#1 规划
当前 NN(namenode)节点:
10.99.0.6 node01
10.99.0.14 node02
扩容 DN(datanode)节点:
10.99.0.31 node04
部署前要求:新扩容的 DN 机器需要与当前 HDFS 集群机器时间同步。
#2 新增扩容机器准备磁盘和创建目录
一键部署主控机中:
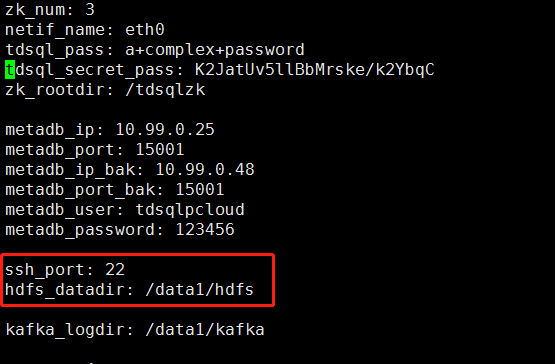
查看部署包中 tdsql_full_install_ansible/group_vars/all 文件 HDFS 目录
vim /data/tdsql_full_install_ansible/group_vars/all
新增 DN 机器上:
在新增 DN 机器上创建好目录,注意只是创建/data1 目录,不是创建/data1/hdfs。
# mkdir –p /data1
首先用 lsblk 查看磁盘信息
# lsblk
格式化为 xfs 文件系统(这里以 sdg 盘为例)
# mkfs.xfs -f /dev/sdg
修改/etc/fstab 文件,设置自动挂载到指定路径
/dev/sdg /data1 xfs defaults 0 0
挂载磁盘
# mount -a
用 df -hT 命令可以看到挂载成功
# df –hT
创建目录:
# mkdir –p /data1/hdfs
# chown -R tdsql:users /data1/hdfs
#3. 新增 DN 机器设置主机名和配置环境变量
新增 DN 机器:
hostnamectl set-hostname node04
所有的 HDFS 机器:
vim /etc/hosts
# BEGIN hdfs1 local host
10.99.0.6 node01
10.99.0.14 node02
10.99.0.16 node03
10.99.0.31 node04
# END hdfs4 local host
标红的地方是新增 DN 机器的 IP 地址,原有的 HDFS 集群机器有的内容最后添加标红内容,新增的 DN 机器直接复制以上内容到 hosts 文件。
新增 DN 机器:
/etc/profile 文件最后加上一键部署主控机/tdsql_full_install_ansible/roles/hdfs/files/profile_add 内容:
# vim /etc/profile
# BEGIN hadoop_env
export JAVA_HOME=/data/home/tdsql/jdk1.8.0_51
export CLASS_PATH=$JAVA_HOME/lib:$JAVA_HOME/jre/lib
export HADOOP_HOME=/data/home/tdsql/hadoop-3.0.3
export HADOOP_PID_DIR=/data/hadoop/pids
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib"
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export YARN_HOME=$HADOOP_HOME
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export HDFS_CONF_DIR=$HADOOP_HOME/etc/hadoop
export YARN_CONF_DIR=$HADOOP_HOME/etc/hadoop
export JAVA_LIBRARY_PATH=$HADOOP_HOME/lib/native
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
# END hadoop_env
使其生效
# source /etc/profile
#4. 传 jdk 包和 hadoop 安装包
新增的 DN 机器:
创建目录: mkdir -p /data/home/tdsql
传包:
rsync -avP /data/home/tdsql/jdk1.8.0_51 10.99.0.31:/data/home/tdsql/
rsync -avP /data/home/tdsql/hadoop-3.0.3 10.99.0.31:/data/home/tdsql/
修改权限:
chown -R tdsql:users /data/home/tdsql
原 HDFS 集群中 DN 机器上:
查看原 DN 是什么用户启动的:
ps –ef|grep datanode
#5. 启动 datanode 进程和验证
新增的 DN 机器:
su – tdsql
cd /data/home/tdsql/hadoop-3.0.3/sbin/
./hadoop-daemon.sh start datanode
验证 datanode 进程是否已经起来
jps
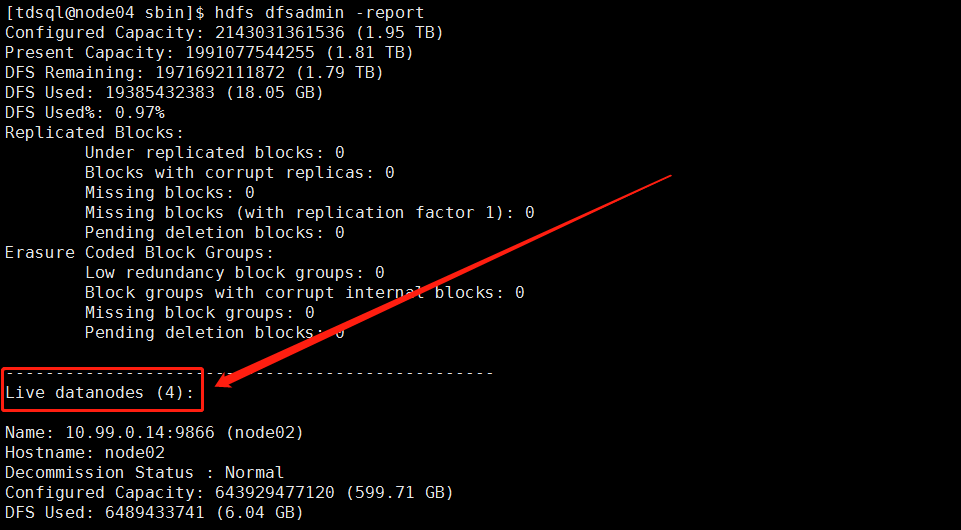
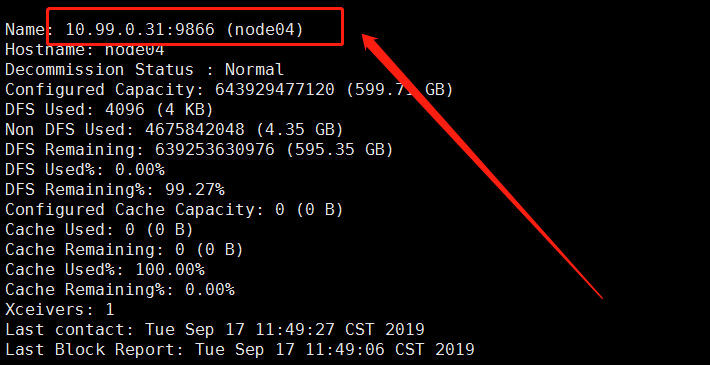
显示所有的 DN
hdfs dfsadmin –report
#6. 配置 DN balance
到其中一个 NN 节点上执行限制速度
hdfs dfsadmin -setBalancerBandwidth 102428800
后台进行跑 balance 进程
nohup hdfs balancer &