链接:
https://leetcode-cn.com/problems/substring-with-concatenation-of-all-words
描述:
给定一个字符串 s 和一些长度相同的单词 words。找出 s 中恰好可以由 words 中所有单词串联形成的子串的起始位置。
注意子串要与 words 中的单词完全匹配,中间不能有其他字符,但不需要考虑 words 中单词串联的顺序。
示例 1:
输入:
s = "barfoothefoobarman",
words = ["foo","bar"]
输出:[0,9]
解释:
从索引 0 和 9 开始的子串分别是 "barfoo" 和 "foobar" 。
输出的顺序不重要, [9,0] 也是有效答案。
示例 2:
输入:
s = "wordgoodgoodgoodbestword",
words = ["word","good","best","word"]
输出:[]
vector<int> findSubstring(string s, vector<string>& words) {}
思路:
遍历 s 中所有长度为 words.size * word.size 的子串:
将子串中包含的单词和对应的数量存入哈希表中
若与单词表匹配,则存入结果中
例如:
s = "hahihashahahahi",
words = ["hi","ha","ha"]


上面过程稍稍优化一点:
判断子串是否符合要求时,不必将子串中所有单词都存入哈希表中。
遍历子串中所有单词时,只要一发现子串的哈希表中当前单词的个数大于单词表的数量,就可断定为不符合。
C++
展开后查看
class Solution {
public:
vector<int> findSubstring(string s, vector<string>& words) {
vector<int> result;
if(words.size() == 0){
return result;
}
int n = words.size(), len = words[0].size();
if(s.size() < n * len){
return result;
}
unordered_map<string, int> wordsMap;
for(string word: words){
wordsMap[word] += 1;
}
for(int i = 0; i <= s.size() - n * len; i++){
string tempStr = s.substr(i, n * len);
unordered_map<string, int> tempMap;
bool flag = true;
for(int j = 0; j < n; j++){
string tempWord = tempStr.substr(j * len, len);
tempMap[tempWord] += 1;
if(tempMap[tempWord] > wordsMap[tempWord]){
flag = false;
break;
}
}
if(flag){
result.push_back(i);
}
}
return result;
}
};
Java
展开后查看
class Solution {
public List<Integer> findSubstring(String s, String[] words) {
List<Integer> result = new ArrayList<>();
if(words.length == 0){
return result;
}
int n = words.length, len = words[0].length();
if(s.length() < n * len){
return result;
}
HashMap<String, Integer> wordsMap = new HashMap<>();
for(String word: words){
int value = wordsMap.getOrDefault(word, 0);
wordsMap.put(word, value + 1);
}
for(int i = 0; i <= s.length() - n * len; i++){
String tempStr = s.substring(i, i + n * len);
HashMap<String, Integer> tempMap = new HashMap<>();
boolean flag = true;
for(int j = 0; j < n; j++){
String tempWord = tempStr.substring(j * len, j * len + len);
int value = tempMap.getOrDefault(tempWord, 0);
tempMap.put(tempWord, value + 1);
if(tempMap.get(tempWord) > wordsMap.getOrDefault(tempWord, 0)){
flag = false;
break;
}
}
if(flag){
result.add(i);
}
}
return result;
}
}
优化:
使用滑动窗口,提高效率
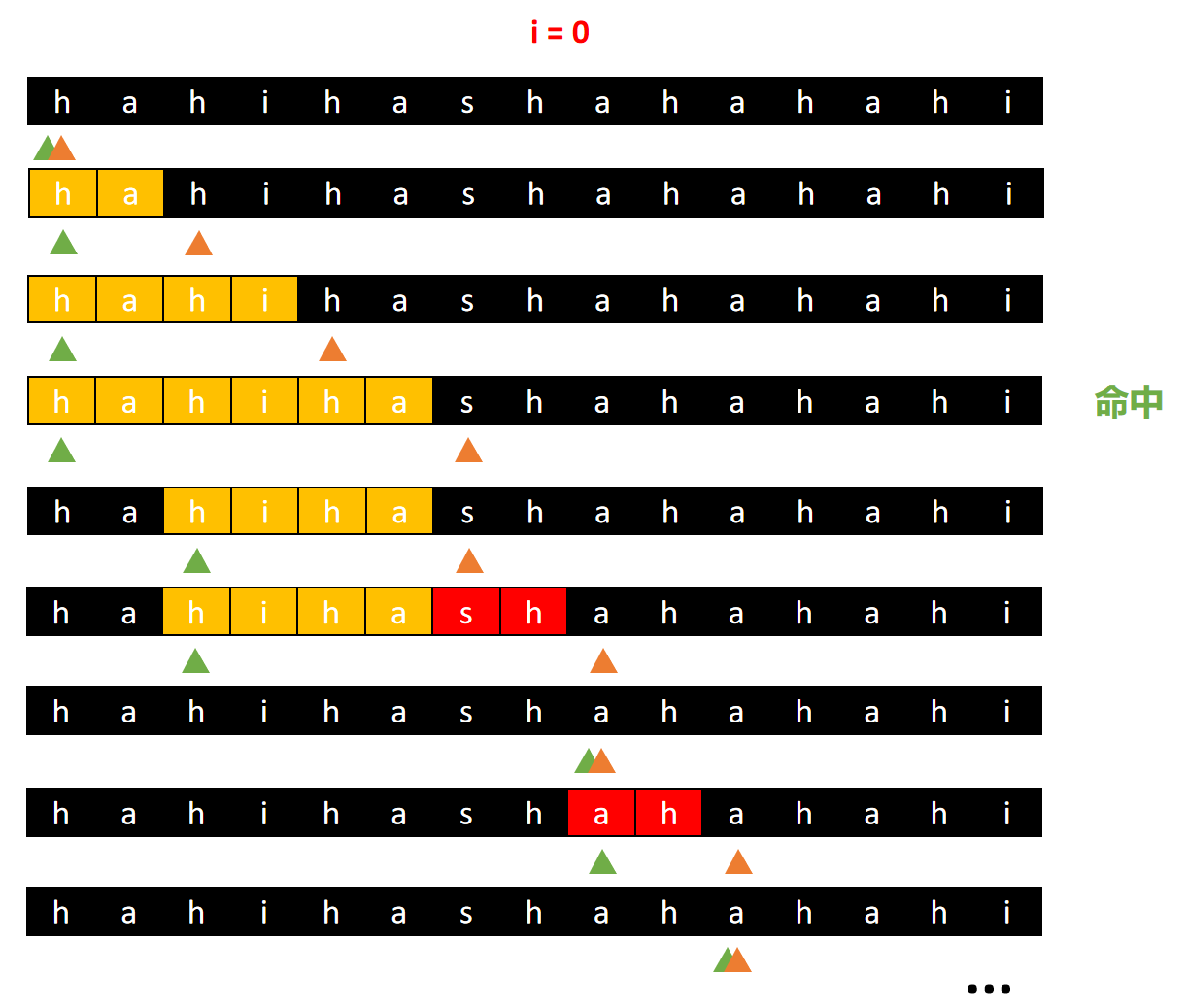
- 在 ([0, len)) 范围内,每一个字母都可以作为滑动窗口的起点
- 滑动窗口的左右指针,每次滑动的步长为单词的长度 (len)
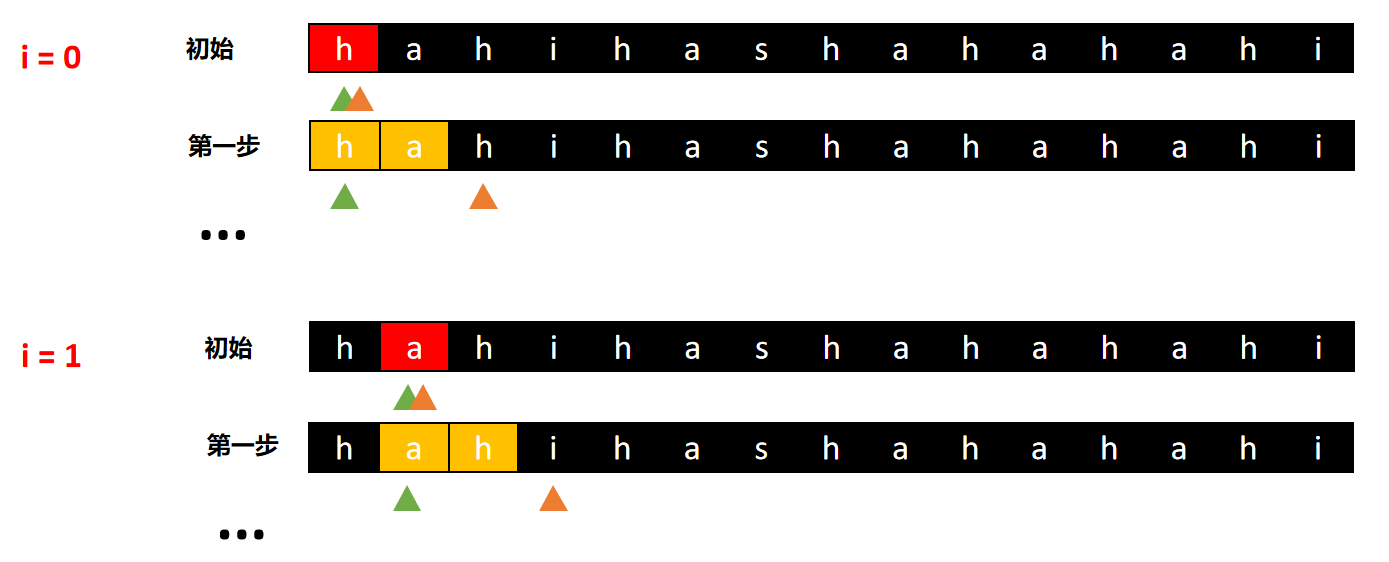
- 当窗口大小不大于 (n * len) 时,窗口的右指针向右滑动一个单词的长度,将该单词加入到滑动窗口中
若新加入的单词不是单词表中的单词时,窗口直接越过非法单词,将窗口的左指针 (left) 指向右指针 (right),此时窗口大小为零
若新加入的单词的个数超过单词表中该单词的数量时,移动窗口的左指针,直到将该单词的数量降到合法数量为止 - 当窗口大小等于 (n * len) 时,将窗口的左指针位置加入到结果中,之后向右移动
- 重复以上过程,直到滑动窗口到达字符串末尾
C++
展开后查看
class Solution {
public:
vector<int> findSubstring(string s, vector<string>& words) {
vector<int> result;
if(words.size() == 0){
return result;
}
int n = words.size(), len = words[0].size();
if(s.size() < n * len){
return result;
}
unordered_map<string, int> wordsMap;
for(string word: words){
wordsMap[word] += 1;
}
for(int i = 0; i < len; i++){
unordered_map<string, int> tempMap;
for(int left = i, right = i; left <= s.size() - n * len; ){
while(right < left + n * len){
string tempWord = s.substr(right, len);
tempMap[tempWord] += 1;
right += len;
if(tempMap[tempWord] > wordsMap[tempWord]){
if(wordsMap[tempWord] == 0){
left = right;
tempMap.clear();
}else{
while(left < right){
string word = s.substr(left, len);
tempMap[word] -= 1;
left += len;
if(word == tempWord){
break;
}
}
}
break;
}
}
if(right - left == n * len){
result.push_back(left);
string tempWord = s.substr(left, len);
tempMap[tempWord] -= 1;
left += len;
}
}
}
return result;
}
};
Java
展开后查看
class Solution {
public List<Integer> findSubstring(String s, String[] words) {
List<Integer> result = new ArrayList<>();
if(words.length == 0){
return result;
}
int n = words.length, len = words[0].length();
if(s.length() < n * len){
return result;
}
HashMap<String, Integer> wordsMap = new HashMap<>();
for(String word: words){
int value = wordsMap.getOrDefault(word, 0);
wordsMap.put(word, value + 1);
}
for(int i = 0; i < len; i++){
HashMap<String, Integer> tempMap = new HashMap<>();
for(int left = i, right = i; left <= s.length() - n * len; ){
while(right < left + n * len){
String tempWord = s.substring(right, right + len);
int value = tempMap.getOrDefault(tempWord, 0);
tempMap.put(tempWord, value + 1);
right += len;
if(tempMap.get(tempWord) > wordsMap.getOrDefault(tempWord, 0)){
if(wordsMap.getOrDefault(tempWord, 0) == 0){
left = right;
tempMap.clear();
}else{
while(left < right){
String word = s.substring(left, left + len);
value = tempMap.get(word);
tempMap.put(word, value - 1);
left += len;
if(word.equals(tempWord)){
break;
}
}
}
break;
}
}
if(right - left == n * len){
result.add(left);
String tempWord = s.substring(left, left + len);
int value = tempMap.get(tempWord);
tempMap.put(tempWord, value - 1);
left += len;
}
}
}
return result;
}
}