接上一篇笔记, 仔细看了cal3d的代码, 他的骨骼节点判断也有判断controller(node controller type + object type)的,所以之前的做法跟他是一样的.
导出插件改用一个DLL封装, 该DLL在导出时加载真正的导出DLL,导出完毕再卸载内部DLL,具体思路见 http://www.opengpu.org/forum.php?mod=viewthread&tid=11864&extra=page%3D1. 需要注意的时, debugger attach到3dsmax的时候, 选则native debug, 否则无法进断点, 因为3dsmax的入口是managed code, 加上外围的native扩展.
通过这种方式, 引擎的核心DLL(导出插件的依赖)也被手动加载进来, 目前编译和运行插件已经不依赖Blade SDK了, 不过Blade SDK的生成以后还是会用到的. 同时, DLL的反复加载和卸载, 测出了卸载时, 几个在编辑器模式下没有暴露的bug,这下代码也更加稳健了.
另外, 在DLL被加载以后, 尽量不要在外面直接或者间接的使用crt的内存分配, 否则DLL卸载的时候memory dump会把他报出来, 举一个我遇到的例子:
1 { 2 LoadDLL(); 3 std::string XXXX; //std::string will allocate crt memory 4 UnLoadDLL(); // blade memory dump on dll unload, "leaks" detected. 5 } // std:string destructed on out of the scope, no real leak at all
关于模型压缩:
1.D3D9和GLES的uniform格式不支持x10y10z10w2 (或许D3D11也不支持吧),所以shader constant中使用float4, 只压缩保存的文件, 加载时转成float4.
2.位置使用f16x4,w=1所以保存为f16x3, 这样多了16字节, 正好把旋转x10y10z10w2改成x16y16z16即int16x3.
使用float4的原文件,1800+个关键帧, 大小70,285K (70M左右) , 使用以上方法, 减少到21,970K(21M左右)
不知道保存Position, 用f16会不会有问题, 如果遇到精度问题就使用int16x3+bone AABB压缩, 即跟同事聊天学到的方法, 模型的顶点保存暂不使用这种方法.
前几天跟千里马肝大大确认了他提到的骨骼压缩(博客中的链接失效, 以至于不知道任何细节), 跟之前跟同事聊天谈到的是一样的(http://www.cnblogs.com/crazii/p/3677625.html), 即根据插值,去掉无用的关键帧. 准备后面把这个也做了.
另外一个大的更新是IImage interface, 之前的做法是将普通图像和压缩图像分开, 所有还有IImageDDS之类的. 这样的接口在概念上本来是应该统一的, 否则用起来很不方便.
之前的IImage根本不算是抽象, 可以说是FreeImage的封装, 写的很挫. 这次把接口做了简化和调整, 内部实现做了大的修改. 这是以前的设计:
foundation level: IImageDDS IImage FreeImage(private) IImageManager squish,FastDXT
| / / / /
plugin level: ImageDDS ImageFI <---- ImageManagerFI
现在的设计如下:
IImage FreeImage(private) IImageManager squish, FastDXT
| / | /
ImageBase <--------- ImageManager
|
Image
现在Image只在加载和处理时依赖FreeImage, 实际的数据不再使用FreeImage的FIBITMAP对象.
去掉了ImageDDS接口, 好在用到IImageDDS的地方不多, 只有D3D9GraphicsResourceManager, 和TextureSerializer, 以及TerrainTextureManager.
ImageManager主要负责Image的复制, 翻转, 缩放, 灰度化, 合并, 格式转换(包括压缩解压)等,并提供了per block的压缩和解压功能.
另外需要备忘的是, IImage只用于简单直接加载图像, 它没有被定义成一种资源(IResource), 这个或许也需要调整.
顺便把3Dc ('ATI2', BC5) 的格式支持一下, 之前法线贴图用的DXT1, 马赛克比较明显. 由于squish不支持BC5, 所以曾考虑用DirectXTex或者crunch. 这样依赖可能有点臃肿, 而且已经有squish和FastDXT两个依赖库了.
最后重新写了这些压缩解压函数,去掉了所有依赖,也没有使用DirectXTex,这样感觉更干净点.
贴一下BC5跟之前BC1的法线对比
这是以前的BC1(DXT1),前面贴过:

这是新的BC5, 可以明显看到脖子,衣领,水壶等处的马赛克没有了:
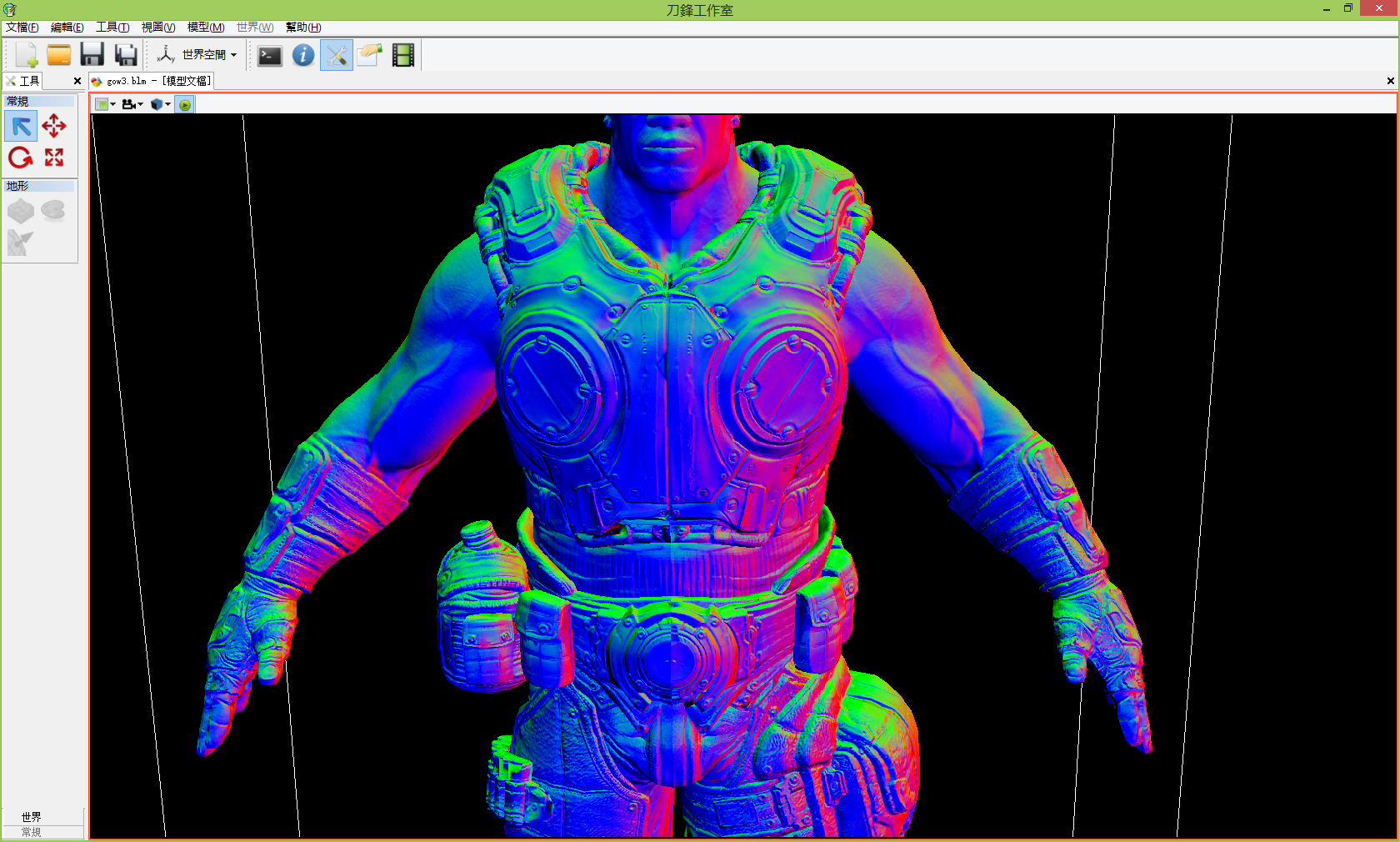
由于dx9没有BC5格式, Blade的BC5格式在dx9下实际用的是3Dc, (ForCC:ATI2), 虽然说3Dc和BC5在功能上等价, 但是仍然遇到了几个问题:
1. 3Dc‘s channel is GR, not RG. 即BC5的RG跟3Dc稍微差别.需要swizzle.
2. ’ATI2‘ in dx9 is an extension format, dx9runtime assume it is 8 BPP, normal(none-compressed) texture.(http://aras-p.info/texts/D3D9GPUHacks.html)
Thing to keep in mind: when DX9 allocates the mip chain, they check if the format is a known compressed format and allocate the appropriate space for the smallest mip levels. For example, a 1x1 DXT1 compressed level actually takes up 8 bytes, as the block size is fixed at 4x4 texels. This is true for all block compressed formats. Now when using the hacked formats DX9 doesn’t know it’s a block compression format and will only allocate the number of bytes the mip would have taken, if it weren’t compressed. For example a 1x1 ATI1n format will only have 1 byte allocated. What you need to do is to stop the mip chain before the size of the either dimension shrinks below the block dimensions otherwise you risk having memory corruption.
出了以上链接中的mipmap的问题(由于Blade对压缩格式都没有生成4x4以下的mip,所以实际没有遇到这个问题),
我还遇到了pitch不正确, 以及lock rect的指针不正确(只有lock部分区域时才会有)的问题,原因跟上面一样, 很坑爹,一开始以为是BC5压缩算法的问题, 花了很长世间调试和修复.
i.e. the correct pitch of a 512x512 'ATI2' format texture is 512/4*16=2048, but d3d9 runtime gives a 512.
Also, when locking sub rect of the texture, the returned buffer pointer(pBits) is not correctly offsetted, again, the offset made by d3d9runtime is based on the the assumption that this format is a 8 BPP format. i.e. sub rect of (128,256,256,384), the beginning of buffer should be (256*pitch + 128*16) = 256*2048+128*16, but d3d9 gives a (256*512 + 128).
接着上面,因为3Dc需要swizzle, rg=>gr,导致shader跟dxt1不兼容,(本来bc5的shader解法向量,可以用在bc1上,虽然效率偏低),目前还没有好的方法解决.
最后关于贴图资源, 之前的想法是用PNG和非压缩的格式(RGB/RGBA)保存,运行时压缩成BCn等格式, 但是缺点是数据包大, 和runtime损耗. 对于移动端可能不是好的做法, PC,console的话,实时压缩可能问题不大,但是移动端CPU可能没那么强,也很费电,资源包也会很大.
现在在思考用工具离线压缩,这需要编辑器/模型导出时使用原格式,然后统一处理成其他平台的格式,这样数据包会比较小,而且没有额外的runtime开销,IO量可能也会小.
由于最近工作很忙, 后面可能没有时间写代码和更新了,等有时间了再继续. 后面会做动画的runtime,渲染,和骨骼数据优化/压缩.