HashMap包含一个Node数组,Node可以表示具有以下对象的类:
- int hash
- K key
- V value
- Node next
现在我们来看看它是如何工作的。首先我们将看到hash的执行过程。
Hashing
哈希是使用hashCode()方法将对象转换为整数形式的过程。为了获得更好的HashMap性能,必须正确地编写hashCode()方法。这里我们自己定义一个Key类,这样我就可以重写hashCode()方法来显示不同的场景。我的key class:
//custom Key class to override hashCode() // and equals() method class Key { String key; Key(String key) { this.key = key; } @Override public int hashCode() { return (int)key.charAt(0); } @Override public boolean equals(Object obj) { return key.equals((String)obj); } }
这里重写的hashCode()方法以返回第一个字符的ASCII值。所以,只要key的第一个字符相同,hash代码也将是相同的。你不应该在你的实际代码中这样写。这只是为了演示。由于HashMap也允许空键,所以null的hash之是0。
hashCode()方法
方法用于获取对象的hashCode。Object类的hashCode()方法以整数形式返回对象的内存引用。在HashMap中,hashCode()用于计算bucket,从而计算索引。
equals()方法
equals方法用于检查两个对象是否相等。此方法由对象类提供。您可以在您的类中重写它以提供您自己的实现。
HashMap使用equals()比较key是否相等。如果equals()方法返回true,则它们相等,否则不相等。
buckets(哈希桶)
bucket是HashMap数组的一个元素。它用于存储节点。两个或多个节点可以有同一个bucket。在这种情况下,链表结构用于连接节点。buckets与容量的关系如下:
容量=bucket数量*负载系数
一个bucket可以有多个节点,这取决于hashCode()方法。hashCode()方法越好,bucket的利用率就越高。
HashMap中index的计算
key的哈希值可能足够大以创建数组。生成的哈希值可能在整数的范围内,如果我们为这样一个范围创建数组,那么很容易导致outOfMemoryException。所以我们生成index来最小化数组的大小。执行以下操作来计算索引。
index=hashCode(key)&(n-1)
其中n是存储桶数或数组大小。在我们的示例中,我将考虑n作为默认大小,即16。
初始化空的HashMap:这里,hashmap 大小我们取16。
HashMap map = new HashMap();

插入键值对:在上面的HashMap中放入一个键值对
map.put(new Key("vishal"), 20);
步骤:
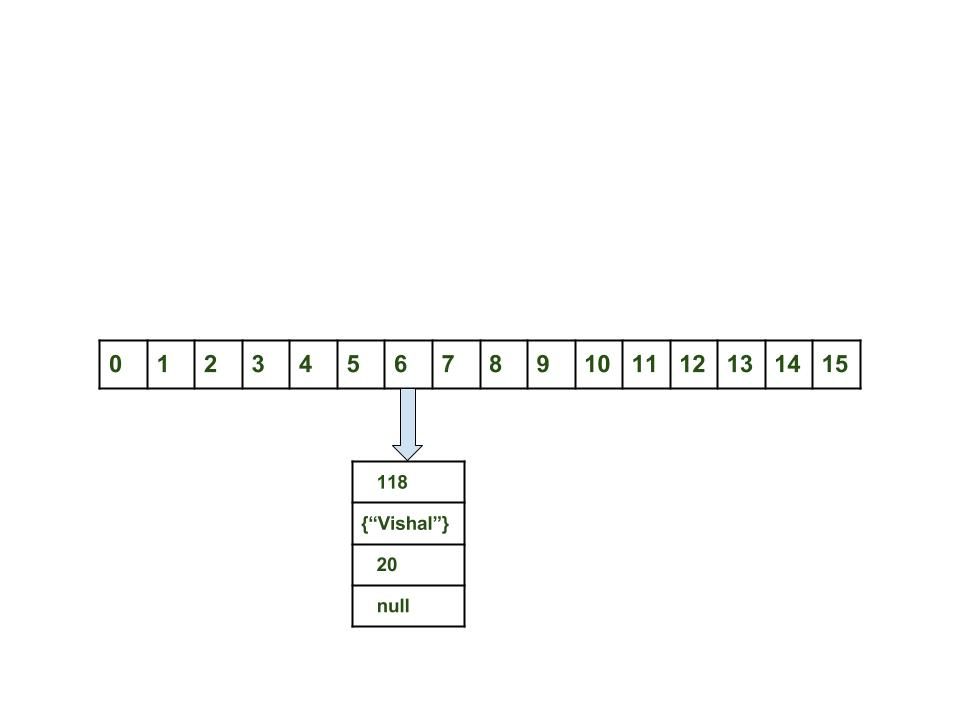
- 计算键{“vishal”}的哈希code。将生成118。
- 计算index为6。
- 将节点对象创建为:
{ int hash = 118 // {"vishal"} is not a string but // an object of class Key Key key = {"vishal"} Integer value = 20 Node next = null }
- 如果没有其他对象,则将此对象放在索引6处。
插入另一个键值对:
map.put(new Key("sachin"), 30);
步骤:
- 计算键{“sachin”}的哈希码。它将生成为115。
- 计算index为3。
- 将节点对象创建为:
{ int hash = 115 Key key = {"sachin"} Integer value = 30 Node next = null }
如果没有其他对象出现,则将此对象放在索引3处。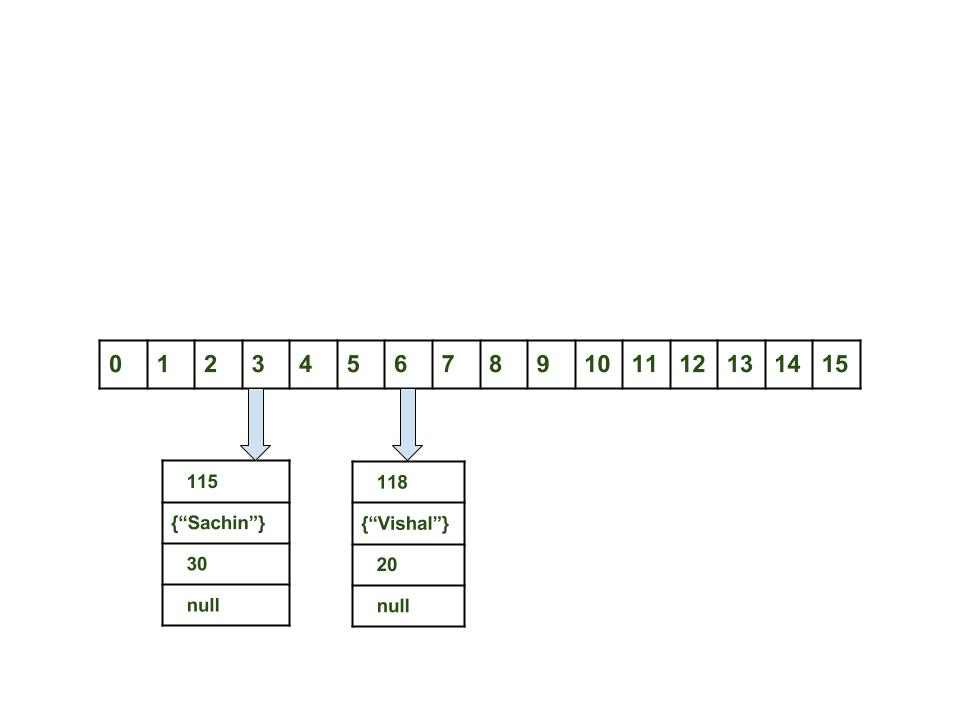
发生碰撞时:现在,再放键值对,
map.put(new Key("vaibhav"), 40);
步骤:
- 计算密钥{“vaibhav”}的哈希码。将生成118。
- 计算index为6。
- 将节点对象创建为:
{ int hash = 118 Key key = {"vaibhav"} Integer value = 40 Node next = null }
- 如果没有其他对象出现,则将此对象放在索引6处。
- 在这种情况下,节点对象是在索引6找到的–这是一个碰撞案例。
- 在这种情况下,通过hashCode()和equals()方法检查两个键是否相同。
- 如果键相同,则将值替换为当前值。否则,通过链表将这个节点对象连接到上一个节点对象,并且两者都存储在索引6中。

使用get()方法
现在让我们尝试一些get方法来获取一个值。get(Key key)方法用于通过键获取值。如果不知道键,则无法获取值。
获取key为sachin的数据:map.get(new Key("sachin"));
步骤:
- 计算密钥{“sachin”}的哈希代码。它将生成为115。
- 计算index为3。
- 转到数组的索引3,比较第一个元素的键和给定的键。如果两者都等于,则返回值,否则检查下一个元素(如果存在)。
- 在我们的例子中,它作为第一个元素被找到,返回值是30。
map.get(new Key("vaibhav"));
步骤:
- 计算密钥{“vaibhav”}的哈希码。将生成118。
- 计算index为6。
- 转到数组的索引6,比较第一个元素的键和给定的键。如果两者都等于,则返回值,否则检查下一个元素(如果存在)。
- 在我们的例子中,它不是作为第一个元素找到的,而node对象的下一个元素不为null。
- 如果node下个元素为null,则返回null。
- 如果node下个不为null,则遍历到第二个元素并重复过程3,直到找不到key或next不为nul
完整代码
// Java program to illustrate // internal working of HashMap import java.util.HashMap; class Key { String key; Key(String key) { this.key = key; } @Override public int hashCode() { int hash = (int)key.charAt(0); System.out.println("hashCode for key: " + key + " = " + hash); return hash; } @Override public boolean equals(Object obj) { return key.equals(((Key)obj).key); } } // Driver class public class GFG { public static void main(String[] args) { HashMap map = new HashMap(); map.put(new Key("vishal"), 20); map.put(new Key("sachin"), 30); map.put(new Key("vaibhav"), 40); System.out.println(); System.out.println("Value for key sachin: " + map.get(new Key("sachin"))); System.out.println("Value for key vaibhav: " + map.get(new Key("vaibhav"))); } }
输出:
hashCode for key: vishal = 118 hashCode for key: sachin = 115 hashCode for key: vaibhav = 118 hashCode for key: sachin = 115 Value for key sachin: 30 hashCode for key: vaibhav = 118 Value for key vaibhav: 40
Java8中的HashMap的增强
我们现在知道,在哈希冲突的情况下,对象作为节点存储在链表和equals()方法用于比较键。在链表中找到正确的key是一个线性操作,因此在最坏的情况下,复杂性变成O(n)。
为了解决这个问题,java8散列元素在达到某个阈值后使用平衡树而不是链表。这意味着HashMap从在链表中存储条目对象开始,但是当散列中的项数大于某个阈值时,哈希将从使用链表变为平衡树,从而将最坏情况下的性能从O(n)提高到O(log n)。
注意点
- 在没有扩容之前,对于put()和get()方法,时间复杂度几乎是恒定的。
- 当发生冲突时,即两个或多个节点的索引相同,节点通过链表连接,即第二个节点被第一个节点引用,第三个节点被第二个节点引用,依此类推。
- 如果给定的键已经存在于HashMap中,则该值将替换为新值。
- key是null的哈希值为0。
- 当获取带有键的对象时,将遍历链表,直到键匹配或在下一个字段中找到null为止。