SQL分类:
DDL-----数据定义语言(CREATE--创建,ALTER--修改. DROP--删除表,DECLARE--声明)
DML-----数据定义语言(SELECT--查询,DELECT--删除数据,UPDATE--更新,INSERT--插入)
DCL-----数据定义语言(GRANT--权限,REVOKE--取消,COMMIT--提交,ROLLBACK--回滚)
一:mysql数据类型
1.1 整数类型-----最基本的数据类型
严格数值数据类型(INTEGER、SMALLINT、DECIMAL和NUMERIC)
| 类型 | 大小 | 范围(有符号) | 范围(无符号) | 用途 |
| TINYINT | 1 字节 | (-128,127) | (0,255) | 小整数值 |
| SMALLINT | 2 字节 | (-32 768,32 767) | (0,65 535) | 大整数值 |
| MEDIUMINT | 3 字节 | (-8 388 608,8 388 607) | (0,16 777 215) | 大整数值 |
| INT或INTEGER | 4 字节 | (-2 147 483 648,2 147 483 647) | (0,4 294 967 295) | 大整数值 |
| BIGINT | 8 字节 | (-9 233 372 036 854 775 808,9 223 372 036 854 775 807) | (0,18 446 744 073 709 551 615) | 极大整数值 |
1.2 浮点数类型和定点数类型
近似数值数据类型(FLOAT、REAL和DOUBLE PRECISION)
| FLOAT | 4 字节 | (-3.402 823 466 E+38,-1.175 494 351 E-38),0,(1.175 494 351 E-38,3.402 823 466 351 E+38) | 0,(1.175 494 351 E-38,3.402 823 466 E+38) | 单精度 浮点数值 |
| DOUBLE | 8 字节 | (-1.797 693 134 862 315 7 E+308,-2.225 073 858 507 201 4 E-308),0,(2.225 073 858 507 201 4 E-308,1.797 693 134 862 315 7 E+308) | 0,(2.225 073 858 507 201 4 E-308,1.797 693 134 862 315 7 E+308) | 双精度 浮点数值 |
| DECIMAL |
对DECIMAL(M,D) 如果M>D,为M+2否则为D+2 |
依赖于M和D的值 | 依赖于M和D的值 | 小数值 |
1.3日期与时类型
表示时间值的日期和时间类型为DATETIME、DATE、TIMESTAMP、TIME和YEAR。
每个时间类型有一个有效值范围和一个"零"值,当指定不合法的MySQL不能表示的值时使用"零"值。
TIMESTAMP类型有专有的自动更新特性,将在后面描述。
| 类型 | 大小 | 范围 | 格式 | 用途 |
| DATE | 3字节 | 1000-01-01/9999-12-31 | YYYY-MM-DD | 日期值 |
| TIME | 3字节 | '-838:59:59'/'838:59:59' | HH:MM:SS | 时间值或持续时间 |
| YEAR | 1字节 | 1901/2155 | YYYY | 年份值 |
| DATETIME | 8字节 | 1000-01-01 00:00:00/9999-12-31 23:59:59 | YYYY-MM-DD HH:MM:SS | 混合日期和时间值 |
| TIMESTAMP | 4字节 |
1970-01-01 00:00:00/2038 结束时间是第 2147483647 秒,北京时间 2038-1-19 11:14:07,格林尼治时间 2038年1月19日 凌晨 03:14:07 |
YYYYMMDD HHMMSS | 混合日期和时间值,时间戳 |
1.4 字符串类型
字符串类型指CHAR、VARCHAR、BINARY、VARBINARY、BLOB、TEXT、ENUM和SET。该节描述了这些类型如何工作以及如何在查询中使用这些类型。
| 类型 | 大小 | 用途 |
| CHAR | 0-255字节 | 定长字符串 |
| VARCHAR | 0-65535 字节 | 变长字符串 |
| TINYBLOB | 0-255字节 | 不超过 255 个字符的二进制字符串 |
| TINYTEXT | 0-255字节 | 短文本字符串 |
| BLOB | 0-65 535字节 | 二进制形式的长文本数据 |
| TEXT | 0-65 535字节 | 长文本数据 |
| MEDIUMBLOB | 0-16 777 215字节 | 二进制形式的中等长度文本数据 |
| MEDIUMTEXT | 0-16 777 215字节 | 中等长度文本数据 |
| LONGBLOB | 0-4 294 967 295字节 | 二进制形式的极大文本数据 |
| LONGTEXT | 0-4 294 967 295字节 | 极大文本数据 |
CHAR和VARCHAR类型类似,但它们保存和检索的方式不同。它们的最大长度和是否尾部空格被保留等方面也不同。在存储或检索过程中不进行大小写转换。
BINARY和VARBINARY类类似于CHAR和VARCHAR,不同的是它们包含二进制字符串而不要非二进制字符串。也就是说,它们包含字节字符串而不是字符字符串。这说明它们没有字符集,并且排序和比较基于列值字节的数值值。
BLOB是一个二进制大对象,可以容纳可变数量的数据。有4种BLOB类型:TINYBLOB、BLOB、MEDIUMBLOB和LONGBLOB。它们只是可容纳值的最大长度不同。
有4种TEXT类型:TINYTEXT、TEXT、MEDIUMTEXT和LONGTEXT。这些对应4种BLOB类型,有相同的最大长度和存储需求。
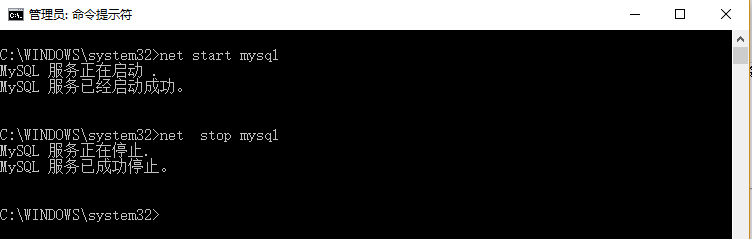
二:mysql服务的启动和停止
net stop mysql --启动 net start mysql --停止
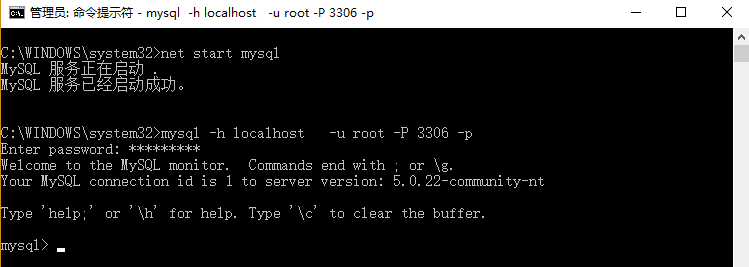
三 :登录mysql
mysql -h localhost -u root -P 3306 -p
password: *******
-h mysql连接地址
-u mysql登录用户名
-P mysql连接端口(默认为 3306)
-p mysql登录密码(不建议直接在后面写密码[明文])
四:密码直接登录mysql
mysql -h localhost -u root -p 123456
五:退出mysql
mysql>exit;

六:查看数据库
mysql>SHOW DATABASES;

七:创建和删除数据库
mysql>CREATE { DATABASE | SCHEMA } [ IF NOT EXISTS ] db_name [DEFAULT] CHARACTER SET [ = ] charset_name; --创建
mysql>DROP DATABASE db_name; --删除


八:查看数据库存储引擎、使用数据库、查看当前使用的数据库
mysql>SHOW ENGINES; --查看存储引擎 mysql>USE db_name; --使用数据库 mysql>SELECT DATABASE(); --查看当前使用的数据库

扩展:

8.1 g 或 G 让结果显示更显的美观。
8.2 使用SHOW 语句查询mysql支持的存储引擎:
mysql>SHOW VARIABLES LIKE 'have%'; --查询支持have开头的存储引擎
九:显示库中的数据表
mysql>USE db_name; --使用数据库 mysql>SHOW TABLES; --显示数据表

十:创建和删除数据表
mysql>CREATE TABLE [IF NOT EXISTS] table_name(column_name column_type...) --创建 mysql>DROP TABLE table_name; --删除
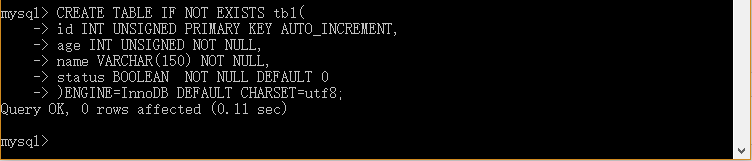
实例10.1:
mysql> CREATE TABLE [IF NOT EXISTS] tb1(
>id INT UNSIGNED PRIMARY KEY AUTO_INCREMENT,
>age INT UNSIGNED NOT NULL,
>name VARCHAR(150) NOT NULL,
>status BOOLEAN NOT NULL DEFAULT 0
>)ENGINE=InnoDB DEFAULT CHARSET=utf8;
实例解析:
- 如果你不想字段为 NULL 可以设置字段的属性为 NOT NULL, 在操作数据库时如果输入该字段的数据为NULL ,就会报错。
- AUTO_INCREMENT定义列为自增的属性,一般用于主键,数值会自动加1。
- PRIMARY KEY关键字用于定义列为主键。 您可以使用多列来定义主键,列间以逗号分隔。
- UNSIGNED无符号。
- DEFAULT 设置默认值。
- COMMENT 字段或列的注释是用属性comment来添加。
- ENGINE 设置存储引擎,CHARSET 设置编码。
十一:查看数据表的结构
mysql>DESC table_name; mysql>DESCRIBE table_name; mysql>EXPLAIN table_name; mysql>SHOW COLUMNS FROM table_name;

十二:插入数据
mysql>INSERT INTO table_name ( field1, field2,...fieldN )
>VALUES( value1, value2,...valueN );
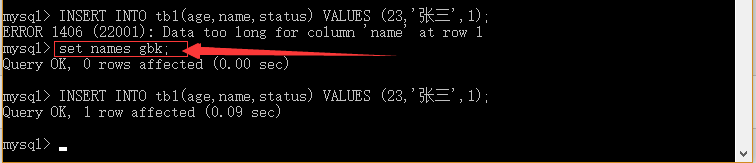
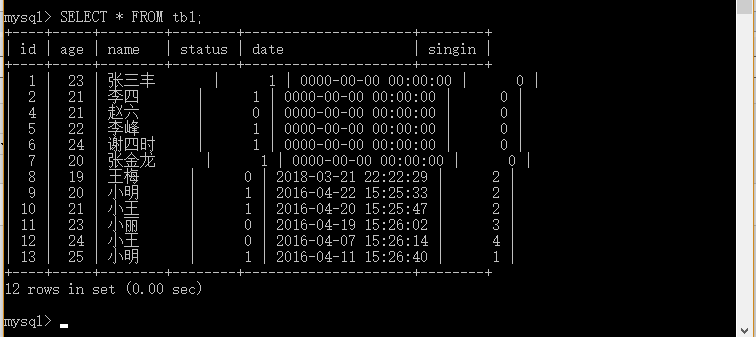
实例12.1: INSERT INTO tb1(age,name,status) VALUES (23,'张三',1);
mysql>INSERT INTO tb1(age,name,status) VALUES (23,'张三',1),(21,'李四',1),(24,'王五',0),(21,'赵六',1),(22,'李峰',1),(24,'谢四时',1),(20,'张金龙',1);
注:如果数据是字符型,必须使用单引号或者双引号,如:"value"。
set names gbk; 确保表中该字段的字符集为中文兼容。
使用箭头标记 -> 不是 SQL 语句的一部分,它仅仅表示一个新行,如果一条SQL语句太长,我们可以通过回车键来创建一个新行来编写 SQL 语句,SQL 语句的命令结束符为分号 ;。
实例解析:
- 在以上实例中,我们并没有提供 id 的数据,因为该字段我们在创建表的时候已经设置它为 AUTO_INCREMENT(自动增加) 属性。 所以,该字段会自动递增而不需要我们去设置。
- status的数据,我们在创建表的时候已经设置它为DEFAULT(默认值)熟属性。所以,该字段在没有提供数据的时候,默认值为:0。
十三:查询数据
mysql>SELECT (column_name,column_name,...) FROM table_name [WHERE Clause] [LIMIT N][ OFFSET M];
实例13.1:
mysql>SELECT * FROM tb1; mysql>SELECT (id,age,name,status) FROM tb1;

- 查询语句中你可以使用一个或者多个表,表之间使用逗号(,)分割,并使用WHERE语句来设定查询条件。
- SELECT 命令可以读取一条或者多条记录。
- 可以使用星号(*)来代替其他字段,SELECT语句会返回表的所有字段数据
- 可以使用 WHERE 语句来包含任何条件。
- 可以使用 LIMIT 属性来设定返回的记录数。
- 可以通过OFFSET指定SELECT语句开始查询的数据偏移量。默认情况下偏移量为0。
十四:WHERE 子句
有条件地从表中选取数据,可将 WHERE 子句添加到 SELECT 语句中。
mysql>SELECT field1, field2,...fieldN FROM table_name1, table_name2...
>[WHERE condition1 [AND [OR]] condition2.....
- 查询语句中你可以使用一个或者多个表,表之间使用逗号, 分割,并使用WHERE语句来设定查询条件。
- 可以在 WHERE 子句中指定任何条件。
- 可以使用 AND 或者 OR 指定一个或多个条件。
- WHERE 子句也可以运用于 SQL 的 DELETE 或者 UPDATE 命令。
- WHERE 子句类似于程序语言中的 if 条件,根据 MySQL 表中的字段值来读取指定的数据。
以下为操作符列表,可用于 WHERE 子句中。
下表中实例假定 A 为 10, B 为 20
| 操作符 | 描述 | 实例 |
| = | 等号,检测两个值是否相等,如果相等返回true | (A = B) 返回false。 |
| <>, != | 不等于,检测两个值是否相等,如果不相等返回true | (A != B) 返回 true。 |
| > | 大于号,检测左边的值是否大于右边的值, 如果左边的值大于右边的值返回true | (A > B) 返回false。 |
| < | 小于号,检测左边的值是否小于右边的值, 如果左边的值小于右边的值返回true | (A < B) 返回 true。 |
| >= | 大于等于号,检测左边的值是否大于或等于右边的值, 如果左边的值大于或等于右边的值返回true | (A >= B) 返回false。 |
| <= | 小于等于号,检测左边的值是否小于于或等于右边的值, 如果左边的值小于或等于右边的值返回true | (A <= B) 返回 true。 |
如果我们想再 MySQL 数据表中读取指定的数据,WHERE 子句是非常有用的。
使用主键来作为 WHERE 子句的条件查询是非常快速的。
如果给定的条件在表中没有任何匹配的记录,那么查询不会返回任何数据。
实例:14.4:
mysql>SELECT * FROM tb1 WHERE name='李四';

实例解析: 读取 tb1表中 name 字段值为 李四 的所有记录
注:MySQL 的 WHERE 子句的字符串比较是不区分大小写的。 你可以使用 BINARY 关键字来设定 WHERE 子句的字符串比较是区分大小写的
十五:UPDATE 查询
修改或更新 MySQL 中的数据,我们可以使用 SQL UPDATE 命令来操作。
mysql>UPDATE table_name SET field1=new-value1, field2=new-value2 [WHERE Clause];
- 可以同时更新一个或多个字段。
- 可以在 WHERE 子句中指定任何条件。
- 可以在一个单独表中同时更新数据。
当你需要更新数据表中指定行的数据时 WHERE 子句是非常有用的。
扩展:
当我们需要将字段中的特定字符串批量修改为其他字符串时,可已使用以下操作:
mysql>UPDATE table_name SET field = REPLACE(field, 'old-value', 'new-value') [WHERE Clause] ;
实例15.1:
mysql>UPDATE tb1 SET name = REPLACE (name,'张三','张三丰') WHERE id = 1;
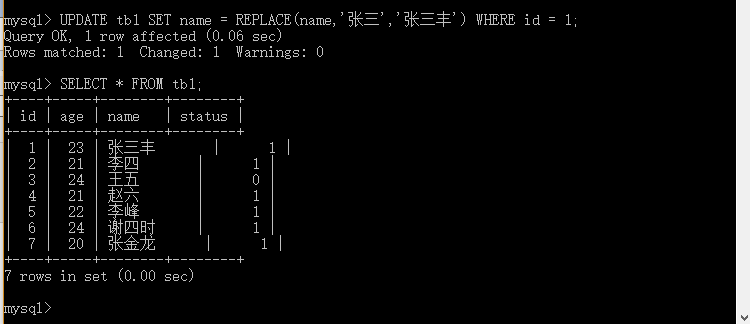
实例解析:更新tb1表 id 为 3 的name 字段值 将 "张三" 替换为 "张三丰"。
UPDATE 语句可用来修改表中的数据, 简单来说基本的使用形式为:
mysql>UPDATE table_name SET column_name = new-value [WHERE Clause] ;
实例15.2:
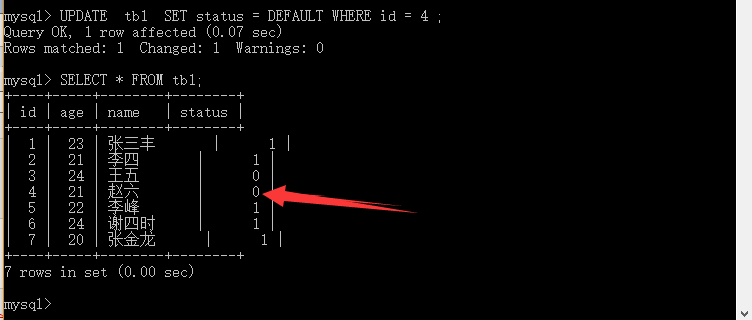
mysql>UPDATE tb1 SET status = DEFAULT WHERE id = 4 ;
实例解析:更新tb1表 id 为 4 的status字段值 更新为默认值 0 。
十六:DELETE 语句
DELETE FROM 命令来删除 MySQL 数据表中的记录。
mysql>DELETE FROM table_name [WHERE Clause];
- 如果没有指定 WHERE 子句,MySQL 表中的所有记录将被删除 [ 工作时 一定要记得加 删除条件 不然等着跑库吧!] ---不过只清空了表中数据。要不你再试试 DROP TABLE table_name; ---清空数据和删除表结构。
- 你可以在 WHERE 子句中指定任何条件
- 你可以在单个表中一次性删除记录 [ 慎用 ]。
实例16.1:
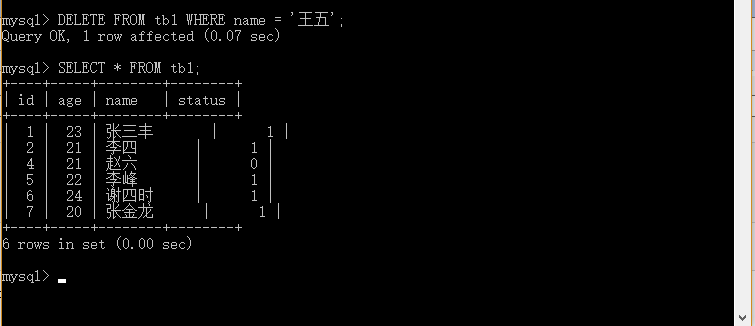
mysql>DELETE FROM tb1 WHERE name = '王五';
实例解析:删除tb1表name 为 王五 的数据。
十七:LIKE 子句
模糊查询 ------- %
我们知道在 MySQL 中使用 SQL SELECT 命令来读取数据, 同时我们可以在 SELECT 语句中使用 WHERE 子句来获取指定的记录。
WHERE 子句中可以使用等号 = 来设定获取数据的条件,如 "name = '李四'"。
但是有时候我们需要获取 name 字段含有 "李" 字符的所有记录,这时我们就需要在 WHERE 子句中使用 SQL LIKE 子句。
SQL LIKE 子句中使用百分号 %字符来表示任意字符,类似于UNIX或正则表达式中的星号 * 。
如果没有使用百分号 %, LIKE 子句与等号 = 的效果是一样的。
mysql>SELECT field1, field2,... FROM table_name WHERE field1 LIKE condition1 [AND [OR]] filed2 = 'somevalue'
- 可以在 WHERE 子句中指定任何条件。
- 可以在 WHERE 子句中使用LIKE子句。
- 可以使用LIKE子句代替等号 =。
- LIKE 通常与 % 一同使用,类似于一个元字符的搜索。
- 可以使用 AND 或者 OR 指定一个或多个条件。
- 可以在 DELETE 或 UPDATE 命令中使用 WHERE...LIKE 子句来指定条件。
实例17.1:
mysql>SELECT * FROM tb1 WHERE name LIKE '张%';

实例解析:我们将 tb1表中获取name 字段中以 张 为开头的的所有记录。
实例17.2:
mysql>SELECT * FROM tb1 WHERE name LIKE '%丰' AND id = '1%';
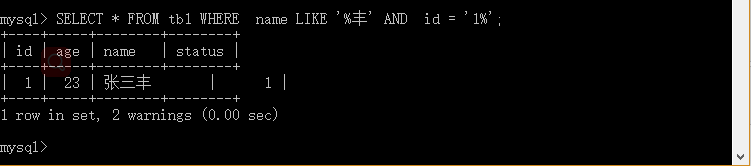
实例解析:将 tb1表 以name 字段中 丰 结束 并且 以 1 开始 的所有记录。
十八:UNION
NION 操作符用于连接两个以上的 SELECT 语句的结果组合到一个结果集合中。多个 SELECT 语句会删除重复的数据。
mysql>SELECT expression1, expression2, ... FROM table_name [WHERE conditions]
>UNION [ ALL | DISTINCT ]
>SELECT expression1, expression2, ... FROM table_name [WHERE conditions];
-
expression1, expression2, ... : 要检索的列。
-
tables: 要检索的数据表。
-
WHERE conditions: 可选, 检索条件。
-
DISTINCT: 可选,删除结果集中重复的数据。默认情况下 UNION 操作符已经删除了重复数据,所以 DISTINCT 修饰符对结果没啥影响。
-
ALL: 可选,返回所有结果集,包含重复数据。
18.1 实例 UNION
(1)数据表 tb1数据

(2) 数据表 tb2数据
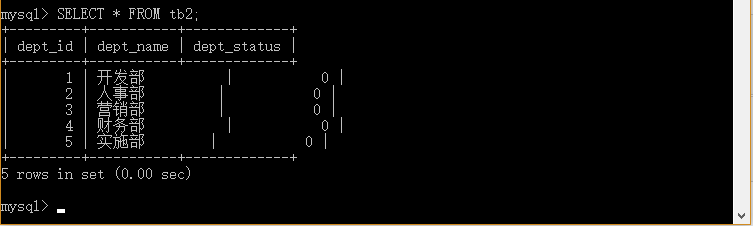
mysql>SELECT status FROM tb1 >UNION
>SELECT dept_status FROM tb2
>ORDER BY status ;

实例解析:从tb1和tb2表中选取不同的status (只有不同的值)
18.2 实例 UNION ALL
mysql>SELECT status FROM tb1
>UNION ALL
>SELECT dept_status FROM tb2
>ORDER BY status ;
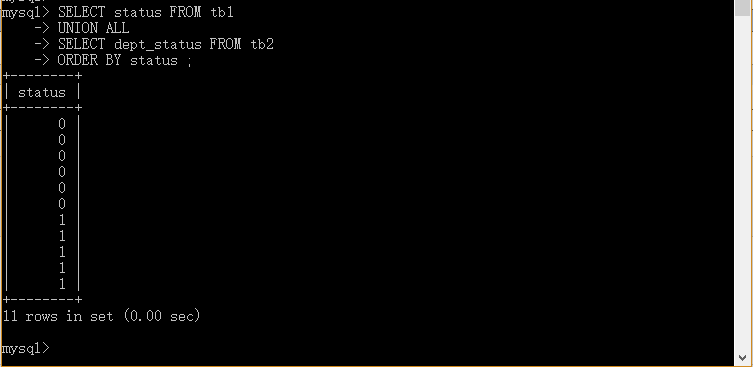
实例解析:从tb1和tb2表中选取所有的status (也有重复的值)
18.3 带有 WHERE 的 SQL UNION ALL
mysql>SELECT id, name,status FROM tb1
>WHERE status = 0
>UNION ALL
>SELECT dept_id, dept_name ,dept_status FROM tb2
>WHERE dept_status = 0
>ORDER BY id;
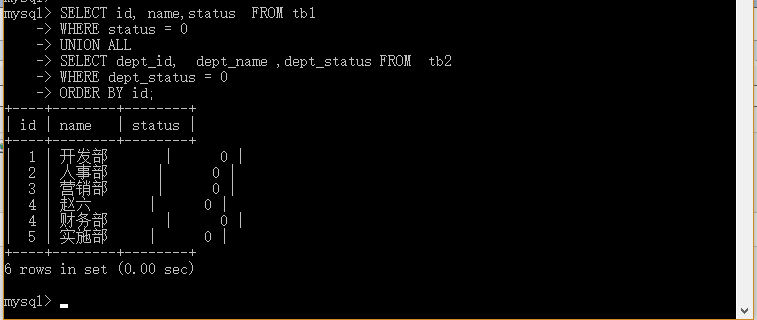
实例解析:从tb1和tb2表中选取所有的status=0的值 (也有重复的值)
十九:排序
我们知道从 MySQL 表中使用SELECT语句来读取数据。
如果我们需要对读取的数据进行排序,我们就可以使用ORDER BY 子句来设定你想按哪个字段哪种方式来进行排序,再返回搜索结果。
mysql>SELECT field1, field2,... table_name1, table_name2...
>ORDER BY field1, [field2...] [ASC [DESC]]
- 可以使用任何字段来作为排序的条件,从而返回排序后的查询结果。
- 可以设定多个字段来排序。
- 可以使用 ASC 或 DESC 关键字来设置查询结果是按升序或降序排列。 默认情况下,它是按升序排列。
- 可以添加 WHERE...LIKE 子句来设置条件。
实例:19.1
mysql>SELECT * FROM tb1 ORDER BY id DESC;

实例解析:读取 tb1 表中所有数据并按 id 字段的降序排列。
二十:分组
GROUP BY 语句根据一个或多个列对结果集进行分组。
在分组的列上我们可以使用 COUNT, SUM, AVG,等函数。
mysql>SELECT column_name, function(column_name)
>FROM table_name
>WHERE column_name operator value
>GROUP BY column_name;
解析:继续往tb1表添加字段及其数据---(追加字段后面我们会学到-- ALTER ADD)
mysql>SELECT name, COUNT(*) FROM tb1 GROUP BY name;
20.1实例: GROUP BY
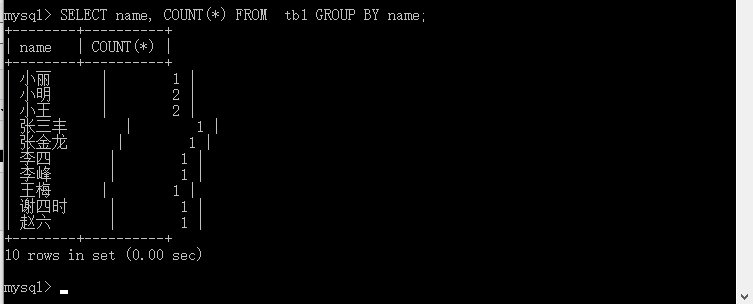
实例解析:使用 GROUP BY 语句 将数据表按名字进行分组,并统计每个人有多少条记录
20.2 实例: 使用 WITH ROLLUP
WITH ROLLUP 可以实现在分组统计数据基础上再进行相同的统计(SUM,AVG,COUNT…)
mysql>SELECT name, SUM(singin) as singin_count FROM tb1 GROUP BY name WITH ROLLUP;

实例解析:以上的数据表按名字进行分组,再统计每个人登录的次数
拓展:AS 设置字段别名。
其中记录 NULL 表示所有人的登录次数。
我们可以使用 coalesce 来设置一个可以取代 NUll 的名称,coalesce 语法:
mysql>SELECT COALESCE (a,b,c);
参数说明:如果a==null,则选择b;如果b==null,则选择c;如果a!=null,则选择a;如果a b c 都为null ,则返回为null(没意义)。
实例20.3 如果名字为空我们使用总数代替
mysql>SELECT coalesce(name, '总数'), SUM(singin) as singin_count FROM tb1 GROUP BY name WITH ROLLUP;
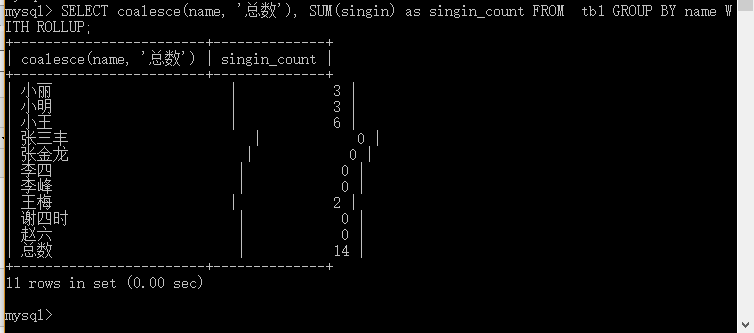
二十一:连接的使用
我们已经学会了如何在一张表中读取数据,这是相对简单的,但是在真正的应用中经常需要从多个数据表中读取数据。
本章节我们将向大家介绍如何使用 MySQL 的 JOIN 在两个或多个表中查询数据。
你可以在 SELECT, UPDATE 和 DELETE 语句中使用 Mysql 的 JOIN 来联合多表查询。
JOIN 按照功能大致分为如下三类:
- INNER JOIN(内连接,或等值连接):获取两个表中字段匹配关系的记录。
- LEFT JOIN(左连接):获取左表所有记录,即使右表没有对应匹配的记录。
- RIGHT JOIN(右连接): 与 LEFT JOIN 相反,用于获取右表所有记录,即使左表没有对应匹配的记录。
二十二:NULL 值处理
二十三:正则表达式
二十四:事务
二十五:ALTER命令
二十六:索引
二十七:临时表
二十八:复制表
二十九:元数据
三十:序列使用
MySQL序列是一组整数:1, 2, 3, ...,由于一张数据表只能有一个字段自增主键, 如果你想实现其他字段也实现自动增加,就可以使用MySQL序列来实现。
本章我们将介绍如何使用MySQL的序列。
30.使用AUTO_INCREMENT
MySQL中最简单使用序列的方法就是使用 MySQL AUTO_INCREMENT 来定义列。
实例
以下实例中创建了数据表insect, insect中id无需指定值可实现自动增长。

mysql> CREATE TABLE insect(-> id INT UNSIGNED NOT NULL AUTO_INCREMENT,
-> PRIMARY KEY (id),
-> name VARCHAR(30) NOT NULL, # type of insect
-> date DATE NOT NULL, # date collected
-> origin VARCHAR(30) NOT NULL # where collected
);
mysql> INSERT INTO insect (id,name,date,origin) VALUES
-> (NULL,'housefly','2001-09-10','kitchen'),
-> (NULL,'millipede','2001-09-10','driveway'),
-> (NULL,'grasshopper','2001-09-10','front yard');
mysql> SELECT * FROM insect ORDER BY id;
30.1获取AUTO_INCREMENT值
在MySQL的客户端中你可以使用 SQL中的LAST_INSERT_ID( ) 函数来获取最后的插入表中的自增列的值。
在PHP或PERL脚本中也提供了相应的函数来获取最后的插入表中的自增列的值。
PERL实例
使用 mysql_insertid 属性来获取 AUTO_INCREMENT 的值。 实例如下:
$dbh->do ("INSERT INTO insect (name,date,origin)
VALUES('moth','2001-09-14','windowsill')");
my $seq = $dbh->{mysql_insertid};
PHP实例
PHP 通过 mysql_insert_id ()函数来获取执行的插入SQL语句中 AUTO_INCREMENT列的值。
mysql_query ("INSERT INTO insect (name,date,origin)
VALUES('moth','2001-09-14','windowsill')", $conn_id);
$seq = mysql_insert_id ($conn_id);
30.2重置序列
如果你删除了数据表中的多条记录,并希望对剩下数据的AUTO_INCREMENT列进行重新排列,那么你可以通过删除自增的列,然后重新添加来实现。 不过该操作要非常小心,如果在删除的同时又有新记录添加,有可能会出现数据混乱。操作如下所示:
mysql> ALTER TABLE insect DROP id;
mysql> ALTER TABLE insect
-> ADD id INT UNSIGNED NOT NULL AUTO_INCREMENT FIRST,
-> ADD PRIMARY KEY (id);
30.3设置序列的开始值
一般情况下序列的开始值为1,但如果你需要指定一个开始值100,那我们可以通过以下语句来实现:
mysql> CREATE TABLE insect(-> id INT UNSIGNED NOT NULL AUTO_INCREMENT,
-> PRIMARY KEY (id),
-> name VARCHAR(30) NOT NULL,
-> date DATE NOT NULL,
-> origin VARCHAR(30) NOT NULL
)engine=innodb auto_increment=100 charset=utf8;
或者你也可以在表创建成功后,通过以下语句来实现:
mysql> ALTER TABLE t AUTO_INCREMENT = 100;
三十一:处理重复数据
有些 MySQL 数据表中可能存在重复的记录,有些情况我们允许重复数据的存在,但有时候我们也需要删除这些重复的数据。
本章节我们将为大家介绍如何防止数据表出现重复数据及如何删除数据表中的重复数据。
31.1防止表中出现重复数据。
你可以在mysql数据表中设置指定的字段为PRIMART KEY (主键)或者UNIQUE(唯一)索引来保证数据的唯一性
让我们尝试一个实例:下表中无索引及主键,所以该表允许出现多条重复记录。
CREATE TABLE person_tbl
(
first_name CHAR(20),
last_name CHAR(20),
sex CHAR(10)
);
如果你想设置表中字段first_name,last_name数据不能重复,你可以设置双主键模式来设置数据的唯一性, 如果你设置了双主键,那么那个键的默认值不能为NULL,可设置为NOT NULL。如下所示:
CREATE TABLE person_tbl ( first_name CHAR(20) NOT NULL, last_name CHAR(20) NOT NULL, sex CHAR(10), PRIMARY KEY (last_name, first_name) );
如果我们设置了唯一索引,那么在插入重复数据时,SQL语句将无法执行成功,并抛出错。
INSERT IGNORE INTO与INSERT INTO的区别就是INSERT IGNORE会忽略数据库中已经存在的数据,如果数据库没有数据,就插入新的数据,如果有数据的话就跳过这条数据。这样就可以保留数据库中已经存在数据,达到在间隙中插入数据的目的。
以下实例使用了INSERT IGNORE INTO,执行后不会出错,也不会向数据表中插入重复数据:
mysql> INSERT IGNORE INTO person_tbl (last_name, first_name)
-> VALUES( 'Jay', 'Thomas');
mysql> INSERT IGNORE INTO person_tbl (last_name, first_name)
-> VALUES( 'Jay', 'Thomas');
INSERT IGNORE INTO当插入数据时,在设置了记录的唯一性后,如果插入重复数据,将不返回错误,只以警告形式返回。 而REPLACE INTO into如果存在primary 或 unique相同的记录,则先删除掉。再插入新记录。
另一种设置数据的唯一性方法是添加一个UNIQUE索引,如下所示:
CREATE TABLE person_tbl ( first_name CHAR(20) NOT NULL, last_name CHAR(20) NOT NULL, sex CHAR(10) UNIQUE (last_name, first_name) );
31.2统计重复数据
以下我们将统计表中 first_name 和 last_name的重复记录数:
mysql> SELECT COUNT(*) as repetitions, last_name, first_name
-> FROM person_tbl
-> GROUP BY last_name, first_name
-> HAVING repetitions > 1;
以上查询语句将返回 person_tbl 表中重复的记录数。 一般情况下,查询重复的值,请执行以下操作:
- 确定哪一列包含的值可能会重复。
- 在列选择列表使用COUNT(*)列出的那些列。
- 在GROUP BY子句中列出的列。
- HAVING子句设置重复数大于1。
31.3过滤重复数据
如果你需要读取不重复的数据可以在 SELECT 语句中使用 DISTINCT 关键字来过滤重复数据。
mysql> SELECT DISTINCT last_name, first_name
-> FROM person_tbl;
你也可以使用 GROUP BY 来读取数据表中不重复的数据:
mysql> SELECT last_name, first_name
-> FROM person_tbl
-> GROUP BY (last_name, first_name);
31.4删除重复数据
如果你想删除数据表中的重复数据,你可以使用以下的SQL语句:
mysql> CREATE TABLE tmp SELECT last_name, first_name, sex FROM person_tbl GROUP BY (last_name, first_name, sex); mysql> DROP TABLE person_tbl; mysql> ALTER TABLE tmp RENAME TO person_tbl;
也可以在数据表中添加 INDEX(索引) 和 PRIMAY KEY(主键)这种简单的方法来删除表中的重复记录。方法如下:
mysql> ALTER IGNORE TABLE person_tbl
-> ADD PRIMARY KEY (last_name, first_name);
三十二:MySQL 及 SQL 注入
如果您通过网页获取用户输入的数据并将其插入一个MySQL数据库,那么就有可能发生SQL注入安全的问题。
本章节将为大家介绍如何防止SQL注入,并通过脚本来过滤SQL中注入的字符。
所谓SQL注入,就是通过把SQL命令插入到Web表单递交或输入域名或页面请求的查询字符串,最终达到欺骗服务器执行恶意的SQL命令。
我们永远不要信任用户的输入,我们必须认定用户输入的数据都是不安全的,我们都需要对用户输入的数据进行过滤处理。
以下实例中,输入的用户名必须为字母、数字及下划线的组合,且用户名长度为 8 到 20 个字符之间:
if (preg_match("/^w{8,20}$/", $_GET['username'], $matches))
{
$result = mysqli_query($conn, "SELECT * FROM users
WHERE username=$matches[0]");
}
else
{
echo "username 输入异常";
}
让我们看下在没有过滤特殊字符时,出现的SQL情况:
// 设定$name 中插入了我们不需要的SQL语句
$name = "Qadir'; DELETE FROM users;";
mysqli_query($conn, "SELECT * FROM users WHERE name='{$name}'");
以上的注入语句中,我们没有对 name的变量进行过滤,name的变量进行过滤,name 中插入了我们不需要的SQL语句,将删除 users 表中的所有数据。
在PHP中的 mysqli_query() 是不允许执行多个 SQL 语句的,但是在 SQLite 和 PostgreSQL 是可以同时执行多条SQL语句的,所以我们对这些用户的数据需要进行严格的验证。
防止SQL注入,我们需要注意以下几个要点:
- 1.永远不要信任用户的输入。对用户的输入进行校验,可以通过正则表达式,或限制长度;对单引号和 双"-"进行转换等。
- 2.永远不要使用动态拼装sql,可以使用参数化的sql或者直接使用存储过程进行数据查询存取。
- 3.永远不要使用管理员权限的数据库连接,为每个应用使用单独的权限有限的数据库连接。
- 4.不要把机密信息直接存放,加密或者hash掉密码和敏感的信息。
- 5.应用的异常信息应该给出尽可能少的提示,最好使用自定义的错误信息对原始错误信息进行包装
- 6.sql注入的检测方法一般采取辅助软件或网站平台来检测,软件一般采用sql注入检测工具jsky,网站平台就有亿思网站安全平台检测工具。MDCSOFT SCAN等。采用MDCSOFT-IPS可以有效的防御SQL注入,XSS攻击等。
防止SQL注入
在脚本语言,如Perl和PHP你可以对用户输入的数据进行转义从而来防止SQL注入。
PHP的MySQL扩展提供了mysqli_real_escape_string()函数来转义特殊的输入字符。
if (get_magic_quotes_gpc())
{
$name = stripslashes($name);
}
$name = mysqli_real_escape_string($conn, $name);
mysqli_query($conn, "SELECT * FROM users WHERE name='{$name}'");
Like语句中的注入
like查询时,如果用户输入的值有"_"和"%",则会出现这种情况:用户本来只是想查询"abcd_",查询结果中却有"abcd_"、"abcde"、"abcdf"等等;用户要查询"30%"(注:百分之三十)时也会出现问题。
在PHP脚本中我们可以使用addcslashes()函数来处理以上情况,如下实例:
$sub = addcslashes(mysqli_real_escape_string($conn, "%something_"), "%_");
// $sub == \%something\_
mysqli_query($conn, "SELECT * FROM messages WHERE subject LIKE '{$sub}%'");
addcslashes() 函数在指定的字符前添加反斜杠。
语法格式:
addcslashes(string,characters)
| 参数 | 描述 |
| string | 必需。规定要检查的字符串。 |
| characters | 可选。规定受 addcslashes() 影响的字符或字符范围。 |
三十三:导出数据
33.1使用 SELECT ... INTO OUTFILE 语句导出数据
以下实例中我们将数据表tb1
mysql> SELECT * FROM tb1
-> INTO OUTFILE '/tmp/tutorials.txt';
数据导出到 /tmp/tutorials.txt 文件中:
你可以通过命令选项来设置数据输出的指定格式,以下实例为导出 CSV 格式:
mysql> SELECT * FROM passwd INTO OUTFILE '/tmp/tutorials.txt'
-> FIELDS TERMINATED BY ',' ENCLOSED BY '"'
-> LINES TERMINATED BY '
';
在下面的例子中,生成一个文件,各值用逗号隔开。这种格式可以被许多程序使用。
SELECT a,b,a+b INTO OUTFILE '/tmp/result.text' FIELDS TERMINATED BY ',' OPTIONALLY ENCLOSED BY '"' LINES TERMINATED BY ' ' FROM test_table;
SELECT ... INTO OUTFILE 语句有以下属性:
- LOAD DATA INFILE是SELECT ... INTO OUTFILE的逆操作,SELECT句法。为了将一个数据库的数据写入一个文件,使用SELECT ... INTO OUTFILE,为了将文件读回数据库,使用LOAD DATA INFILE。
- SELECT...INTO OUTFILE 'file_name'形式的SELECT可以把被选择的行写入一个文件中。该文件被创建到服务器主机上,因此您必须拥有FILE权限,才能使用此语法。
- 输出不能是一个已存在的文件。防止文件数据被篡改。
- 你需要有一个登陆服务器的账号来检索文件。否则 SELECT ... INTO OUTFILE 不会起任何作用。
- 在UNIX中,该文件被创建后是可读的,权限由MySQL服务器所拥有。这意味着,虽然你就可以读取该文件,但可能无法将其删除。
33.2导出表作为原始数据
mysqldump是mysql用于转存储数据库的实用程序。它主要产生一个SQL脚本,其中包含从头重新创建数据库所必需的命令CREATE TABLE INSERT等。
使用mysqldump导出数据需要使用 --tab 选项来指定导出文件指定的目录,该目标必须是可写的。
以下实例将数据表 tb1 导出到 /tmp 目录中:
$ mysqldump -u root -p --no-create-info
--tab=/tmp RUNOOB runoob_tbl
password ******
33.3导出SQL格式的数据
导出SQL格式的数据到指定文件,如下所示:
$ mysqldump -u root -p RUNOOB runoob_tbl > dump.txt password ******
以上命令创建的文件内容如下:
-- MySQL dump 8.23
--
-- Host: localhost Database: RUNOOB
---------------------------------------------------------
-- Server version 3.23.58
--
-- Table structure for table `runoob_tbl`
--
CREATE TABLE runoob_tbl (
runoob_id int(11) NOT NULL auto_increment,
runoob_title varchar(100) NOT NULL default '',
runoob_author varchar(40) NOT NULL default '',
submission_date date default NULL,
PRIMARY KEY (runoob_id),
UNIQUE KEY AUTHOR_INDEX (runoob_author)
) TYPE=MyISAM;
--
-- Dumping data for table `runoob_tbl`
--
INSERT INTO runoob_tbl
VALUES (1,'Learn PHP','John Poul','2007-05-24');
INSERT INTO runoob_tbl
VALUES (2,'Learn MySQL','Abdul S','2007-05-24');
INSERT INTO runoob_tbl
VALUES (3,'JAVA Tutorial','Sanjay','2007-05-06');
如果你需要导出整个数据库的数据,可以使用以下命令:
$ mysqldump -u root -p RUNOOB > database_dump.txt password ******
如果需要备份所有数据库,可以使用以下命令:
$ mysqldump -u root -p --all-databases > database_dump.txt password ******
--all-databases 选项在 MySQL 3.23.12 及以后版本加入。
该方法可用于实现数据库的备份策略。
33.4将数据表及数据库拷贝至其他主机
如果你需要将数据拷贝至其他的 MySQL 服务器上, 你可以在 mysqldump 命令中指定数据库名及数据表。
在源主机上执行以下命令,将数据备份至 dump.txt 文件中:
$ mysqldump -u root -p database_name table_name > dump.txt password *****
如果完整备份数据库,则无需使用特定的表名称。
如果你需要将备份的数据库导入到MySQL服务器中,可以使用以下命令,使用以下命令你需要确认数据库已经创建:
$ mysql -u root -p database_name < dump.txt password *****
你也可以使用以下命令将导出的数据直接导入到远程的服务器上,但请确保两台服务器是相通的,是可以相互访问的:
$ mysqldump -h other-host.com -P port -u root -p database_name > dump.txt password ****
三十四:导入数据
34.1使用 LOAD DATA 导入数据
MySQL 中提供了LOAD DATA INFILE语句来插入数据。 以下实例中将从当前目录中读取文件 dump.txt ,将该文件中的数据插入到当前数据库的 mytbl 表中。
mysql> LOAD DATA LOCAL INFILE 'dump.txt' INTO TABLE mytbl;
如果指定LOCAL关键词,则表明从客户主机上按路径读取文件。如果没有指定,则文件在服务器上按路径读取文件。
你能明确地在LOAD DATA语句中指出列值的分隔符和行尾标记,但是默认标记是定位符和换行符。
两个命令的 FIELDS 和 LINES 子句的语法是一样的。两个子句都是可选的,但是如果两个同时被指定,FIELDS 子句必须出现在 LINES 子句之前。
如果用户指定一个 FIELDS 子句,它的子句 (TERMINATED BY、[OPTIONALLY] ENCLOSED BY 和 ESCAPED BY) 也是可选的,不过,用户必须至少指定它们中的一个。
mysql> LOAD DATA LOCAL INFILE 'dump.txt' INTO TABLE mytbl -> FIELDS TERMINATED BY ':' -> LINES TERMINATED BY ' ';
LOAD DATA 默认情况下是按照数据文件中列的顺序插入数据的,如果数据文件中的列与插入表中的列不一致,则需要指定列的顺序。
如,在数据文件中的列顺序是 a,b,c,但在插入表的列顺序为b,c,a,则数据导入语法如下:
mysql> LOAD DATA LOCAL INFILE 'dump.txt'
-> INTO TABLE mytbl (b, c, a);
使用 mysqlimport 导入数据
mysqlimport客户端提供了LOAD DATA INFILEQL语句的一个命令行接口。mysqlimport的大多数选项直接对应LOAD DATA INFILE子句。
从文件 dump.txt 中将数据导入到 mytbl 数据表中, 可以使用以下命令:
$ mysqlimport -u root -p --local database_name dump.txt password *****
mysqlimport命令可以指定选项来设置指定格式,命令语句格式如下:
$ mysqlimport -u root -p --local --fields-terminated-by=":" --lines-terminated-by=" " database_name dump.txt password *****
mysqlimport 语句中使用 --columns 选项来设置列的顺序:
$ mysqlimport -u root -p --local --columns=b,c,a
database_name dump.txt
password *****
mysqlimport的常用选项介绍
| 选项 | 功能 |
| -d or --delete | 新数据导入数据表中之前删除数据数据表中的所有信息 |
| -f or --force | 不管是否遇到错误,mysqlimport将强制继续插入数据 |
| -i or --ignore | mysqlimport跳过或者忽略那些有相同唯一 关键字的行, 导入文件中的数据将被忽略。 |
| -l or -lock-tables | 数据被插入之前锁住表,这样就防止了, 你在更新数据库时,用户的查询和更新受到影响。 |
| -r or -replace | 这个选项与-i选项的作用相反;此选项将替代 表中有相同唯一关键字的记录。 |
| --fields-enclosed- by= char | 指定文本文件中数据的记录时以什么括起的, 很多情况下 数据以双引号括起。 默认的情况下数据是没有被字符括起的。 |
| --fields-terminated- by=char | 指定各个数据的值之间的分隔符,在句号分隔的文件中, 分隔符是句号。您可以用此选项指定数据之间的分隔符。 默认的分隔符是跳格符(Tab) |
| --lines-terminated- by=str | 此选项指定文本文件中行与行之间数据的分隔字符串 或者字符。 默认的情况下mysqlimport以newline为行分隔符。 您可以选择用一个字符串来替代一个单个的字符: 一个新行或者一个回车。 |
mysqlimport命令常用的选项还有-v 显示版本(version), -p 提示输入密码(password)等。