
前置启动程序
事先启动一个web应用程序,用jps查看其进程id,接着用各种jdk自带命令优化应用
jvm内存模型

Jmap
此命令可以用来查看内存信息,实例个数以及占用内存大小

jmap ‐histo 14660 #查看历史生成的实例
jmap ‐histo:live 14660 #查看当前存活的实例,执行过程中可能会触发一次full gc
打开log.txt,文件内容如下:

- num:序号
- instances:实例数量
- bytes:占用空间大小
- class name:类名称,[C is a char[],[S is a short[],[I is a int[],[B is a byte[],[[I is a int [][]
堆信息

堆内存dump
jmap ‐dump:format=b,file=eureka.hprof 14660
也可以设置内存溢出自动导出dump文件(内存很大的时候,可能会导不出来)
- -XX:+HeapDumpOnOutOfMemoryError
- -XX:HeapDumpPath=./ (路径)
示例代码:
public class OOMTest {
public static List<Object> list = new ArrayList<>();
// JVM设置
// ‐Xms10M ‐Xmx10M ‐XX:+PrintGCDetails ‐XX:+HeapDumpOnOutOfMemoryError ‐XX:HeapDumpPath=D:jvm.dump
public static void main(String[] args) {
List<Object> list = new ArrayList<>();
int i = 0;
int j = 0;
while (true) {
list.add(new User(i++, UUID.randomUUID().toString()));
new User(j‐‐, UUID.randomUUID().toString());
}
}
}
可以用jvisualvm命令工具导入该dump文件分析

Jstack
用jstack加进程id查找死锁,见如下示例
public class DeadLockTest {
private static Object lock1 = new Object();
private static Object lock2 = new Object();
public static void main(String[] args) {
new Thread(() ‐> {
synchronized (lock1) {
try {
System.out.println("thread1 begin");
11 Thread.sleep(5000);
}
catch (InterruptedException e) {
}
synchronized (lock2) {
System.out.println("thread1 end");
}
}
}
).start();
new Thread(() ‐> {
synchronized (lock2) {
try {
System.out.println("thread2 begin");
Thread.sleep(5000);
}
catch (InterruptedException e) {
}
synchronized (lock1) {
System.out.println("thread2 end");
}
}
}
).start();
System.out.println("main thread end");
}
}

"Thread-1" 线程名
prio=5 优先级=5
tid=0x000000001fa9e000 线程id
nid=0x2d64 线程对应的本地线程标识nid
java.lang.Thread.State: BLOCKED 线程状态

还可以用jvisualvm自动检测死锁

远程连接jvisualvm
jvisualvm 安装Visual GC插件教程见文末
启动普通的jar程序JMX端口配置:
java ‐Dcom.sun.management.jmxremote.port=8888 ‐Djava.rmi.server.hostname=192.168.65.60 ‐Dcom.sun.management.jmxremot e.ssl=false ‐Dcom.sun.management.jmxremote.authenticate=false ‐jar microservice‐eureka‐server.jar
PS:
-Dcom.sun.management.jmxremote.port 为远程机器的JMX端口
-Djava.rmi.server.hostname 为远程机器IP
tomcat的JMX配置:在catalina.sh文件里的最后一个JAVA_OPTS的赋值语句下一行增加如下配置行
JAVA_OPTS="$JAVA_OPTS ‐Dcom.sun.management.jmxremote.port=8888 ‐Djava.rmi.server.hostname=192.168.50.60 ‐Dcom.sun.management.jmxremote.ssl=false ‐Dcom.sun.management.jmxremote.authenticate=false"
连接时确认下端口是否通畅,可以临时关闭下防火墙
systemctl stop firewalld #临时关闭防火墙
jstack找出占用cpu最高的线程堆栈信息
package com.tuling.jvm;
/**
* 运行此代码,cpu会飙高
*/
public class Math {
public static final int initData = 666;
public static User user = new User();
public int compute() {
//一个方法对应一块栈帧内存区域
int a = 1;
int b = 2;
int c = (a + b) * 10;
return c;
}
public static void main(String[] args) {
Math math = new Math();
while (true){
math.compute();
}
}
}
1,使用命令top -p

2,按H,获取每个线程的内存情况

3,找到内存和cpu占用最高的线程tid,比如19664
4,转为十六进制得到 0x4cd0,此为线程id的十六进制表示
5,执行 jstack 19663|grep -A 10 4cd0,得到线程堆栈信息中 4cd0 这个线程所在行的后面10行,从堆栈中可以发现导致cpu飙高的调用方法

6,查看对应的堆栈信息找出可能存在问题的代码
Jinfo
查看正在运行的Java应用程序的扩展参数
查看jvm的参数

查看java系统参数

Jstat
jstat命令可以查看堆内存各部分的使用量,以及加载类的数量。
命令的格式如下:
jstat [-命令选项] [vmid] [间隔时间(毫秒)] [查询次数]
注意:使用的jdk版本是jdk8
垃圾回收统计
jstat -gc pid 最常用,可以评估程序内存使用及GC压力整体情况

- S0C:第一个幸存区的大小,单位KB
- S1C:第二个幸存区的大小
- S0U:第一个幸存区的使用大小
- S1U:第二个幸存区的使用大小
- EC:伊甸园区的大小
- EU:伊甸园区的使用大小
- OC:老年代大小
- OU:老年代使用大小
- MC:方法区大小(元空间)
- MU:方法区使用大小
- CCSC:压缩类空间大小
- CCSU:压缩类空间使用大小
- YGC:年轻代垃圾回收次数
- YGCT:年轻代垃圾回收消耗时间,单位s
- FGC:老年代垃圾回收次数
- FGCT:老年代垃圾回收消耗时间,单位s
- GCT:垃圾回收消耗总时间,单位s
堆内存统计

- NGCMN:新生代最小容量
- NGCMX:新生代最大容量
- NGC:当前新生代容量
- S0C:第一个幸存区大小
- S1C:第二个幸存区的大小
- EC:伊甸园区的大小
- OGCMN:老年代最小容量
- OGCMX:老年代最大容量
- OGC:当前老年代大小
- OC:当前老年代大小
- MCMN:最小元数据容量
- MCMX:最大元数据容量
- MC:当前元数据空间大小
- CCSMN:最小压缩类空间大小
- CCSMX:最大压缩类空间大小
- CCSC:当前压缩类空间大小
- YGC:年轻代gc次数
- FGC:老年代GC次数
新生代垃圾回收统计

- S0C:第一个幸存区的大小
- S1C:第二个幸存区的大小
- S0U:第一个幸存区的使用大小
- S1U:第二个幸存区的使用大小
- TT:对象在新生代存活的次数
- MTT:对象在新生代存活的最大次数
- DSS:期望的幸存区大小
- EC:伊甸园区的大小
- EU:伊甸园区的使用大小
- YGC:年轻代垃圾回收次数
- YGCT:年轻代垃圾回收消耗时间
新生代内存统计

- NGCMN:新生代最小容量
- NGCMX:新生代最大容量
- NGC:当前新生代容量
- S0CMX:最大幸存1区大小
- S0C:当前幸存1区大小
- S1CMX:最大幸存2区大小
- S1C:当前幸存2区大小
- ECMX:最大伊甸园区大小
- EC:当前伊甸园区大小
- YGC:年轻代垃圾回收次数
- FGC:老年代回收次数
老年代垃圾回收统计

- MC:方法区大小
- MU:方法区使用大小
- CCSC:压缩类空间大小
- CCSU:压缩类空间使用大小
- OC:老年代大小
- OU:老年代使用大小
- YGC:年轻代垃圾回收次数
- FGC:老年代垃圾回收次数
- FGCT:老年代垃圾回收消耗时间
- GCT:垃圾回收消耗总时间
老年代内存统计

- OGCMN:老年代最小容量
- OGCMX:老年代最大容量
- OGC:当前老年代大小
- OC:老年代大小
- YGC:年轻代垃圾回收次数
- FGC:老年代垃圾回收次数
- FGCT:老年代垃圾回收消耗时间
- GCT:垃圾回收消耗总时间
元数据空间统计

- MCMN:最小元数据容量
- MCMX:最大元数据容量
- MC:当前元数据空间大小
- CCSMN:最小压缩类空间大小
- CCSMX:最大压缩类空间大小
- CCSC:当前压缩类空间大小
- YGC:年轻代垃圾回收次数
- FGC:老年代垃圾回收次数
- FGCT:老年代垃圾回收消耗时间
- GCT:垃圾回收消耗总时间

- S0:幸存1区当前使用比例
- S1:幸存2区当前使用比例
- E:伊甸园区使用比例
- O:老年代使用比例
- M:元数据区使用比例
- CCS:压缩使用比例
- YGC:年轻代垃圾回收次数
- FGC:老年代垃圾回收次数
- FGCT:老年代垃圾回收消耗时间
- GCT:垃圾回收消耗总时间
JVM运行情况预估
用 jstat gc -pid 命令可以计算出如下一些关键数据,有了这些数据就可以采用之前介绍过的优化思路,先给自己的系统设置一些初始性的JVM参数,比如堆内存大小,年轻代大小,Eden和Survivor的比例,老年代的大小,大对象的阈值,大龄对象进入老年代的阈值等。
年轻代对象增长的速率
可以执行命令 jstat -gc pid 1000 10 (每隔1秒执行1次命令,共执行10次),通过观察EU(eden区的使用)来估算每秒eden大概新增多少对象,如果系统负载不高,可以把频率1秒换成1分钟,甚至10分钟来观察整体情况。注意,一般系统可能有高峰期和日常期,所以需要在不同的时间分别估算不同情况下对象增长速率。
Young GC的触发频率和每次耗时
知道年轻代对象增长速率我们就能推根据eden区的大小推算出Young GC大概多久触发一次,Young GC的平均耗时可以通过 YGCT/YGC 公式算出,根据结果我们大概就能知道系统大概多久会因为Young GC的执行而卡顿多久。
每次Young GC后有多少对象存活和进入老年代
这个因为之前已经大概知道Young GC的频率,假设是每5分钟一次,那么可以执行命令 jstat -gc pid 300000 10 ,观察每次结果eden,survivor和老年代使用的变化情况,在每次gc后eden区使用一般会大幅减少,survivor和老年代都有可能增长,这些增长的对象就是每次 Young GC后存活的对象,同时还可以看出每次Young GC后进去老年代大概多少对象,从而可以推算出老年代对象增长速率。
Full GC的触发频率和每次耗时
知道了老年代对象的增长速率就可以推算出Full GC的触发频率了,Full GC的每次耗时可以用公式 FGCT/FGC 计算得出。
优化思路其实简单来说就是尽量让每次Young GC后的存活对象小于Survivor区域的50%,都留存在年轻代里。尽量别让对象进入老年代。尽量减少Full GC的频率,避免频繁Full GC对JVM性能的影响。
阿里巴巴Arthas详解
Arthas 是 Alibaba 在 2018 年 9 月开源的 Java 诊断工具。支持 JDK6+,采用命令行交互模式,可以方便的定位和诊断线上程序运行问题。Arthas 官方文档十分详细,详见:
https://alibaba.github.io/arthas
Arthas使用场景
得益于 Arthas 强大且丰富的功能,让 Arthas 能做的事情超乎想象。下面仅仅列举几项常见的使用情况,更多的使用场景可以在熟悉了 Arthas 之后自行探索。
-
是否有一个全局视角来查看系统的运行状况?
-
为什么 CPU 又升高了,到底是哪里占用了 CPU ?
-
运行的多线程有死锁吗?有阻塞吗?
-
程序运行耗时很长,是哪里耗时比较长呢?如何监测呢?
-
这个类从哪个 jar 包加载的?为什么会报各种类相关的 Exception?
-
我改的代码为什么没有执行到?难道是我没 commit?分支搞错了?
-
遇到问题无法在线上 debug,难道只能通过加日志再重新发布吗?
-
有什么办法可以监控到 JVM 的实时运行状态?
Arthas使用
# github下载arthas
wget https://alibaba.github.io/arthas/arthas‐boot.jar
# 或者 Gitee 下载
wget https://arthas.gitee.io/arthas‐boot.jar
用java -jar运行即可,可以识别机器上所有Java进程(我们这里之前已经运行了一个Arthas测试程序,代码见下方)
package com.tuling.jvm;
import java.util.HashSet;
public class Arthas {
private static HashSet hashSet = new HashSet();
public static void main(String[] args) {
10 // 模拟 CPU 过高
cpuHigh();
// 模拟线程死锁
deadThread();
// 不断的向 hashSet 集合增加数据
addHashSetThread();
}
/**
* 不断的向 hashSet 集合添加数据
*/
public static void addHashSetThread() {
// 初始化常量
new Thread(() ‐> {
int count = 0;
while (true) {
try {
hashSet.add("count" + count);
Thread.sleep(1000);
count++;
}
catch (InterruptedException e) {
e.printStackTrace();
}
}
}
).start();
}
public static void cpuHigh() {
new Thread(() ‐> {
while (true) {
}
}
).start();
}
/**
* 死锁
*/
private static void deadThread() {
/** 创建资源 */
Object resourceA = new Object();
Object resourceB = new Object();
// 创建线程
Thread threadA = new Thread(() ‐> {
synchronized (resourceA) {
System.out.println(Thread.currentThread() + " get ResourceA");
try {
Thread.sleep(1000);
}
catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println(Thread.currentThread() + "waiting get resourceB");
synchronized (resourceB) {
System.out.println(Thread.currentThread() + " get resourceB");
}
}
}
);
Thread threadB = new Thread(() ‐> {
synchronized (resourceB) {
System.out.println(Thread.currentThread() + " get ResourceB");
try {
Thread.sleep(1000);
}
catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println(Thread.currentThread() + "waiting get resourceA");
synchronized (resourceA) {
System.out.println(Thread.currentThread() + " get resourceA");
}
}
}
);
threadA.start();
threadB.start();
}
}
选择进程序号1,进入进程信息操作

输入dashboard可以查看整个进程的运行情况,线程、内存、GC、运行环境信息:

输入thread可以查看线程详细情况

输入 thread加上线程ID 可以查看线程堆栈

输入 thread -b 可以查看线程死锁

输入 jad加类的全名 可以反编译,这样可以方便我们查看线上代码是否是正确的版本

使用 ognl 命令可以查看线上系统变量的值,甚至可以修改变量的值
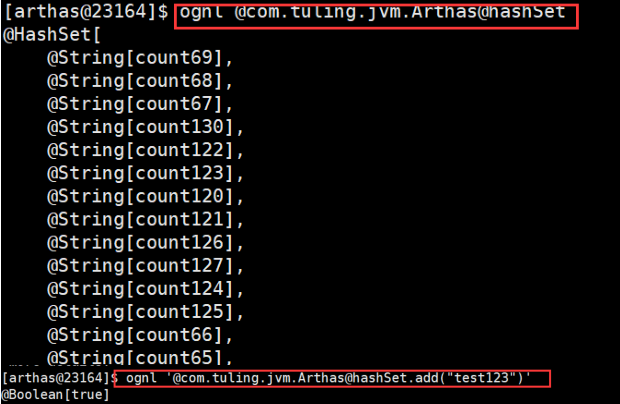
更多命令使用可以用help命令查看,或查看文档:https://alibaba.github.io/arthas/commands.html#arthas
GC日志详解
对于java应用我们可以通过一些配置把程序运行过程中的gc日志全部打印出来,然后分析gc日志得到关键性指标,分析GC原因,调优JVM参数。
打印GC日志方法,在JVM参数里增加参数,%t 代表时间
‐Xloggc:./gc‐%t.log ‐XX:+PrintGCDetails ‐XX:+PrintGCDateStamps ‐XX:+PrintGCTimeStamps ‐XX:+PrintGCCause
‐XX:+UseGCLogFileRotation ‐XX:NumberOfGCLogFiles=10 ‐XX:GCLogFileSize=100M
Tomcat则直接加在JAVA_OPTS变量里。
如何分析GC日志
运行程序加上对应gc日志
java ‐jar ‐Xloggc:./gc‐%t.log ‐XX:+PrintGCDetails ‐XX:+PrintGCDateStamps ‐XX:+PrintGCTimeStamps ‐XX:+PrintGCCause
‐XX:+UseGCLogFileRotation ‐XX:NumberOfGCLogFiles=10 ‐XX:GCLogFileSize=100M microservice‐eureka‐server.jar
下图中是我截取的JVM刚启动的一部分GC日志
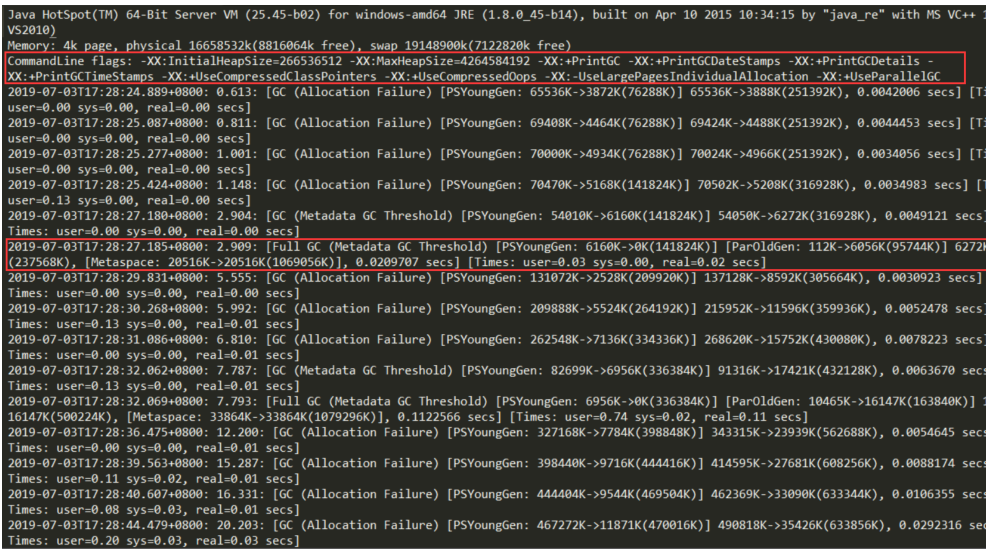
我们可以看到图中第一行红框,是项目的配置参数。这里不仅配置了打印GC日志,还有相关的VM内存参数。
第二行红框中的是在这个GC时间点发生GC之后相关GC情况。
1、对于2.909: 这是从jvm启动开始计算到这次GC经过的时间,前面还有具体的发生时间日期。
2、Full GC(Metadata GC Threshold)指这是一次full gc,括号里是gc的原因, PSYoungGen是年轻代的GC,ParOldGen是老年代的GC,Metaspace是元空间的GC
3、 6160K->0K(141824K),这三个数字分别对应GC之前占用年轻代的大小,GC之后年轻代占用,以及整个年轻代的大小。
4、112K->6056K(95744K),这三个数字分别对应GC之前占用老年代的大小,GC之后老年代占用,以及整个老年代的大小。
5、6272K->6056K(237568K),这三个数字分别对应GC之前占用堆内存的大小,GC之后堆内存占用,以及整个堆内存的大小。
6、20516K->20516K(1069056K),这三个数字分别对应GC之前占用元空间内存的大小,GC之后元空间内存占用,以及整个元空间内存的大小。
7、0.0209707是该时间点GC总耗费时间。
从日志可以发现几次fullgc都是由于元空间不够导致的,所以我们可以将元空间调大点
java ‐jar ‐Xloggc:./gc‐adjust‐%t.log ‐XX:MetaspaceSize=256M ‐XX:MaxMetaspaceSize=256M ‐XX:+PrintGCDetails ‐XX:+Print GCDateStamps ‐XX:+PrintGCTimeStamps ‐XX:+PrintGCCause ‐XX:+UseGCLogFileRotation ‐XX:NumberOfGCLogFiles=10 ‐XX:GCLogFileSize=100M microservice‐eureka‐server.jar
调整完我们再看下gc日志发现已经没有因为元空间不够导致的fullgc了
对于CMS和G1收集器的日志会有一点不一样,也可以试着打印下对应的gc日志分析下,可以发现gc日志里面的gc步骤跟我们之前讲过的步骤是类似的
public class HeapTest {
byte[] a = new byte[1024 * 100];
//100KB
public static void main(String[] args) throws InterruptedException {
ArrayList<HeapTest> heapTests = new ArrayList<>();
7 while (true) {
heapTests.add(new HeapTest());
Thread.sleep(10);
}
}
}
CMS
‐Xloggc:d:/gc‐cms‐%t.log ‐Xms50M ‐Xmx50M ‐XX:MetaspaceSize=256M ‐XX:MaxMetaspaceSize=256M ‐XX:+PrintGCDetails ‐XX:+P rintGCDateStamps ‐XX:+PrintGCTimeStamps ‐XX:+PrintGCCause ‐XX:+UseGCLogFileRotation ‐XX:NumberOfGCLogFiles=10 ‐XX:GCLogFileSize=100M ‐XX:+UseParNewGC ‐XX:+UseConcMarkSweepGC
G1
‐Xloggc:d:/gc‐g1‐%t.log ‐Xms50M ‐Xmx50M ‐XX:MetaspaceSize=256M ‐XX:MaxMetaspaceSize=256M ‐XX:+PrintGCDetails ‐XX:+Pr intGCDateStamps
‐XX:+PrintGCTimeStamps ‐XX:+PrintGCCause ‐XX:+UseGCLogFileRotation ‐XX:NumberOfGCLogFiles=10 ‐XX:GCLogFileSize=100M ‐XX:+UseG1GC
上面的这些参数,能够帮我们查看分析GC的垃圾收集情况。但是如果GC日志很多很多,成千上万行。就算你一目十行,看完了,脑子也是一片空白。所以我们可以借助一些功能来帮助我们分析,这里推荐一个gceasy(https://gceasy.io),可以上传gc文件,然后他会利用可视化的界面来展现GC情况。具体下图所示

上图我们可以看到年轻代,老年代,以及永久代的内存分配,和最大使用情况。

上图我们可以看到堆内存在GC之前和之后的变化,以及其他信息。
这个工具还提供基于机器学习的JVM智能优化建议,当然现在这个功能需要付费

JVM参数汇总查看命令
java -XX:+PrintFlagsInitial 表示打印出所有参数选项的默认值
java -XX:+PrintFlagsFinal 表示打印出所有参数选项在运行程序时生效的值
附末: jvisualvm安装Visual GC插件
给jdk自带的jvisualvm安装Visual GC插件,遇到We're sorry the java.net site has
closed(我们很抱歉java.net网站已经关闭)
1、找到新的更新地址
visualvm新访问地址:https://visualvm.github.io/index.html

进入“Plugins”,找到对应自己JDK版本的更新地址

2、进入jvisualvm的插件管理
"工具" - "插件"
在"设置"中修改url地址为刚才我们在github上找到的对应我们JDK版本的地址

修改成功后,可用插件即可刷新出来
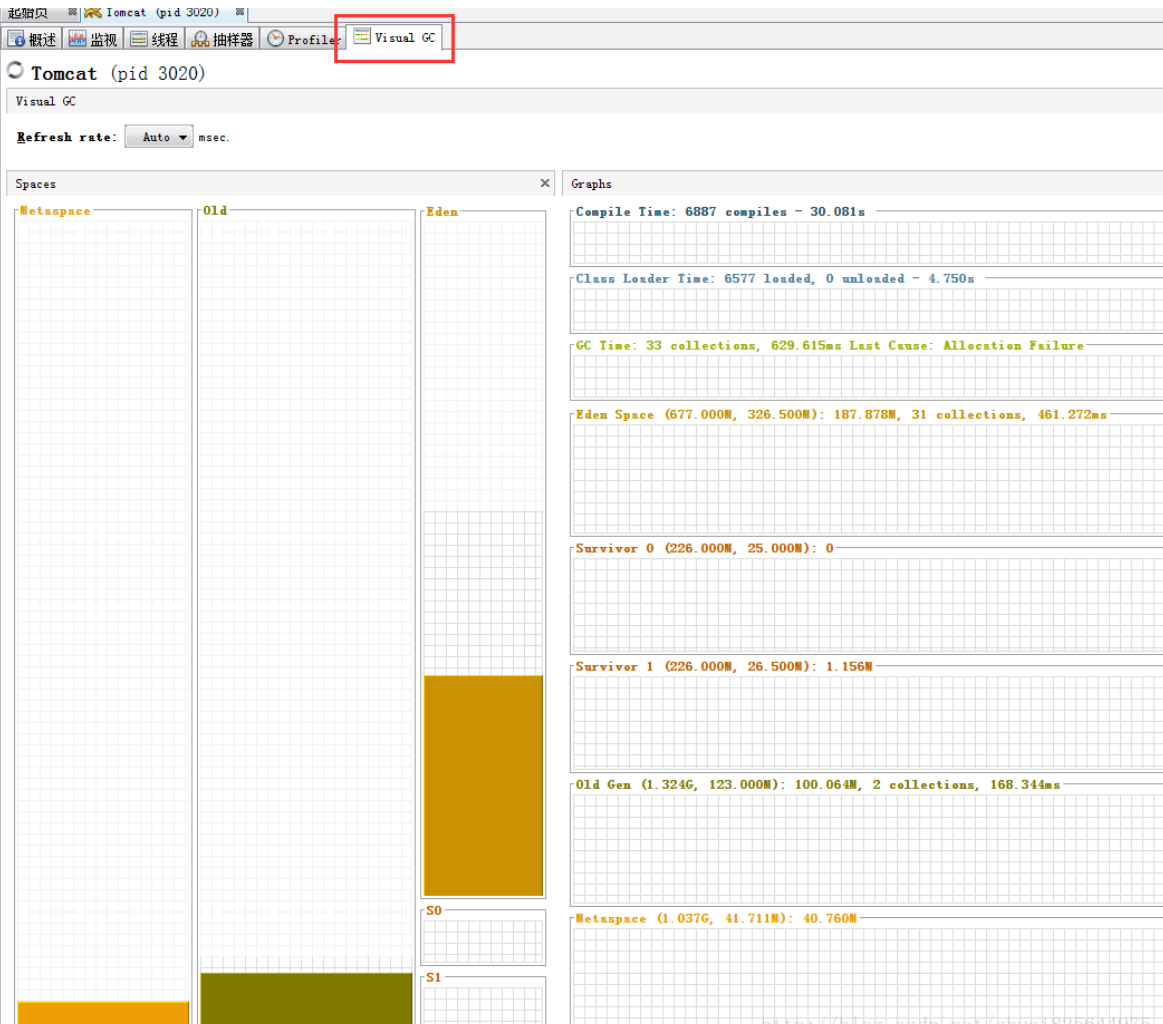
3、安装VisualGC插件

4、重启即可看到VisualGC
文末:
「jvm资料」jvm指令手册见如下 https://www.aliyundrive.com/s/NxhogyFbP5G
「jvm资料」链接: https://pan.baidu.com/s/1Sj97xZzil_YIwHGoBvi8Zw6fuc secret: see after four