生成器:
函数与yield连用,凡是函数中有yield的,调用该函数的时候均不会立即执行,而是会返回一个生成器。
生成器本质上是一个迭代器,需要通过 【生成器.__next__()】或者【next(生成器)】取值。
创建生成器的函数中的return只有终止函数的功能,不会有任何返回值。
yield:yield会保存函数的暂停状态,并返回一个生成器,以后每次执行一次yield会向生成器中增加一个值。yield一定要在函数内部定义。
yield与return的区别:
yield可以执行无数次返回多次值,return只能执行一次返回一次值。
yield和return后面返回的值可以是无限个数。返回多个值的时候,以元组的形式储存
写一个自定义的生成器,模拟内置的range()函数
再次注意:生成器本质上也是一个迭代器,也是一个可迭代对象,生成器也可以通过for循环取值
# _*_ coding: gbk _*_
# @Author: Wonder
def my_range(start, end, sep=1):
while start < end:
yield start
start += sep
res = my_range(1, 10) # 生成器res,打印res获得的是内存地址
print(res) # <generator object my_range at 0x000001E3E0463CC8>
i = 0
while True:
try:
i += 1
print(f'统计次数{i}')
print(res.__next__()) # 与next(res)效果一样
print(next(res))
except StopIteration: # 取值到最后抛出异常退出
break
生成器的取值方式在上述例子中已经体现了,下面通过for循环取值
def fib(n):
a, b = 0, 1
while (n > 0):
yield b
a, b = b, a + b
n -= 1
return a
for i in fib(4): # 生成器也是可迭代的,所以可以用for循环取值
print(i)
请用自己认为通俗易懂的话简述面向过程编程思想,并列举优缺点。
面向过程编程思想就是分析出解决问题所需要的步骤,然后用函数把这些步骤一步一步实现,使用的时候一个一个依次调用就可以了。
优点:将复杂问题流程化,简单化
缺点:扩展性差,若修改已设计的一部分功能,会影响其他功能
三元表达式 :条件成立的返回值 if 条件判断 else 条件不成立的返回值
# _*_ coding: gbk _*_
# @Author: Wonder
def tree(num1, num2):
res = num1 if num1 > num2 else num2
return res
print(tree(11, 12)) # 12
列表生成式和生成器表达式:
可以一行生成列表 [line for line in 可迭代对象 条件判断 ] 将可迭代对象中的值依次取出,生成一个新的列表
除yield生成生成器外,还可以通过生成器表达式生成生成器,语法结构和列表生成式一样,外层将中括号换成小括号即可
generator1 = (line for line in range(10)) # 生成器表达式 print(generator1) # <generator object <genexpr> at 0x0000016448E777C8> list3 = [line for line in range(10)] # 列表生成式 print(list3) # [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
匿名函数lambda
表达式 lambda 参数:与参数有关的返回值,也可以是与参数无关的固定值
lambda parameters : expression
parameters:参数,可以为空,一般提供位置参数,用逗号隔开
expression: 相当于返回值,可以是一个表达式,但不能有分支和循环,也不能出现return和yield
匿名函数要和内置函数一起使用才有意义。
# _*_ coding: gbk _*_
# @Author: Wonder
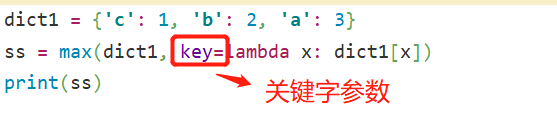
dict1 = {3: 5,
5: 2,
7: 1}
# 取出value值最大的一条
print(max(dict1, key=lambda x: dict1[x])) # 取value最大的
print(max(dict1,key=lambda x:x)) # 取key最大的
内置函数
max( 可迭代对象,key=XXX)
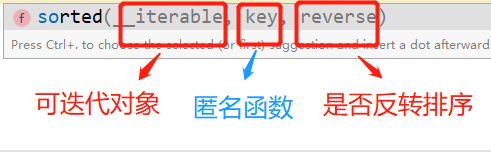
sorted(可迭代对象,key==XX,reverse=XX)