SELECT full_name,substring_index(group_concat(id ORDER BY id DESC),",",1) AS id FROM bzyd_perf_result GROUP BY full_name;
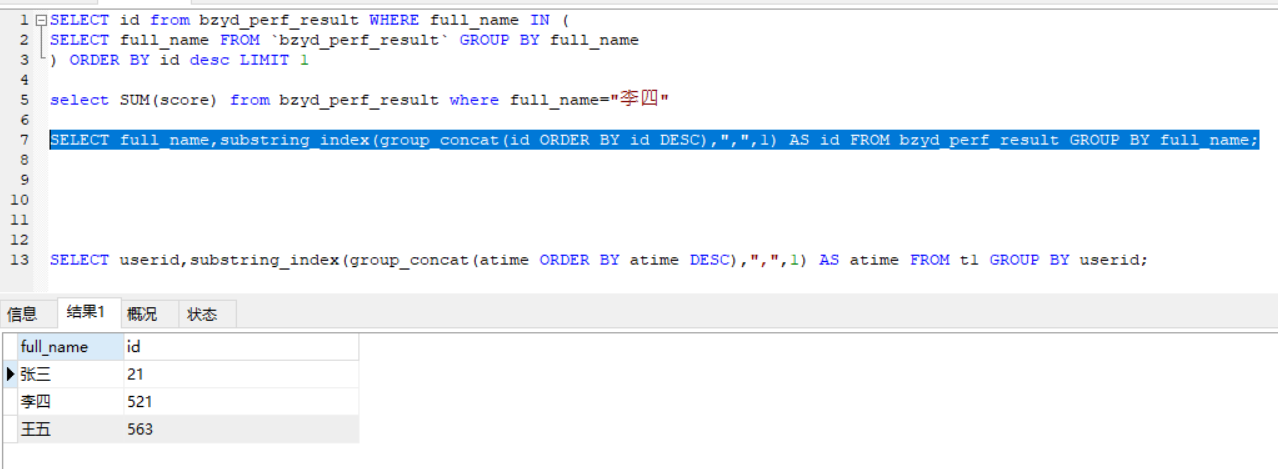
如下表:
代码如下
CREATE TABLE `t1` (
`userid` INT(11) DEFAULT NULL,
`atime` datetime DEFAULT NULL,
KEY `idx_userid` (`userid`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
数据如下:
代码如下
MySQL> SELECT * FROM t1;
+--------+---------------------+
| userid | atime |
+--------+---------------------+
| 1 | 2013-08-12 11:05:25 |
| 2 | 2013-08-12 11:05:29 |
| 3 | 2013-08-12 11:05:32 |
| 5 | 2013-08-12 11:05:34 |
| 1 | 2013-08-12 11:05:40 |
| 2 | 2013-08-12 11:05:43 |
| 3 | 2013-08-12 11:05:48 |
| 5 | 2013-08-12 11:06:03 |
+--------+---------------------+
8 ROWS IN SET (0.00 sec)
其中userid不唯一,要求取表中每个userid对应的时间离现在最近的一条记录.初看到一个这条件一般都会想到借用临时表及添加主建借助于join操作之类的.
给一个简方法:
代码如下
MySQL> SELECT userid,substring_index(group_concat(atime ORDER BY atime DESC),",",1) AS atime FROM t1 GROUP BY userid;
+--------+---------------------+
| userid | atime |
+--------+---------------------+
| 1 | 2013-08-12 11:05:40 |
| 2 | 2013-08-12 11:05:43 |
| 3 | 2013-08-12 11:05:48 |
| 5 | 2013-08-12 11:06:03 |
+--------+---------------------+
4 ROWS IN SET (0.03 sec)
查询及删除重复记录
删除表中多余的重复记录,重复记录是根据单个字段(peopleId)来判断,只留有rowid最小的记录
代码如下
delete from people
where peopleId in (select peopleId from people group by peopleId having count(peopleId) > 1)
and rowid not in (select min(rowid) from people group by peopleId having count(peopleId )>1)
3、查找表中多余的重复记录(多个字段)
代码如下
select * from vitae a
where (a.peopleId,a.seq) in (select peopleId,seq from vitae group by peopleId,seq having count(*) > 1)
4、删除表中多余的重复记录(多个字段),只留有rowid最小的记录
代码如下
delete from vitae a
where (a.peopleId,a.seq) in (select peopleId,seq from vitae group by peopleId,seq having count(*) > 1)
and rowid not in (select min(rowid) from vitae group by peopleId,seq having count(*)>1)
5、查找表中多余的重复记录(多个字段),不包含rowid最小的记录
代码如下
select * from vitae a
where (a.peopleId,a.seq) in (select peopleId,seq from vitae group by peopleId,seq having count(*) > 1)
and rowid not in (select min(rowid) from vitae group by peopleId,seq having count(*)>1)
————————————————
版权声明:本文为CSDN博主「欧皇·诸葛莺」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/weixin_29560137/article/details/113234203