和 POST 数据自动编码,现代、国际化、人性化。
Requests库中有7个主要的函数,分别是 request() 、get() 、 head() 、post() 、put() 、patch() 、delete() 。这七个函数中request()函数是其余六个函数的基础函数,其余六个函数的实现都是通过调用该函数实现的。
| 方法 | 说明 |
|---|---|
| requests.request() | 构造一个请求,支撑一下方法的基础方法 |
| requests.get() | 获取HTML网页的主要方法,对应于HTTP的GET(请求URL位置的资源) |
| requests.head() | 获取HTML网页头信息的方法,对应于HTTP的HEAD(请求URL位置的资源的头部信息) |
| requests.post() | 向HTML网页提交POST请求的方法,对应于HTTP的POST(请求向URL位置的资源附加新的数据) |
| requests.put() | 向HTML网页提交PUT请求的方法,对应于HTTP的PUT(请求向URL位置储存一个资源,覆盖原来URL位置的资源) |
| requests.patch() | 向HTML网页提交局部修改的请求,对应于HTTP的PATCH(请求局部更新URL位置的资源) |
| requests.delete() | 向HTML网页提交删除请求,对应于HTTP的DELETE(请求删除URL位置储存的资源) |
而这几个函数中,最常用的又是 requests.get() 函数。get函数有很多的参数,我只举几个比较常用的参数
| 参数 | 说明 |
|---|---|
| url | 这个不用多说,就是网站的url |
| params | 将字典或字节序列,作为参数添加到url中,get形式的参数 |
| data | 将字典或字节序列,作为参数添加到url中,post形式的参数 |
| headers | 请求头,可以修改User-Agent等参数 |
| timeout | 超时时间 |
| proxies | 设置代理 |
举例:
import requests
##设置请求头
header = { 'Host': 'www.baidu.com',
'User-Agent' : 'Mozilla/4.0 (compatible; MSIE 5.5; Windows NT)',
'Referer' : 'http://www.baidu.com/login/',
'Accept' : '*/*' }
##设置提交的数据
values = {'name': 'Tom',
'sex' : 'Man',
'id' : '10' }
##设置代理
proxy={"http":"http://127.0.0.1:8080"}
##请求的url
requrl="http://www.baidu.com"
#使用session保持会话请求
sess=requests.session()
regu=sess.get("https://www.baidu.com")
#GET请求
response=requests.get(url=requrl,params=values,headers=header,timeout=0.1,proxies=proxy)
#POST请求
response=requests.post(url=requrl,data=values,headers=header,timeout=0.1,proxies=proxy)
响应内容的处理
import requests
import urllib
value={'username':'admin',
'password':'123' }
res=requests.get("http://www.baidu.com",params=value) //Get形式提交参数
data=urllib.parse.urlencode(value)
res=requests.get("http://www.baidu.com",data=data) //post形式提交参数
res.encoding="utf-8" #设置编码
res.status_code #状态码
res.url #请求的url
res.request.headers #请求头信息,返回的是一个字典对象,不修改的话,默认是python的请求头
res.headers #响应头信息,返回的是一个字典对象
res.headers['Content-Type'] #响应头的具体的某个属性的信息
res.cookies #cookie信息,返回的是一个字典对象
print(';'.join(['='.join(item)for item in cookies.items()])) #打印出具体的cookies信息
res.text #响应内容的字符串形式,即返回的页面内容
res.content #响应内容的二进制形式
res.apparent_encoding #从内容中分析出的响应内容编码方式(备选编码方式)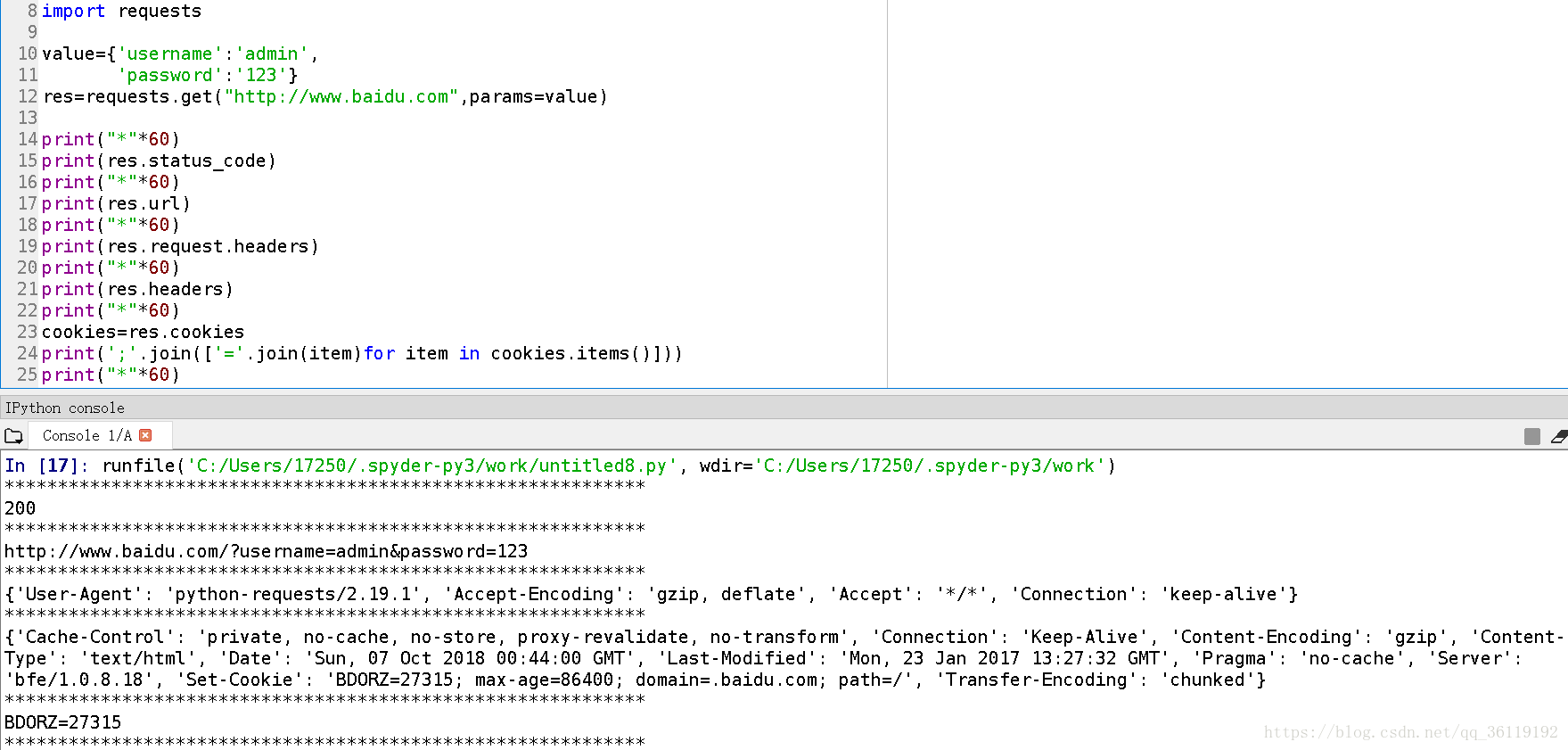
requests异常的处理
注意 requests 库有时会产生异常,比如网络连接错误、http错误异常、重定向异常、请求url超时异常等等。所以我们需要判断r.status_codes 是否是200,在这里我们怎么样去捕捉异常呢?
这里我们可以利用 response.raise_for_status() 语句去捕捉异常,该语句在方法内部判断r.status_code是否等于200,如果不等于,则抛出异常。
于是在这里我们有一个爬取网页的通用代码框架:
try:
response=requests.get(url)
response.raise_for_status() #如果状态不是200,则引发异常
except:
print("产生异常")