PAT A1039
PAT A1047
PAT A1063
PAT A1060
PAT A1071
Codeup 600
Codeup 601
HDU 1237
&:以后maybe持续更新。后面补得挺仓促,知识点整理自算法笔记,略补充。
可以理解成:长度可以自动变化的数组。
因为在使用固定长度的数组时,如果容量较大,会很容易越界。(小容量时可用数组,大容量或者元素个数不确定时建议用vector,可以节省空间)
用法
①定义vector
vector<type> 名称
eg: vector<int> age; vector<char> name; vector< vector<int> > name; //注意!当容器作为数据类型时,>>之间要加空格。否则会被编译器视作移位。 两个维度的长度可以自动变化的二维数组: vector< vector<int> > name; 一个维度固定,一个维度长度自动变化的二维数组: vector<int> name[100];
②访问元素
法1:通过下标,用法和数组一样。
法2:利用迭代器。vector<int>::iterator it
#include <cstdio> #include <vector> using namespace std; int main() { vector<int> age; for(int i = 1; i<=5; i++) { age.push_back(i); } vector<int>::iterator it = age.begin(); // 写法1:指针访问 for(int i = 0; i<5; i++) { printf("%d ",*(it+i)); } // 写法2:自加操作 for(vector<int>::iterator it = age.begin(); it!=age.end(); it++) { printf("%d ",*it); } return 0; }
③常用函数
vi.函数
push_back(元素):末尾插入元素。
pop_back():删除末尾元素。
size():容器内元素个数。
clear():清空元素。
insert(it, x):在迭代器it处插入元素x。
erase(it):删除it处的元素。
erase(it1, it2):删除[it1, it2)内的元素。两者是迭代器,一般是begin()+数字、end()之类的。
④vector用邻接表存储图
比用链表实现邻接表更简单。
建立一个vector数组Adj[N],N为顶点个数。 vector<int> Adj[N];
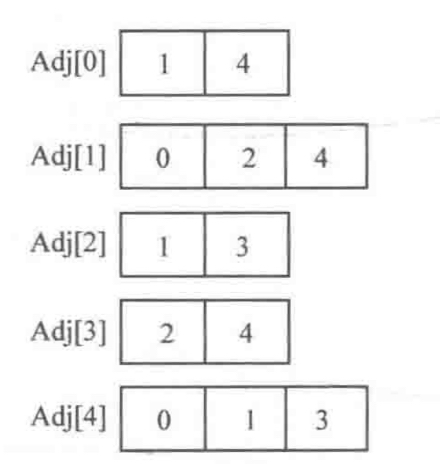
添加有向边1→3(无向边则加条3→1的):Adj[1].push_back(3)
若是带权图,则建立结构体Node存放每条边终点编号和边权。
struct Node{ int v; int w; }
定义Node型vector:vector<Node> Adj[N];
通过临时变量添加:
Node temp; temp.v = 3; temp.w = 4; Adj[1].push_back(temp);
通过构造函数添加:
struct Node{ int v,w; Node(int _v, int _w):v(_v),w(_w){} } Adj[1].push_back(Node(3,4));
例子
Zhejiang University has 40000 students and provides 2500 courses. Now given the student name lists of all the courses, you are supposed to output the registered course list for each student who comes for a query.
Input Specification:
Each input file contains one test case. For each case, the first line contains 2 positive integers: N (≤40000), the number of students who look for their course lists, and K (≤2500), the total number of courses. Then the student name lists are given for the courses (numbered from 1 to K) in the following format: for each course i, first the course index i and the number of registered students $N_i$ (≤200) are given in a line. Then in the next line, $N_i$ student names are given. A student name consists of 3 capital English letters plus a one-digit number. Finally the last line contains the N names of students who come for a query. All the names and numbers in a line are separated by a space.
Output Specification:
For each test case, print your results in N lines. Each line corresponds to one student, in the following format: first print the student's name, then the total number of registered courses of that student, and finally the indices of the courses in increasing order. The query results must be printed in the same order as input. All the data in a line must be separated by a space, with no extra space at the end of the line.
Sample Input:
11 5 4 7 BOB5 DON2 FRA8 JAY9 KAT3 LOR6 ZOE1 1 4 ANN0 BOB5 JAY9 LOR6 2 7 ANN0 BOB5 FRA8 JAY9 JOE4 KAT3 LOR6 3 1 BOB5 5 9 AMY7 ANN0 BOB5 DON2 FRA8 JAY9 KAT3 LOR6 ZOE1 ZOE1 ANN0 BOB5 JOE4 JAY9 FRA8 DON2 AMY7 KAT3 LOR6 NON9
Sample Output:
ZOE1 2 4 5 ANN0 3 1 2 5 BOB5 5 1 2 3 4 5 JOE4 1 2 JAY9 4 1 2 4 5 FRA8 3 2 4 5 DON2 2 4 5 AMY7 1 5 KAT3 3 2 4 5 LOR6 4 1 2 4 5 NON9 0
思路:以空间换时间,用散列表$students$的索引$i$代替名字,$students[i]$是个vector,存放course,vector的size就是该学生的选课数。
#include <cstdio> #include <vector> #include <algorithm> using namespace std; const int maxn = 26*26*26*10+10; int hashname(char* name) { return (name[0]-'A')*26*26*10+(name[1]-'A')*26*10+(name[2]-'A')*10+(name[3]-'0'); } int main() { int N,K; while(scanf("%d%d",&N,&K)!=EOF) { vector<int> students[maxn]; char name[5]; for(int i = 0; i<K; i++) { int course, num; scanf("%d%d",&course,&num); for(int j = 0; j < num; j++) { scanf("%s",name); int index = hashname(name); students[index].push_back(course); } } for(int i = 0; i < N; i++) { scanf("%s",name); int index = hashname(name); printf("%s %d",name,students[index].size()); sort(students[index].begin(), students[index].end()); for(int j = 0; j<students[index].size(); j++) { printf(" %d",students[index][j]); } printf(" "); } } return 0; }
Zhejiang University has 40,000 students and provides 2,500 courses. Now given the registered course list of each student, you are supposed to output the student name lists of all the courses.
Input Specification:
Each input file contains one test case. For each case, the first line contains 2 numbers: N (≤40000), the total number of students, and K (≤2500), the total number of courses. Then N lines follow, each contains a student's name (3 capital English letters plus a one-digit number), a positive number C (≤20) which is the number of courses that this student has registered, and then followed by C course numbers. For the sake of simplicity, the courses are numbered from 1 to K.
Output Specification:
For each test case, print the student name lists of all the courses in increasing order of the course numbers. For each course, first print in one line the course number and the number of registered students, separated by a space. Then output the students' names in alphabetical order. Each name occupies a line.
Sample Input:
10 5 ZOE1 2 4 5 ANN0 3 5 2 1 BOB5 5 3 4 2 1 5 JOE4 1 2 JAY9 4 1 2 5 4 FRA8 3 4 2 5 DON2 2 4 5 AMY7 1 5 KAT3 3 5 4 2 LOR6 4 2 4 1 5
Sample Output:
1 4 ANN0 BOB5 JAY9 LOR6 2 7 ANN0 BOB5 FRA8 JAY9 JOE4 KAT3 LOR6 3 1 BOB5 4 7 BOB5 DON2 FRA8 JAY9 KAT3 LOR6 ZOE1 5 9 AMY7 ANN0 BOB5 DON2 FRA8 JAY9 KAT3 LOR6 ZOE1
#include <cstdio> #include <vector> #include <algorithm> #include <cstring> using namespace std; const int maxn1 = 40010; const int maxn2 = 2510; char name[maxn1][5]; vector<int> courses[maxn2]; bool cmp(int a, int b) { return strcmp(name[a], name[b]) < 0; } int main() { int N,K; scanf("%d%d",&N,&K); for(int i = 0; i<N; i++){ int num, t; scanf("%s%d",name[i],&num); for(int j = 0; j<num; j++) { scanf("%d",&t); courses[t].push_back(i); } } for(int i = 1; i<=K; i++) { printf("%d %d ",i,courses[i].size()); sort(courses[i].begin(),courses[i].end(),cmp); for(int j = 0; j<courses[i].size(); j++) { printf("%s ",name[courses[i][j]]); } } return 0; }
set
一个内部自动有序,而且不含重复元素的容器,所以可以用来自动去重并升序排序。
只排序:如果要去处理元素不唯一的情况,就要用multiset。
只去重:unordered_set以散列代替了set内部的红黑树实现,可以处理只去重但不排序的情况。
用法
set<type> 名称
只能通过迭代器访问。且不能写成$*(it + i)$的方式,这种指针操作只适用与vector和string。可以自加。
for(set<int>::iterator it = st.begin();it!=st.end(); it++) { printf("%d ",*it); }
st.函数
insert(value):插入(排序是自动的)
find(value):返回迭代器:set<int>::iterator it = st.find(2);
erase(it):删除单个元素:st.erase(st.find(2))
erase(value):删除单个元素:st.erase(2)
erase(it1, it2):删除[it1, it2)区间内的所有元素:st.erase(st.begin(), st.end())
size():容器内元素个数。
clear():清空容器
Given two sets of integers, the similarity of the sets is defined to be $N_c/N_t*100%$, where $N_c$ is the number of distinct common numbers shared by the two sets, and $N_t$ is the total number of distinct numbers in the two sets. Your job is to calculate the similarity of any given pair of sets.
Input Specification:
Each input file contains one test case. Each case first gives a positive integer N(≤50) which is the total number of sets. Then N lines follow, each gives a set with a positive M (≤$10^4$) and followed by M integers in the range $[0, 10^9]$. After the input of sets, a positive integer K (≤2000) is given, followed by K lines of queries. Each query gives a pair of set numbers (the sets are numbered from 1 to N). All the numbers in a line are separated by a space.
Output Specification:
For each query, print in one line the similarity of the sets, in the percentage form accurate up to 1 decimal place.
Sample Input:
3 3 99 87 101 4 87 101 5 87 7 99 101 18 5 135 18 99 2 1 2 1 3
Sample Output:
50.0% 33.3%
思路:set作为二维矢量的一个维度。
#include <cstdio> #include <vector> #include <set> using namespace std; int main() { int N, M; scanf("%d",&N); vector<set<int> > v; for(int i = 0; i<N; i++) { set<int> s; scanf("%d",&M); int t; for(int j = 0; j<M; j++) { scanf("%d",&t); s.insert(t); } v.push_back(s); } scanf("%d",&M); for(int i = 0; i<M; i++) { int a,b; scanf("%d%d",&a,&b); int nc = v[a-1].size(); int nt = 0; for(set<int>::iterator it = v[b-1].begin(); it!=v[b-1].end(); it++) { if(v[a-1].count(*it)!=0) nt++; else nc++; } printf("%.1f%% ", 100.0*nt/nc); } return 0; }
string
存放字符串用的,操作起来比char数组方便。不过......在做题的时候,有时候会发现用string或许会超时,它的一些操作是比char数组慢一些的。&&:头文件是<string>而不是<string.h>。
用法
①定义string
string 名称
②读写
一般是用cin和cout。不过,可以用c_str()把string转化成char数组再进行输出。
string s1; cin>>s1; cout<<s1<<endl; string s2 = "abcdefg"; printf("%s ",str.c_str());
③访问
法1:通过下标。
法2:通过迭代器访问。(前面在set那一块时提到过$*(it + i)$的访问方式只适用于vector和string)
string str = "abcd"; // 下标 for(int i = 0; i<str.length(); i++) { printf("%c",str[i]); } printf(" "); // 迭代器 for(string::iterator it = str.begin(); it != str.end(); it++) { printf("%c",*it); } printf(" "); // 或者 string::iterator it = str.begin(); for(int i = 0; i<str.length(); i++) { printf("%c",*(it+i)); }
④常用函数
str1.函数
加减:例如str1 + str2、str1 += str2。
>、<、==、!=......按照字典序直接比较大小。
length()、size():返回string长度。str1.length()
insert(i, str1):在位置i插入str1。
insert(it, it1, it2):把str1的[it1, it2)部分插到str2的it位置处。三者都是迭代器。
erase(it):删除单个元素。
erase(it1, it2):删除区间[it1, it2)上的元素。
erase(i, length):删除从位置i开始的length个元素。
clear():清空str1。
substr(i, length):返回从位置i开始长度为length的子串。
find(str2):如果str2是str1的子串,返回str2在str1中首次出现的位置。
find(str2, i):如果str2是str1的子串,从位置i开始,返回str2在str1中首次出现的位置。
常数string::npos——如果str2不是str1的子串,str1.find(str2)返回这个常数。可以视作-1或者4294967295(unsigned int类型最大值)。
replace(i, length, str2):把str1从位置i开始长度为length的字符串替换成str2。
replace(it1, it2, str2):把str1的[it1, it2)上的子串替换成str2。
例子
If a machine can save only 3 significant digits, the float numbers 12300 and 12358.9 are considered equal since they are both saved as with simple chopping. Now given the number of significant digits on a machine and two float numbers, you are supposed to tell if they are treated equal in that machine.
Input Specification:
Each input file contains one test case which gives three numbers N, A and B, where N (<100) is the number of significant digits, and A and B are the two float numbers to be compared. Each float number is non-negative, no greater than , and that its total digit number is less than 100.
Output Specification:
For each test case, print in a line YES if the two numbers are treated equal, and then the number in the standard form 0.d[1]...d[N]*10^k (d[1]>0 unless the number is 0); or NO if they are not treated equal, and then the two numbers in their standard form. All the terms must be separated by a space, with no extra space at the end of a line.
Note: Simple chopping is assumed without rounding.
Sample Input 1:
3 12300 12358.9
Sample Output 1:
YES 0.123*10^5
Sample Input 2:
3 120 128
Sample Output 2:
NO 0.120*10^3 0.128*10^3
#include <iostream> #include <string> using namespace std; int n; string deal(string s, int& e) { int k = 0; while(s.length() > 0 && s[0]=='0') { s.erase(s.begin()); } if(s[0]=='.') { s.erase(s.begin()); while(s.length()>0 && s[0] == '0') { s.erase(s.begin()); e--; } }else{ while(k<s.length() && s[k]!='.') { k++; e++; } if(k<s.length()) { s.erase(s.begin()+k); } } if(s.length() == 0) { e = 0; } int num = 0; k = 0; string res; while(num<n) { if(k<s.length()) res += s[k++]; else res += '0'; num++; } return res; } int main() { string s1, s2, s3, s4; cin>>n>>s1>>s2; int e1 = 0, e2 = 0; s3 = deal(s1,e1); s4 = deal(s2,e2); if(s3 == s4 && e1 == e2) { cout<<"YES 0."<<s3<<"*10^"<<e1<<endl; }else{ cout<<"NO 0."<<s3<<"*10^"<<e1<<" 0."<<s4<<"*10^"<<e2<<endl; } return 0; }
map
用散列表时:通过散列表判断某数字是否出现过,如果这个数字非常大,没法给出那么大的数组。
这时,使用map会很方便。它可以把任何基本类型映射到任何基本类型。而且map内部是使用红黑树实现的,所以他按照key从小到大自动排序的。(STL容器可以作为key和value,但是char数组不能作为key和value)
和set类似,map的键和值是唯一的。
一个键对应多个值:用multimap。
不自动排序:unordered_map以散列代替了map内部的红黑树实现,可以处理映射但不按照key排序的情况。速度比map快很多。
用法
①定义map
map<type1, type2> mp;
②访问元素
法1:通过下标访问。
法2:通过迭代器访问。key用it->first访问,value用it->second访问。
#include <cstdio> #include <map> using namespace std; int main() { map<char,int> mp1; mp1['c'] = 20; mp1['c'] = 30; printf("%d ",mp1['c']); map<char,int> mp2; mp2['m'] = 20; mp2['r'] = 30; mp2['a'] = 40; for(map<char,int>::iterator it = mp2.begin();it!=mp2.end();it++) { printf("%c %d ",it->first,it->second); } return 0; }
③常用函数
mp.函数
find(key):返回key的映射的迭代器。mp.find(key)->first...
erase(it):删除元素的迭代器。
erase(key):删除key代表的元素。
erase(it1, it2):删除迭代器区间[it1, it2)内的所有元素。
size():返回mp中映射的对数。
clear():清空mp。
例子
People often have a preference among synonyms of the same word. For example, some may prefer "the police", while others may prefer "the cops". Analyzing such patterns can help to narrow down a speaker's identity, which is useful when validating, for example, whether it's still the same person behind an online avatar.
Now given a paragraph of text sampled from someone's speech, can you find the person's most commonly used word?
Input Specification:
Each input file contains one test case. For each case, there is one line of text no more than 1048576 characters in length, terminated by a carriage return
. The input contains at least one alphanumerical character, i.e., one character from the set [0-9 A-Z a-z].
Output Specification:
For each test case, print in one line the most commonly occurring word in the input text, followed by a space and the number of times it has occurred in the input. If there are more than one such words, print the lexicographically smallest one. The word should be printed in all lower case. Here a "word" is defined as a continuous sequence of alphanumerical characters separated by non-alphanumerical characters or the line beginning/end.
Note that words are case insensitive.
Sample Input:
Can1: "Can a can can a can? It can!"
Sample Output:
can 5
#include <iostream> #include <map> using namespace std; int main() { string s,t=""; getline(cin,s); map<string,int> mp; for(int i = 0; i < s.length(); i++) { if(isalnum(s[i])) { s[i] = tolower(s[i]); t += s[i]; } if(i == s.length()-1 || !isalnum(s[i])) { if(t.length()!=0) mp[t]++; t=""; } } int maxn = 0; string s1; for(map<string,int>::iterator it = mp.begin(); it != mp.end(); it++) { if(it->second > maxn) { maxn = it->second; s1 = it->first; } } cout<<s1<<" "<<maxn<<endl; return 0; }
queue
队列,先进先出。
一般在广度优先搜索时,我们可以不用手动写队列,直接调用queue即可。
用法
①定义queue
queue<type> 名称
②访问元素
只能用front()访问队首元素,用back()访问队尾元素。
#include <cstdio> #include <queue> using namespace std; int main() { queue<int> q; for(int i = 1; i<=5; i++) { q.push(i); } printf("%d %d",q.front(),q.back()); return 0; }
③常用函数
q.函数名称
push(x):将x入队。
front()、back():获得队首、队尾元素。
pop():队首元素出队。
empty():检测是否为空。注意:在使用front()、pop()函数前,要用empty()判断队列是否为空,否则可能会报错。
size():队列中元素个数。
例子
输入10个整数,将其中最小的数与第一个数对换,把最大的数与最后一个数对换。写三个函数; ①输入10个数;②进行处理;③输出10个数。
输入:10个整数
输出:整理后的十个数,每个数后跟一个空格(注意最后一个数后也有空格)
输入:
2 1 3 4 5 6 7 8 10 9
输出:
1 2 3 4 5 6 7 8 9 10
思路:这道题是有个陷阱的,一般情况下,我们是先把min和第一个元素交换,然后把最大值与末尾元素交换。如果第一位元素是最大值的话,后面与末尾元素交换的最大值位置应该及时修改的,不然会出错。(比queue好用的方法多了去了,不值得用queue)。例如:
10, 2, 1, 3, 4, 5, 6, 7, 8, 9
min和第一位交换,10作为第一位元素的身份和1进行交换:
1, 2, 10, 3, 4, 5, 6, 7, 8, 9
我们可以定义两个队列q和temp。首先将数据读入队列q,在读入的时候顺便搞到四个位置信息:first(第一个元素)、last(末尾元素)、max、min。
q: 10, 2, 1, 3, 4, 5, 6, 7, 8, 9
接下来,将min填到临时队列temp中。min先放到temp的队头,然后把q的队头出队(相当于把min换到首位),然后对q队列后面的8个元素遍历,依次压入队列temp中,如果出现元素是min,那么压入的不是min而是first(相当于把first换到min位置)。temp队尾塞上max。(嗯,后面会把第一个max换成last的值)
temp:1, 2, 10, 3, 4, 5, 6, 7, 8 ,10
temp填完之后,q也释放空了,然后我们,身份互换,在遍历队列temp,找到max位置就和last换了,temp前脚出队,q后脚入队。
q: 1, 2, 9, 3, 4, 5, 6, 7, 8, 10
打印,结束。就是在两个队列之间反复横跳。
#include <cstdio> #include <queue> #include <limits.h> using namespace std; int MAX = INT_MIN; int MIN = INT_MAX; int first, last; void input(queue<int>& q){ int x; for (int i = 0; i < 10; i++) { scanf("%d",&x); q.push(x); if(x > MAX) MAX = x; if(x < MIN) MIN = x; } first = q.front(); last = q.back(); } void deal(queue<int>& q, queue<int>& temp){ temp.push(MIN); q.pop(); for(int i = 0; i<8; i++) { if(q.front() == MIN) q.front() = first; temp.push(q.front()); q.pop(); } temp.push(last); while(!q.empty()){ q.pop(); } int flag = true; while(!temp.empty()){ if(temp.front() == MAX){ if(flag == true){ temp.front() = last; } flag = false; } q.push(temp.front()); temp.pop(); } } void print(queue<int>& p){ while(!p.empty()){ printf("%d ", p.front()); p.pop(); } } int main() { queue<int> q; queue<int> temp; input(q); deal(q, temp); print(q); return 0; }
priority_queue
用法
①定义priority_queue
priority_queue<type> 名称
②访问元素
只能通过top()访问队首元素,没有front()、back()。
③常用函数
q.函数名称
push(x):x入队。
top():获得队首元素。
pop():队首元素出队。
empty():判断队列为空。
size():队列中元素个数。
④设置元素优先级
1)基本数据类型的优先级设置(int、double、char....这些可以直接使用的数据类型)
priority_queue< int, vector<int>, greater<int> > q;
第一个元素是基本数据类型;
以容器作为第二个元素是用来承载优先队列底层的堆,里面的类型参考第一个元素;
第三个元素是对第一个元素的比较类,less<int>表示数字大的优先级大(默认)、greater<int>表示数字小的优先级大。
#include <cstdio> #include <queue> using namespace std; int main() { priority_queue<int, vector<int>, greater<int> > q; q.push(3); q.push(4); q.push(1); printf("%d ",q.top()); return 0; }
2)结构体的优先级设置
a、在结构体内部重载。
#include <cstdio> #include <iostream> #include <string> #include <queue> using namespace std; struct fruit{ string name; int price; friend bool operator < (fruit f1, fruit f2) { return f1.price > f2.price; } }f1,f2,f3; int main() { priority_queue<fruit> q; f1.name = "peach"; f2.name = "pear"; f3.name = "apple"; f1.price = 3; f2.price = 4; f3.price = 1; q.push(f1); q.push(f2); q.push(f3); cout<<q.top().name<<" "<<q.top().price<<endl; return 0; }
比较一下:
sort函数中的cmp——return a<b是指从小到大,return a>b是指从大到小;
友元函数重载小于号——return a<b是大的优先,return a>b是小的优先。
两者可视为效果相反。
b、在结构体外部重载
去掉友元friend,把小于号改成括号,并包装在一个cmp结构体中。而且,优先队列的定义方式也要改成第二种。
#include <cstdio> #include <iostream> #include <string> #include <queue> using namespace std; struct fruit{ string name; int price; }f1,f2,f3; struct cmp{ bool operator () (fruit f1, fruit f2){ return f1.price > f2.price; } }; int main() { priority_queue<fruit, vector<fruit>, cmp> q; f1.name = "peach"; f2.name = "pear"; f3.name = "apple"; f1.price = 3; f2.price = 4; f3.price = 1; q.push(f1); q.push(f2); q.push(f3); cout<<q.top().name<<" "<<q.top().price<<endl; return 0; }
另外,如果数据量大,使用引用可以提高效率。添加const和&。
bool operator () (const fruit &f1, const fruit &f2){ return f1.price > f2.price; } friend bool operator < (const fruit &f1, const fruit &f2) { return f1.price > f2.price; }
例子
读入任务调度序列,输出n个任务适合的一种调度方式。
输入
输入包含多组测试数据。
每组第一行输入一个整数n(n<100000),表示有n个任务。
接下来n行,每行第一个表示前序任务,括号中的任务为若干个后序任务,表示只有在前序任务完成的情况下,后序任务才能开始。若后序为NULL则表示无后继任务。
输出
输出调度方式,输出如果有多种适合的调度方式,请输出字典序最小的一种。
输入例子:
4
Task0(Task1,Task2)
Task1(Task3)
Task2(NULL)
Task3(NULL)
输出例子:
Task0 Task1 Task2 Task3
代码参考自:https://blog.csdn.net/xunalove/article/details/88371708。按照两种优先级设置方法有两种写法,还是比较建议用第一种的。
CODE 1:
#include<stdio.h> #include<algorithm> #include<iostream> #include<queue> #include<map> using namespace std; int n; struct task { string name; int priority; friend bool operator<(const task &t1, const task &t2) { if(t1.priority!=t2.priority) return t1.priority > t2.priority;//输出优先级大的 else return t1.name > t2.name;//输出字典序小的 } }; void deal(string s, priority_queue<task> &p, map<string, int> &list) { string now = ""; task t; int i=0; //处理第一个 while(s[i]!='(') { now+=s[i]; i++; } if(list[now]==0)//第一个 { t.name = now; t.priority = 0; list[now] = 0; p.push(t); } s.erase(s.begin(), s.begin()+i);//删除Task0 s.erase(s.begin());//删除( int temp = list[now]+1; i=0; now = ""; //处理括号里面的 while(i<s.size()) { if((s[i]==','||s[i]==')')&&list[now]==0&&now!="NULL") { t.name = now; t.priority = temp; list[now] = temp; p.push(t); //cout<<now<<" "<<temp <<endl; now = ""; } else now+=s[i]; i++; } } int main() { while(scanf("%d",&n)!=EOF) { priority_queue<task> p; map<string, int> list;//名字---优先级 for(int i=0; i<n; i++) { string s; cin>>s; deal(s, p, list); } while(p.empty()!=1) { cout<<p.top().name; if(p.size()>1) cout<<" "; else cout<<endl; p.pop(); } } return 0; }
CODE 2:
#include<stdio.h> #include<string.h> #include<queue> #include<map> #include<algorithm> using namespace std; struct node { int no;//编号 int prior; }; struct cmp { bool operator()(node a, node b) { if(a.prior!=b.prior) return a.prior > b.prior;//按照优先级 else return a.no > b.no;//按照名字 } }; char a[1000001]; int main() { int n; while(scanf("%d",&n)!=EOF) { getchar(); priority_queue<node, vector<node>, cmp> q; map<int,int> p;//存放优先级 for(int i=0; i<n; i++) { scanf("%s",a); int i1=4, n1=0; while(a[i1]!='(')//第一个任务 n1=n1*10+a[i1++]-'0'; node t; t.no = n1; if(i==0)//是否是所有任务中的第一个 { t.prior = 0; q.push(t); } else t.prior = p[t.no]; int i2= 6, n2=0; if(a[i2]=='N') continue; while(i2 < strlen(a)) { if(a[i2]>='0'&&a[i2]<='9') n2 = n2*10+a[i2]-'0'; if(a[i2]==','||a[i2]==')') { if(p[n2]==0)//队列中没有 { node tt; tt.no=n2; tt.prior = t.prior+1; q.push(tt); n2 = 0; p[n2]= tt.prior; } } i2++; } } while(q.size()>=1) { node t = q.top(); q.pop(); printf("Task%d ", t.no); } } }
stack
栈,后进先出。
用stack模拟递归算法可以避免递归层数过多导致崩溃(少用)。
用法
①定义stack
stack<type> 名称
②访问元素
只能用top()来访问栈顶元素。
③常用函数
st.函数
push(x):x入栈。
top():获得栈顶元素。
pop():弹出栈顶元素。
empty():判断栈空。
size():栈内元素个数。
例子
Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 65536/32768 K (Java/Others)
Total Submission(s): 39041 Accepted Submission(s): 14024
1 + 24 + 2 * 5 - 7 / 110
3.0013.36
pair
pair像一个小的结构体,提供一个包含2个数据成员的结构体模板(二元结构体)。也就是说两个元素结合可以用pair来表示。
需要添加头文件 #include <utility>。
map的内部实现涉及pair,在添加map头文件时会自动添加utility,可以用map来代替。
用法
①定义pair
pair<firsttype,secondtype> p
定义+初始化:
pair<firsttype,secondtype> p(初始化元素,初始化元素)
临时构建pair有两种方法:
① pair<firsttype,secondtype> (初始化元素,初始化元素)
② make_pair(初始化元素,初始化元素)
②访问元素
p.first、p.second
③常用函数
比较运算符:先比较first大小,first相同则在比较second大小。