深拷贝和浅拷贝
列表的拷贝,用copy方法浅拷贝,新列表和被拷贝列表的id是不一样的。
list1 = [1, 'ss', (5, 6), ['p', 'w','M'], {'key1': 'value1', 'key2':'value2'}]
print('list1', id(list1)) # list1 1964077175880
list2 = list1.copy()
print('list2', id(list2)) # list2 1964333005960
浅拷贝之后,如果在新的列表中改变可变元素,会同步影响被拷贝列表中对应的元素,两者联动
如果在新列表中改变不可变元素,新老列表不会同步变化
list1 = [1, 'ss', (5, 6), ['p', 'w','M']]
print('list1', id(list1)) # list1 2443199403080
list2 = list1.copy()
print('list2', id(list2)) # list2 2443455166280
list2[3][1] = 'qqqqqq' # 对list2中第四个元素进行修改
list2[2] = ('x', 'y')
print('list1第四个元素id', id(list1[3])) # list1第四个元素id 2443199402568
print('list1第一个元素id', id(list1[0])) # list1第一个元素id 140729573994768
print(list1) # [1, 'ss', (5, 6), ['p', 'qqqqqq', 'M']]
print('list2第四个元素id', id(list2[3])) # list2第四个元素id 2443199402568
print('list2第一个元素id', id(list2[0])) # list2第一个元素id 140729573994768
print(list2) # [1, 'ss', ('x', 'y'), ['p', 'qqqqqq', 'M']]
深拷贝需要import copy的包,使用其中的deepcopy函数
深拷贝之后,新旧列表毫无瓜葛,就是完全不相关的两个列表。
深拷贝之后,列表中可变元素的id不一样,不可变元素的id是一样的。
import copy
list1 = [1, 'ss', (5, 6), ['p', 'w','M']]
list2 = copy.deepcopy(list1)
print('list1', id(list1)) # list1 1665335972936
print('list2', id(list2)) # list2 1665620498440
list2[3][1] = 'qqqqqq'
print(list1) # [1, 'ss', (5, 6), ['p', 'w', 'M']]
print(list2) # [1, 'ss', (5, 6), ['p', 'qqqqqq', 'M']]
print('list1第四个元素id', id(list1[3])) # list1第四个元素id 1665335972424
print('list2第四个元素id', id(list2[3])) # list2第四个元素id 1665365546952
文件的编码
在电脑中执行程序的过程
1、硬盘的内容加载到内存
2、CPU去内存中取数据,执行程序。
3、执行生成的数据,优先存入内存。
python解释器在计算机中的运行过程
1、python解释器代码由硬盘加载到内存
2、文件从硬盘加载到内存
3、解释器读取文件内容
4、识别python语法,执行操作
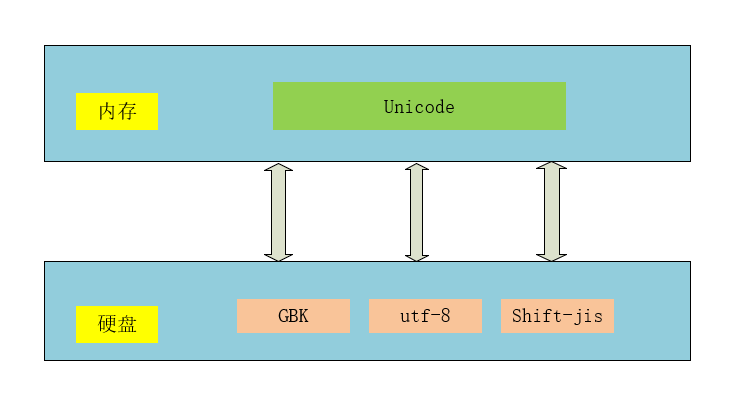
ASCII码 一个字节代表一个英文字母
GBK码 两个字节代表一个中文
utf-8码 一个字节代表英文,3个字节代表汉字
utf-8只和Unicode做映射,其他编码必须先转成unicode,才可以转成utf-8
目前,计算机内存中均是Unicode,硬盘中均是utf-8
字节byte,一个字节由8个bit组成。
编码的过程,由字符转为字节流 encode
解码的过程,由字节流转为字符 decode
用什么格式编码,就要用什么格式解码
unicode(内存) ---> 编码encode---> utf-8(硬盘)
utf-8(硬盘)---> 解码decode---> unicode (内存)
打开文件的三种模式
1、 r模式,
只读,如果文件不存在的话会报错
2、w模式
只写,如果文件不存在,则创建一个文件,将内容写入
如果文件存在,则会先将文件里的内容清空,再将内容写进去
3、a模式
如果文件存在,则再内容后面追加内容
如果文件不存在,则创建一个文件,将内容写入
打开文件的语法格式:
with open(r‘带后缀的文件名’,mode=‘打开模式’,encoding='文件的编码格式')as f :
r : 用来转义‘带后缀的文件名’路径中的转义字符
带后缀的文件名 :可以是绝对路径,也可以是相对路径
文件编码格式 : 与打开的文件编码模式一致即可
f :文件对象的建成,便于后面使用
举例说明:
with open(r'RECORD.txt', 'w', encoding='utf-8') as wf:
wf.write('AAAAAAA') # AAAAAAA
with open(r'RECORD.txt', 'a', encoding='utf-8')as af:
af.write('BBBBB') # AAAAAAABBBBB
也可以同时打开两个文本文件,一个只读一个只写
with open(r'RECORD.txt', 'r', encoding='utf-8') as rf, #r默认的时rt,读文本文件的
open(r'newRecord.py', 'w', encoding='utf-8')as wf:
a = rf.read() # 打开RECORD.txt文件
wf.write(a) # 将RECORD.txt文件写入newRecord.py
打开图片等非文本文件,拷贝的时候不要指定encoding参数。
with open(r'th.jpg', 'rb') as rf, open(r'newPhoto.png', 'wb')as wf: #rb用于读byte文件的
sss = rf.read()
wf.write(sss)