对于前端展现来说,如果一个页面中需要展现的数据条数过多,就必须设计分页查询功能,最常见的做法是采用pageIndex和pageSize参数来一页一页的拉取数据。然而实际的业务情况往往要复杂的多,一旦在分页过程中,原有数据的条数或者排序发生变化,就无法按照原有的页码获得相应的数据。
简单总结一下,换页问题一般有如下几种情况:
第一种情况 -- 最简单的情况
- 特征:新增数据出现原有数据的尾部,不影响原有各页数据的页码。
- 典型示例:时间正序分页查询
- 分页方案:这是一种最简单的情况,用pageIndex+pageSize即可顺序获取每页数据,无需特殊处理。
- 备注:这种理想情况比较少见
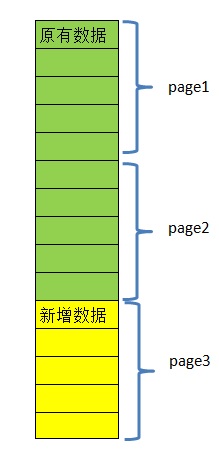
第二种情况 -- 稍微复杂一点
- 特征:新增数据增加于原有数据的前面,影响原有各页的页码
- 典型示例:时间倒序分页查询
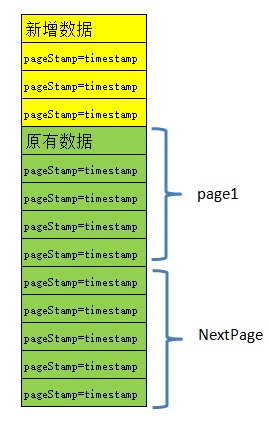
- 分页方案:不要使用pageIndex参数来获取分页数据,而是为每个数据项增加一个排序标识字段pageStamp,里面存储一个有序的唯一标识,例如timestamp值。换页时根据上次取到的分页数据最后一个项目的pageStamp,继续向下获取小于这个pageStamp的n条数据。这个方案的优点在于,如果有需要,还可以根据上次取得的分页数据的第一个项目中的pageStamp标识,向上方获取大于该pageStamp的n条数据。
- 备注:返回评论列表,回复列表等时间逆序的数据时很有用。
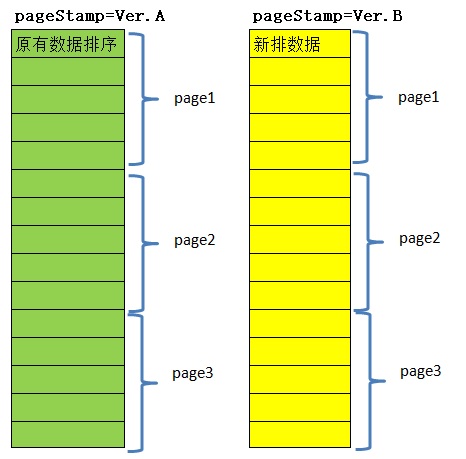
第三种情况 -- 借助于类缓存的版本机制
- 特征:数据排序定时变化,每次重排,各页数据全变
- 典型示例:热度排行榜;数据源分散,需要先汇总后排序的数据列表。
- 分页方案:每次排序结果都保留,以pageStamp标识版本。取第一页数据时,前端获得这个pageStamp标识。换页过程中把这个版本标识继续传递给服务端,只获取该版本的分页数据,也就不会分页混乱。
- 备注:这种方式理论上可以适用于任何情况,但是如果数据条数很多,一般会根据业务需求指定一个限制,每个版本的排序数据中只保留固定的条数。一般情况下,不需要长期保留所有版本的数据,采用类似于缓存的过期机制处理即可。
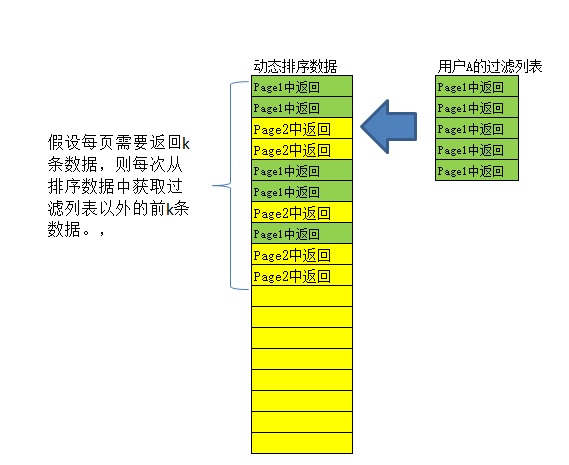
第四种情况 -- 无法采用任何正常的换页方案
- 特征:数据排序实时变化,无法用页码分页。
- 典型示例:可以实时更新排序的用户个性化推荐引擎。
- 分页方案:存储曾经给该用户展示过的数据列表,作为过滤依据。从当前最新排序数据中,获得过滤列表以外的、足够条数的数据返回。
- 备注:*必须* 根据业务特点,慎重设计过滤列表的存储方案,过滤方式等,谋求资源和性能上的最佳比例。