疯狂创客圈,一个Java 高并发研习社群 【博客园 总入口 】
疯狂创客圈,倾力推出:面试必备 + 面试必备 + 面试必备 的基础原理+实战 书籍 《Netty Zookeeper Redis 高并发实战》

@
写在前面
大家好,我是作者尼恩。目前和几个小伙伴一起,组织了一个高并发的实战社群【疯狂创客圈】。正在开始高并发、亿级流程的 IM 聊天程序 学习和实战
前面,已经完成一个高性能的 Java 聊天程序的四件大事:
接下来,需要进入到分布式开发的环节了。 分布式的中间件,疯狂创客圈的小伙伴们,一致的选择了zookeeper,不仅仅是由于其在大数据领域,太有名了。更重要的是,很多的著名框架,都使用了zk。
**本篇介绍 ZK 的分布式命名服务 ** 中的 节点命名服务和 snowflake 雪花算法。
1.1.1. 集群节点的命名服务
前面讲到,在分布式集群中,可能需要部署的大量的机器节点。在节点少的受,可以人工维护。在量大的场景下,手动维护成本高,考虑到自动部署、运维等等问题,节点的命名,最好由系统自动维护。
节点的命名,主要是为节点进行唯一编号。主要的诉求是,不同节点的编号,是绝对的不能重复。一旦编号重复,就会导致有不同的节点碰撞,导致集群异常。
有以下两个方案,可供生成集群节点编号:
(1)使用数据库的自增ID特性,用数据表,存储机器的mac地址或者ip来维护。
(2)使用ZooKeeper持久顺序节点的次序特性。来维护节点的编号。
这里,我们采用第二种,通过ZooKeeper持久顺序节点特性,来配置维护节点的编号NODEID。
集群节点命名服务的基本流程是:
(1)启动节点服务,连接ZooKeeper, 检查命名服务根节点根节点是否存在,如果不存在就创建系统根节点。
(2)在根节点下创建一个临时顺序节点,取回顺序号做节点的NODEID。如何临时节点太多,可以根据需要,删除临时节点。
基本的算法,和生成分布式ID的大部分是一致的,主要的代码如下:
package com.crazymakercircle.zk.NameService;
import com.crazymakercircle.util.ObjectUtil;
import com.crazymakercircle.zk.ZKclient;
import lombok.Data;
import org.apache.curator.framework.CuratorFramework;
import org.apache.zookeeper.CreateMode;
/**
* create by 尼恩 @ 疯狂创客圈
**/
@Data
public class SnowflakeIdWorker {
//Zk客户端
private CuratorFramework client = null;
//工作节点的路径
private String pathPrefix = "/test/IDMaker/worker-";
private String pathRegistered = null;
public static SnowflakeIdWorker instance = new SnowflakeIdWorker();
private SnowflakeIdWorker() {
instance.client = ZKclient.instance.getClient();
instance.init();
}
// 在zookeeper中创建临时节点并写入信息
public void init() {
// 创建一个 ZNode 节点
// 节点的 payload 为当前worker 实例
try {
byte[] payload = ObjectUtil.Object2JsonBytes(this);
pathRegistered = client.create()
.creatingParentsIfNeeded()
.withMode(CreateMode.EPHEMERAL_SEQUENTIAL)
.forPath(pathPrefix, payload);
} catch (Exception e) {
e.printStackTrace();
}
}
public long getId() {
String sid=null;
if (null == pathRegistered) {
throw new RuntimeException("节点注册失败");
}
int index = pathRegistered.lastIndexOf(pathPrefix);
if (index >= 0) {
index += pathPrefix.length();
sid= index <= pathRegistered.length() ? pathRegistered.substring(index) : null;
}
if(null==sid)
{
throw new RuntimeException("节点ID生成失败");
}
return Long.parseLong(sid);
}
}
1.1.2. snowflake 的ID算法改造
Twitter的snowflake 算法,是一种著名的分布式服务器用户ID生成算法。SnowFlake算法所生成的ID 是一个64bit的长整形数字。这个64bit被划分成四部分,其中后面三个部分,分别表示时间戳、机器编码、序号。
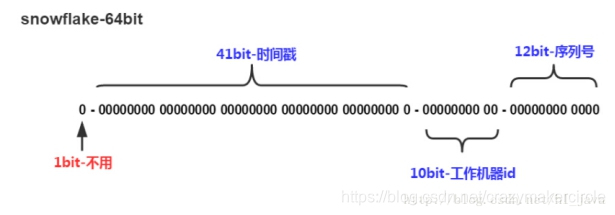
(1)第一位
占用1bit,其值始终是0,没有实际作用。
(2)时间戳
占用41bit,精确到毫秒,总共可以容纳约69年的时间。
(3)工作机器id
占用10bit,最多可以容纳1024个节点。
(4)序列号
占用12bit,最多可以累加到4095。这个值在同一毫秒同一节点上从0开始不断累加。
总体来说,在工作节点达到1024顶配的场景下,SnowFlake算法在同一毫秒内最多可以生成多少个全局唯一ID呢?这是一个简单的乘法:
同一毫秒的ID数量 = 1024 X 4096 = 4194304
400多万个ID,这个数字在绝大多数并发场景下都是够用的。
snowflake 算法中,第三个部分是工作机器ID,可以结合上一节的命名方法,并通过Zookeeper管理workId,免去手动频繁修改集群节点,去配置机器ID的麻烦。
/**
* create by 尼恩 @ 疯狂创客圈
**/
public class SnowflakeIdGenerator {
/**
* 单例
*/
public static SnowflakeIdGenerator instance =
new SnowflakeIdGenerator();
/**
* 初始化单例
*
* @param workerId 节点Id,最大8091
* @return the 单例
*/
public synchronized void init(long workerId) {
if (workerId > MAX_WORKER_ID) {
// zk分配的workerId过大
throw new IllegalArgumentException("woker Id wrong: " + workerId);
}
instance.workerId = workerId;
}
private SnowflakeIdGenerator() {
}
/**
* 开始使用该算法的时间为: 2017-01-01 00:00:00
*/
private static final long START_TIME = 1483200000000L;
/**
* worker id 的bit数,最多支持8192个节点
*/
private static final int WORKER_ID_BITS = 13;
/**
* 序列号,支持单节点最高每毫秒的最大ID数1024
*/
private final static int SEQUENCE_BITS = 10;
/**
* 最大的 worker id ,8091
* -1 的补码(二进制全1)右移13位, 然后取反
*/
private final static long MAX_WORKER_ID = ~(-1L << WORKER_ID_BITS);
/**
* 最大的序列号,1023
* -1 的补码(二进制全1)右移10位, 然后取反
*/
private final static long MAX_SEQUENCE = ~(-1L << SEQUENCE_BITS);
/**
* worker 节点编号的移位
*/
private final static long APP_HOST_ID_SHIFT = SEQUENCE_BITS;
/**
* 时间戳的移位
*/
private final static long TIMESTAMP_LEFT_SHIFT = WORKER_ID_BITS + APP_HOST_ID_SHIFT;
/**
* 该项目的worker 节点 id
*/
private long workerId;
/**
* 上次生成ID的时间戳
*/
private long lastTimestamp = -1L;
/**
* 当前毫秒生成的序列
*/
private long sequence = 0L;
/**
* Next id long.
*
* @return the nextId
*/
public Long nextId() {
return generateId();
}
/**
* 生成唯一id的具体实现
*/
private synchronized long generateId() {
long current = System.currentTimeMillis();
if (current < lastTimestamp) {
// 如果当前时间小于上一次ID生成的时间戳,说明系统时钟回退过,出现问题返回-1
return -1;
}
if (current == lastTimestamp) {
// 如果当前生成id的时间还是上次的时间,那么对sequence序列号进行+1
sequence = (sequence + 1) & MAX_SEQUENCE;
if (sequence == MAX_SEQUENCE) {
// 当前毫秒生成的序列数已经大于最大值,那么阻塞到下一个毫秒再获取新的时间戳
current = this.nextMs(lastTimestamp);
}
} else {
// 当前的时间戳已经是下一个毫秒
sequence = 0L;
}
// 更新上次生成id的时间戳
lastTimestamp = current;
// 进行移位操作生成int64的唯一ID
//时间戳右移动23位
long time = (current - START_TIME) << TIMESTAMP_LEFT_SHIFT;
//workerId 右移动10位
long workerId = this.workerId << APP_HOST_ID_SHIFT;
return time | workerId | sequence;
}
/**
* 阻塞到下一个毫秒
*/
private long nextMs(long timeStamp) {
long current = System.currentTimeMillis();
while (current <= timeStamp) {
current = System.currentTimeMillis();
}
return current;
}
}
上面的代码中,大量的使用到了位运算。
如果对位运算不清楚,估计很难看懂上面的代码。
这里需要强调一下,-1 的8位二进制编码为 1111 1111,也就是全1。
为什么呢?
因为,8位二进制场景下,-1的原码是1000 0001,反码是 1111 1110,补码是反码加1。计算后的结果是,-1 的二进制编码为全1。16位、32位、64位的-1,二进制的编码也是全1。
上面用到的二进制位移算法,以及二进制按位或的算法,都比较简单。如果不懂,可以去查看java的基础书籍。
总的来说,以上的代码,是一个相对比较简单的snowflake实现版本,关键的算法解释如下:
(1)在单节点上获得下一个ID,使用Synchronized控制并发,而非CAS的方式,是因为CAS不适合并发量非常高的场景。
(2)如果当前毫秒在一台机器的序列号已经增长到最大值4095,则使用while循环等待直到下一毫秒。
(3)如果当前时间小于记录的上一个毫秒值,则说明这台机器的时间回拨了,抛出异常。
SnowFlake算法的优点:
(1)生成ID时不依赖于数据库,完全在内存生成,高性能高可用。
(2)容量大,每秒可生成几百万ID。
(3)ID呈趋势递增,后续插入数据库的索引树的时候,性能较高。
SnowFlake算法的缺点:
(1)依赖于系统时钟的一致性。如果某台机器的系统时钟回拨,有可能造成ID冲突,或者ID乱序。
(2)还有,在启动之前,如果这台机器的系统时间回拨过,那么有可能出现ID重复的危险。
写在最后
下一篇:基于zk,实现分布式锁。
疯狂创客圈 亿级流量 高并发IM 实战 系列
- Java (Netty) 聊天程序【 亿级流量】实战 开源项目实战
- Netty 源码、原理、JAVA NIO 原理
- Java 面试题 一网打尽
- 疯狂创客圈 【 博客园 总入口 】