Some part of code can be download from
https://files.cnblogs.com/files/cschen588/car-project1.zip
Only a part of the project file, OrderStreamingProcessor.scala is for part 3. Virtual Station
KafkaManager.scala is for part 4
Project Scope
This is a data engineer project, supporting stream tracking of cab, cab order calculation, Virtual Station calculation and data wraehousing.
Project Structure
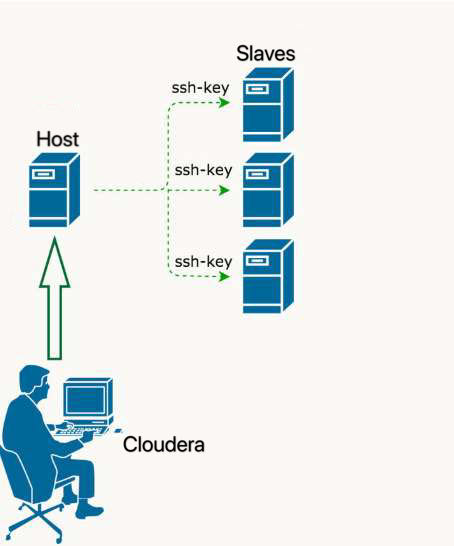
1. Flume-kafka-redis-hbase pipeline
Purpose: Real-time order track for taxi
Log on to cloudera , start kafka
producer

consumer

connect flume successful
Configre one flume agent to one kafka topic, there is also flume catlog sending to many topics.
flume:node02 redis:node01
GPSConsumer: play_chengdu.sh produce data,flume monitor and send to kafka,kafka give redis
attention:redis needs to start,flume start,redis password correctly set.
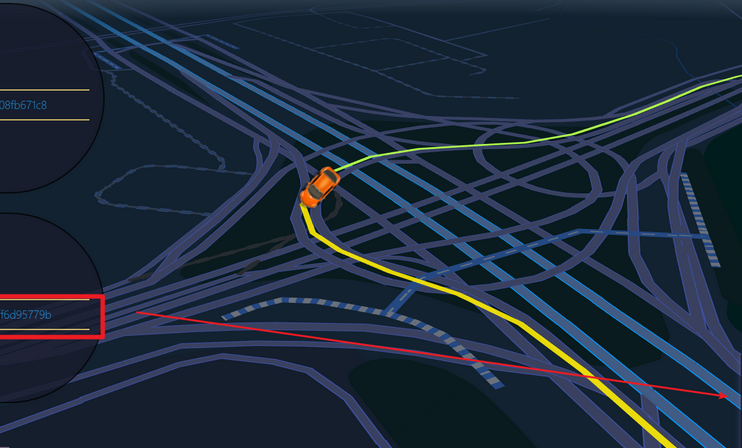
The tracked cab would move according to streaming of the shell script
2. Flume-kafka-sparkstreaming-redis pipeline
Purpose: Caluculate real-time order presenting to users
Structure

OrderStreamingProcessor:(store in redis)
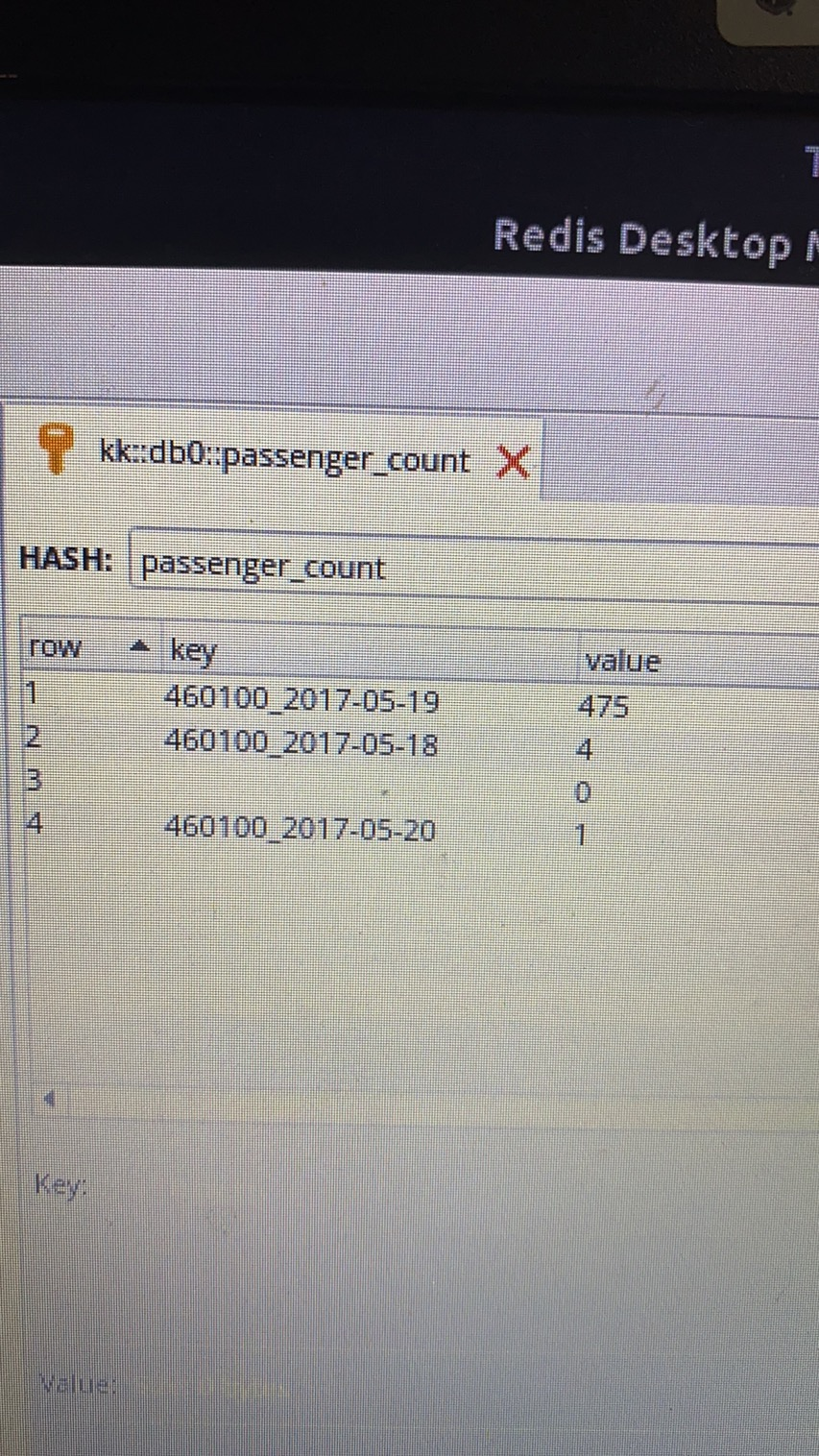
The order count would go up with real-time order per hour
3. Hbase-sparksql-spark-hbase-jdbc
Purpose: Spark calculating Virtual Station for customers
What is Virtual Station
Virtual Station is a virtual getting on spot for cab drivers and customers. They found that it would be a waste of time if customers say something like 'pick me up near the bridge', so the APP will suggest potential getting on spots where a lot of other users getting on cabs.
Structure

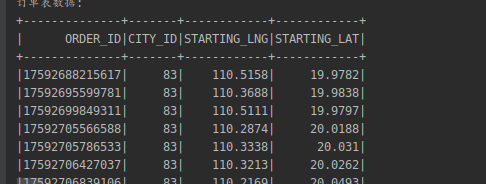
data pre-processing
database selection outcome covert to json

time manage
1.Virtual Station,uber h3
2.spark offline task
3.spark-hbase
hbase->spark load
spark->hbase
4.Virtual Station,Map
5.phoenix+hbase -> jdbc service
6.web->jdbc service
Phoenix install

install python2(python2 code running in python3 environment)
conda create --name python2 python=2.7
source activate python2
succeed
create phoenix view for hbase table
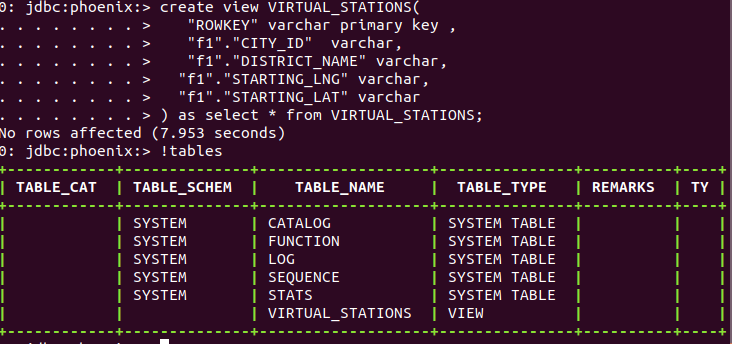


hbase
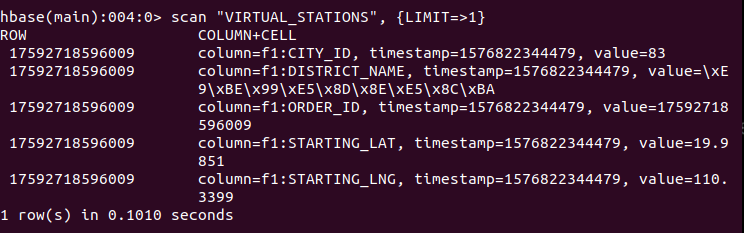
Virtual_Stations are caluculated in the city with 100+ people getting on an off the cab near certain points in one day.
4. MySQL-maxwell-kafka-hbase
Purpose:Data warehousing from mySQL to hbase
Purpose
Data Warehouse helps to integrate many sources of data to reduce stress on the production system. Data warehouse helps to reduce total turnaround time for analysis and reporting. Restructuring and Integration make it easier for the user to use for reporting and analysis.
Structure

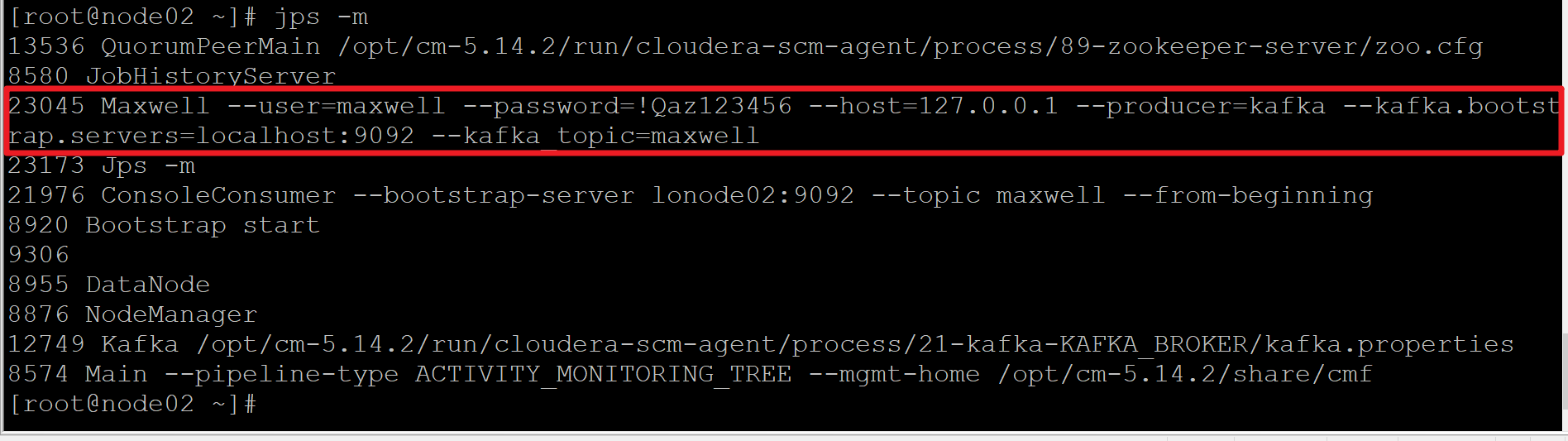
Hbase loading balance:
1pre partition
2rowkey setting(no more than 64 bit):



Install KafkaOffsetMonitor
where maxwell binlog locates

rollback binlog data
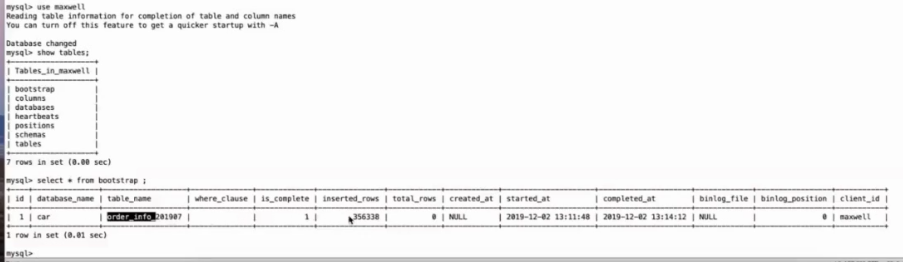
 sql Bootstrap table
sql Bootstrap table
daily environment setting:
<profiles>
<!-- daily environment-->
<profile>
<id>dev</id>
<activation>
<activeByDefault>true</activeByDefault>
<property>
<name>dev</name>
<value>Dev</value>
</property>
</activation>
<build>
<resources>
<resource>
<directory>src/main/resources/dev</directory>
</resource>
</resources>
</build>
</profile>
<!-- developing environment-->
<profile>
<id>pro</id>
<activation>
<activeByDefault>true</activeByDefault>
<property>
<name>pro</name>
<value>Pro</value>
</property>
</activation>
<build>
<resources>
<resource>
<directory>src/main/resources/pro</directory>
</resource>
</resources>
</build>
</profile>
<!-- testing environment-->
<profile>
<id>test</id>
<activation>
<activeByDefault>true</activeByDefault>
<property>
<name>test</name>
<value>Test</value>
</property>
</activation>
<build>
<resources>
<resource>
<directory>src/main/resources/test</directory>
</resource>
</resources>
</build>
</profile>
</profiles>

1. ERRORS OCCURED:
IntelliJ IDEA build project "xxx package" or "cannot find symbol"
https://www.cnblogs.com/han-1034683568/p/9540564.html
SLF4J: Failed to load class “org.slf4j.impl.StaticLoggerBinder”
https://stackoverflow.com/questions/7421612/slf4j-failed-to-load-class-org-slf4j-impl-staticloggerbinder
download slf4j-simple-1.6.2.jar modify xml
No appenders could be found for logger(log4j)?
Under project resources modify log4j.properties
https://stackoverflow.com/questions/12532339/no-appenders-could-be-found-for-loggerlog4j

virtual box start problem:
VirtualBox.xml is empty
Your problem is that you have a corrupt "VirtualBox.xml" file in the location contained in the error message, '/Users/alexanderevans/Library/VirtualBox/VirtualBox.xml'. In that same folder there's a "VirtualBox.xml-prev" file. Delete the "VirtualBox.xml" file and rename the "VirtualBox.xml-prev" to "VirtualBox.xml". Try it again.
Error compiling sbt component 'compiler-interface-2.11.1-52.0'
idea package dependency:
1.check mark as diractory
2.dependency
OrderStreamingProcessor: org.apache.hadoop.security.AccessControlException:
linux root user: su hdfs ///hadoop dfs -chmod 777 /sparkapp