今天,我们来聊聊拓扑排序。
何为拓扑排序?
拓扑排序,这个顾名思义似乎有点难。那就直接上定义吧:
对于一个DAG(有向无环图)(G),将 (G) 中所有顶点排序为一个线性序列,使得图中任意一对顶点 (u) 和 (v),若 (u) 和 (v) 之间存在一条从 (u) 指向 (v) 的边,那么 (u) 在线性序列中一定在 (v) 前。
啥意思呢。比如这样一个DAG:
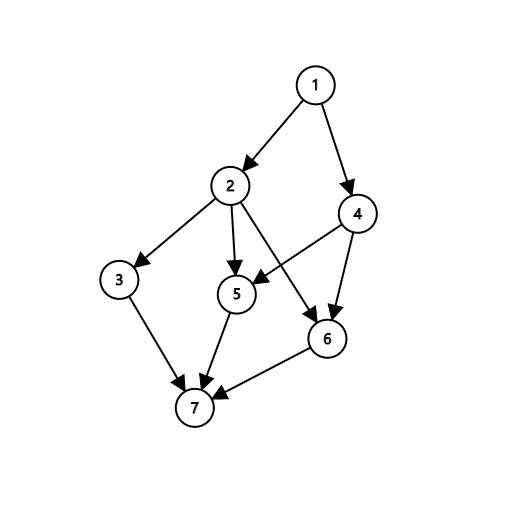
几种可能的拓扑序是:
- 1 2 4 3 5 6 7
- 1 2 3 4 5 6 7
- 1 4 2 5 6 3 7
也就是说,DAG的拓扑序可能并不唯一。
那么,1 3 2 4 5 6 7是不是这张图的拓扑序呢?答案是否定的,因为图中存在 (2 ightarrow 3) 这条边,那么2必须出现在3的前面,但是这里2却出现在3的后面,因此不是拓扑序。
拓扑排序和DAG的关系
现在,你对拓扑排序的理解一定加深了一些。那么接下来让我们思考一个问题,拓扑排序为什么一定要在DAG上?不在DAG上难道不行吗?
首先,DAG是有向无环图的意思,我们从有向和无环两个方面分别做反义词,也就是无向,有环。
接下来我们证明为什么这两种情况不能出现。
为什么有无向边的图无拓扑序?
假设存在有无向边的有 (n) 个点的图 (G) 的拓扑序 (a),那么一定存在两个数 (i, j (1 le i, j le n)),满足 (a_i ightarrow a_j in G, a_j ightarrow a_i in G)。根据拓扑序的定义,就有 (i < j) 且 (i > j),显然不存在 (i, j) 满足此逻辑关系,即有无向边的图无拓扑序。
为什么有环的图无拓扑序?
假设存在有环的有 (n) 个点的图 (G) 的拓扑序 (a),那么一定存在 (k(1 < k le n), p(1 le p le n - k)) 使得 (a_{p+1} ightarrow a_{p+2}, a_{p+2} ightarrow a_{p+3}, a_{p+3} ightarrow a_{p+4}, ldots, a_{p+k-1} ightarrow a_{p+k}, a_{p+k} ightarrow a_{p+1} in G)。根据拓扑序的定义,就有 (p + k < p + 1),但 (k > 1),因此 (p + k < p + 1) 不可被满足,即有环图无拓扑序。
其实,无向边可以看做包含两个点的环,所以他们的证明很相似。
至此证毕。
拓扑排序的实现
dfs
众所周知,dfs可以解决任何一个不带时限的题目(
那么我们就来想下怎么用dfs实现拓扑排序吧。
- 首先定义一个标记数组 (flag)。
- 初始化 (flag_i = 0)
- 循环遍历 (u = 1 ightarrow n),当 (flag_u = 0) 时,进行dfs。dfs此处是一个bool函数,如果返回true则代表运行正常,如果返回false代表发现了环或无向边。那么如果此时的dfs函数返回一个false值,直接返回,无拓扑序。至于dfs怎么判环,会在下方的dfs函数处理步骤给出。
接下来是dfs函数处理步骤:
- 对于一个来自参数的节点 (u),先令 (flag_u leftarrow -1),然后遍历其出边。如果发现 (u ightarrow v in G),且 (flag_v = -1),说明有环,返回false。然后如果 (flag_v = 0)((flag_v = 1) 代表此点安全,不必再处理),我们就进行dfs(v)的操作。如果递归的dfs(v)返回了false,本体也返回false。
- 如果没有返回false,说明当前节点处理正常。令 (flag_u leftarrow 1),将 (u) 节点插入拓扑序,返回true。
核心代码如下:
int flag[maxn];
std :: vector <int> topo;
std :: vector <int> G[maxn];
int n, m;
bool dfs(int u) {
flag[u] = -1;
for (int i = 0; i < G[u].size(); ++i) {
int v = G[u][i];
if (flag[v] == -1) return false;
else if (flag[v] == 0) {
if (!dfs(v)) return false;
}
}
flag[u] = 1;
topo.push_back(u);
return true;
}
bool toposort() {
topo.clear();
for (int i = 1; i <= n; ++i) flag[i] = 0;
for (int i = 1; i <= n; ++i) {
if (flag[i] == 0) {
if (!dfs(i)) return false;
}
}
std :: reverse(topo.begin(), topo.end());
return true;
}
Kahn算法
Kahn算法有时候也叫做toposort的bfs版本。
算法流程如下:
- 将入度为 (0) 的点组成一个集合 (S)
- 从 (S) 中取出一个顶点 (u),插入拓扑序列。
- 遍历顶点 (u) 的所有出边,并全部删除,如果删除这条边后对方的点入度为 (0),也就是没删前,(u ightarrow v) 这条边已经是 (v) 的最后一条入边,那么就把 (v) 插入 (S)。
- 重复执行上两个操作,直到 (S = varnothing)。此时检查拓扑序列是否正好有 (n) 个节点,不多不少。如果拓扑序列中的节点数比 (n) 少,说明 (G) 非DAG,无拓扑序,返回false。如果拓扑序列中恰好有 (n) 个节点,说明 (G) 是DAG,返回拓扑序列。
也就是说,Kahn算法的核心就是维护一个入度为0的顶点。
核心代码如下:
int ind[maxn];
bool toposort() {
topo.clear();
std :: queue <int> q;
for (int i = 1; i <= n; ++i) {
if (ind[i] == 0) q.push(i);
}
while (!q.empty()) {
int u = q.front();
topo.push_back(u);
q.pop();
for (int i = 0; i < G[u].size(); ++i) {
int v = G[u][i];
--ind[v];
if (ind[v] == 0) q.push(v);
}
}
if (topo.size() == n) return true;
return false;
}
拓扑排序实现的时间复杂度
Kahn算法和dfs算法的时间复杂度都为 (operatorname{O}(E+V))。感兴趣的读者可以自证,这里不再详细阐述。
另外,如果要求字典序最小或最大的拓扑序,只需要将Kahn算法中的q队列替换为优先队列即可,总时间复杂度为 (operatorname{O}(E+Vlog V))。
拓扑排序的用途
说了这么半天,拓扑排序有什么用途吗?
- 判环
- 判链
- 处理依赖性任务规划问题
处理依赖性任务规划问题的模板是UVA10305,可以做做看。
本篇文章至此结束。