一些前提数据:
tokens = ['I', 'shot', 'an', 'elephant', 'in', 'my', 'pajamas']
- tokens为将要研究的一句英文句子。
index={(DeT, N): NP, (Det, N, PP): NP, (NP, VP): S, (P, NP): PP, (V, NP): VP, (VP, PP): VP, ('I',): NP, ('an',): Det, ('elephant',): N, ('in',): P, ('my',): Det, ('pajamas',): N, ('shot',): V}
- index为文法的描述。
- numtokens=7(len(tokens))为句子中单词的数量

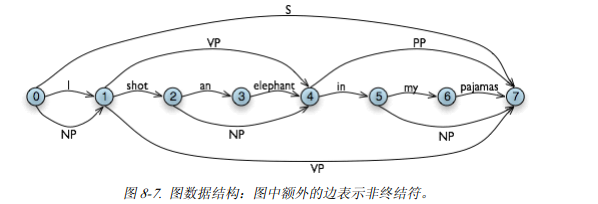
图8.6中为图表的数据结构
在这个算法当中,有一个代表图表数据结构的二维表,我们把他命名为WFST。
经过下面的初始化函数,对WFST进行初始化:
def init_wfst(tokens,grammar): numtokens=len(tokens) wfst=[ [None for i in range(numtokens+1)] for j in range(numtokens+1) ] for i in range(numtokens): productions=grammar.productions(rhs=tokens[i]) wfst[i][i+1]=productions[0].lhs() return wfst
经过初始化之后,我们可以打印WFST,发现已经变成了下面这种情况:
[[None, NP, None, None, None, None, None, None],
[None, None, V, None, None, None, None, None],
[None, None, None, Det, None, None, None, None],
[None, None, None, None, N, None, None, None],
[None, None, None, None, None, P, None, None],
[None, None, None, None, None, None, Det, None],
[None, None, None, None, None, None, None, N],
[None, None, None, None, None, None, None, None]]
WFST1 2 3 4 5 6 7 0 NP . . . . . . 1 . V . . . . . 2 . . Det . . . . 3 . . . N . . . 4 . . . . P . . 5 . . . . . Det . 6 . . . . . . N
上面两个是等价的,只不过下面的这个图更直观,好理解。每相邻两个节点之间是一个词,他们都有自己的词性。
但是这些还远远不够,为了能够更好的体现文法,还需要归约操作,将一开始的图表变成如下这样的形式:
就需要我们有一种算法,去遍历我们现在有的图表结构,来完成这个操作。
书中已经给出了算法的实现,我们需要注意的是,这是一个三角矩阵,不需要每个地方都遍历,同时,算法的难点是,要实现不同的单词数量的跨度,去完成图表WFST的赋值。
书中给出的算法代码为:
def complete_wfst(wfst,tokens, grammar,trace=False): index = dict((p.rhs(),p.lhs()) for p in grammar.productions()) numtokens= len(tokens) for span in range(2, numtokens+1): for start in range(numtokens+1-span): end = start + span for mid in range(start+1, end): nt1,nt2 = wfst[start][mid],wfst[mid][end] if nt1 and nt2 and (nt1,nt2) in index: wfst[start][end]= index[(nt1,nt2)] if trace: print "[%s] %3s[%s] %3s[%s] ==>[%s] %3s[%s]" %(start, nt1, mid,nt2,end, start, index[(nt1,nt2)], end) return wfst
嵌套了很多的循环,其实经过仔细分析,此算法并不难理解。为了更好的理解,可以自己手动演示一下就能理解算法的内涵,如果各位读者看着很难理解,自己走一下程序的步骤就很容易理解了:
span=2:#当值为2的时候,检查两个词之间有没有关系 #range(numtokens+1-span=6)(0~5) start=0: end=start+span=0+2=2 #range(start+1,end)(0+1,2) mid=1: nt1=wfst[0][1],nt2=[1][2] start=1: start=2: end=start+span=2+2=4 #range(start+1,end)(3,4) mid=3: nt1=wfst[2][3],nt2=[3][4] start=3: start=4: start=5: span=3: #range(numtokens+1-span=5)(0~4) start=0: end=start+span=0+3=3 #range(start+1,end)(0+1,3) mid=1: nt1=wfst[0][1],nt2=wfst[1][3] mid=2: nt1=wfst[0][2],nt2=wfst[2][3] start=1: start=2: start=3: span=4: span=5: span=6: span=7: