一、文件操作
1.1
打开文件的模式有:
- r,只读模式(默认)。
- w,只写模式。【不可读;不存在则创建;存在则删除内容;】
- a,追加模式。【可读; 不存在则创建;存在则只追加内容;】
"+" 表示可以同时读写某个文件
- r+,可读写文件。【可读;可写;可追加】
- w+,写读
- a+,同a
"U"表示在读取时,可以将 自动转换成 (与 r 或 r+ 模式同使用)
- rU
- r+U
"b"表示处理二进制文件(如:FTP发送上传ISO镜像文件,linux可忽略,windows处理二进制文件时需标注)
- rb
- wb
- ab
f1 = open(filename1,'r') f2 = open(filename2,'a') for line in f1: if "server" not in line: f2.write(line) #将filename1里面不包含server的内容复制到另一个filename2文件里
f1 = open('haproxy.txt','r') f2 = open('haproxy.txt.bak','a') n = 0 for line in f1: if n < 27: f2.write(line) # 把前面26行复制到另一个备份文件里 n += 1 f1.close() f2.close()
注意,操作完文件,一定要关闭,否则会一直占用内存
1.2 常用操作
f = open('lyrics') #打开文件
first_line = f.readline() #读取文件第一行内容,以文件行为单位
data = f.read()# 读取剩下的所有内容,文件大时不要用
f_list = f.readlines() #读取文件生成一个列表,将每行内容作为列表的一个元素。
f.seek(0) #将指针返回到文件的起始位置
f.tell() #查看指针位置
f.read(5) #从当前位置读取5个字符,以字符为单位
注意:对某一文件多次操作(一直未关闭),如前面有f.readline()操作,后面需要读取文件的所有内容f.read(),由于指针不在文件的开头位置,f.read()读取的是f.readline()后指针位置往后的内容
所以,f.read()前面需要f.seek(0),将指针回到文件起始位置,再从头开始读取。
补充:如果要读取一个大的文件并对其进行操作,可以每行每行的读取:f = open(filename,'r') ; for line in f: print(line) #print()打印会自带一个换行,所以会多出一个换行
1.3 with语句
为了避免打开文件后忘记关闭,可以通过管理上下文,即:

使用with语句可以同时打开多个文件
with open('file1.txt','w') as f1, open('file2.txt','w') as f2: #两个open使用逗号连接
...
1.4 其它语法
1 def close(self): # real signature unknown; restored from __doc__ 2 """ 3 Close the file. 4 5 A closed file cannot be used for further I/O operations. close() may be 6 called more than once without error. 7 """ 8 pass 9 10 def fileno(self, *args, **kwargs): # real signature unknown 11 """ Return the underlying file descriptor (an integer). """ 12 pass 13 14 def isatty(self, *args, **kwargs): # real signature unknown 15 """ True if the file is connected to a TTY device. """ 16 pass 17 18 def read(self, size=-1): # known case of _io.FileIO.read 19 """ 20 注意,不一定能全读回来 21 Read at most size bytes, returned as bytes. 22 23 Only makes one system call, so less data may be returned than requested. 24 In non-blocking mode, returns None if no data is available. 25 Return an empty bytes object at EOF. 26 """ 27 return "" 28 29 def readable(self, *args, **kwargs): # real signature unknown 30 """ True if file was opened in a read mode. """ 31 pass 32 33 def readall(self, *args, **kwargs): # real signature unknown 34 """ 35 Read all data from the file, returned as bytes. 36 37 In non-blocking mode, returns as much as is immediately available, 38 or None if no data is available. Return an empty bytes object at EOF. 39 """ 40 pass 41 42 def readinto(self): # real signature unknown; restored from __doc__ 43 """ Same as RawIOBase.readinto(). """ 44 pass #不要用,没人知道它是干嘛用的 45 46 def seek(self, *args, **kwargs): # real signature unknown 47 """ 48 Move to new file position and return the file position. 49 50 Argument offset is a byte count. Optional argument whence defaults to 51 SEEK_SET or 0 (offset from start of file, offset should be >= 0); other values 52 are SEEK_CUR or 1 (move relative to current position, positive or negative), 53 and SEEK_END or 2 (move relative to end of file, usually negative, although 54 many platforms allow seeking beyond the end of a file). 55 56 Note that not all file objects are seekable. 57 """ 58 pass 59 60 def seekable(self, *args, **kwargs): # real signature unknown 61 """ True if file supports random-access. """ 62 pass 63 64 def tell(self, *args, **kwargs): # real signature unknown 65 """ 66 Current file position. 67 68 Can raise OSError for non seekable files. 69 """ 70 pass 71 72 def truncate(self, *args, **kwargs): # real signature unknown 73 """ 74 Truncate the file to at most size bytes and return the truncated size. 75 76 Size defaults to the current file position, as returned by tell(). 77 The current file position is changed to the value of size. 78 """ 79 pass 80 81 def writable(self, *args, **kwargs): # real signature unknown 82 """ True if file was opened in a write mode. """ 83 pass 84 85 def write(self, *args, **kwargs): # real signature unknown 86 """ 87 Write bytes b to file, return number written. 88 89 Only makes one system call, so not all of the data may be written. 90 The number of bytes actually written is returned. In non-blocking mode, 91 returns None if the write would block. 92 """ 93 pass
补充:文件操作中的路径:可以详细参考os模块,subprocess模块,此处介绍可能常用到的。
1,windows上的路径用反斜杠分隔,如C:Program Files (x86)Google;linux、OS X上用正斜杠如:/usr/bin
如果想要程序运行在所有程序上怎么办呢?
可以用os.path.join()函数实现,如果将单个文件和路径上的文件夹名称的字符串传递给它,它会返回一个文件路径的字符串(对应系统),包含正确的路径分隔符:
在window下输入:
>>> a = os.path.join('C:','Program Files (x86)','Google') >>> a 'C:Program Files (x86)\Google' >>> os.chdir(a) >>> os.getcwd() 'C:\Program Files (x86)\Google' >>>
注意两个反斜杠,是因为需要转义
在linux上:

2,当前工作路径os.getcwd()
每个运行在计算机上的程序,都有一个“当前工作目录”,或cwd。利用os.getcwd()函数,可以取得当前工作路径的字符串,并可以利用os.chdir()改变它。
在Python IDLE里
>>> os.getcwd() 'D:\Programs\Python\Python35' >>>
在cmd里面启动

3,绝对路径和相对路径
有两种方法制定一个文件路径。
- “绝对路径”,总是从根文件夹开始。
- “相对路径”,它相对于程序的当前工作目录
特殊:点'.'和点点'..',它们不是真正的文件夹,而是可以在路径中使用的特殊名称。单个的句点,表示当前的目录,点点表示父目录。如:
>>> os.getcwd() 'D:\Programs\Python\Python35' >>> os.chdir('..') >>> os.getcwd() 'D:\Programs\Python' >>>
4,使用os.makedirs(path)创建新文件夹
类似于linux的mkdir -p,会创建必要的中间文件夹
5,处理绝对路径跟相对路径
- os.path.abspath(path)将返回参数的绝对路径的字符串。这是将相对路径转换为绝对路径的简便方法。
- os.path.isabs(path),如果参数是一个绝对路径,就返回True,如果参数是一个相对路径就返回False。
- os.path.relpath(path,start),经返回从start路径到path的相对路径的字符串。如果没有提供start,就使用当前工作目录为开始路径,也就是os.getcwd()。
>>> os.path.abspath('.') 'D:\python\Lib\idlelib' >>> os.path.abspath('..') 'D:\python\Lib' >>> os.path.isabs('..') False >>> os.path.relpath('D:\') '..\..\..' >>> os.path.relpath('D:\script') '..\..\..\script' >>> os.path.relpath('D:\script','D:\') 'script' >>>
调用os.path.dirname(path)将返回一个字符串,它包含path参数中最后一个斜杠之前的所有内容。调用os.path.basename(path)将返回一个字符串,它包含path参数中最后一个斜杠之后的所有内容。
>>> path = 'D:\scrpt\chapter1\day1' >>> os.path.dirname(path) 'D:\scrpt\chapter1' >>> os.path.basename(path) 'day1' >>>
如果同时需要一个路径的目录名称和基本名称,就可以调用os.path.split(),获得这两个字符串的元组,像这样:
>>> os.path.split(path) ('D:\scrpt\chapter1', 'day1') >>>
要获得路径中的每个文件夹的字符串列表,请使用字符串的split()方法,并根据os.path.sep中的字符串进行分隔。
>>> os.path.sep '\' >>> path.split(os.path.sep) ['D:', 'scrpt', 'chapter1', 'day1'] >>>
6,查看文件大小和文件夹内容
- 调用os.path.getsize(path)将返回path参数中文件的字节数。(路径的最后必须是文件而不能是文件夹,否则size是0)
- 调用os.listdir(path)将返回文件名字符串的列表,包含path参数中的每个文件。
>>> os.path.getsize('D:script') 0 >>> os.path.getsize('D:scriptlearning.txt') 3801 >>>
>>> os.listdir('D:script\python\study1')
['.idea', 'chapter 1', 'chapter 2']
如果我想知道某个目录下所有文件的总字节数:


1 import os 2 3 def totalsize(path): 4 size = 0 5 for filename in os.listdir(path): 6 size += os.path.getsize(os.path.join(path,filename)) 7 return size 8 9 total_size= totalsize('C:WindowsSystem32') 10 print(total_size)
7,检查路径有效性
如果你提供的路径不存在,许多python程序就会报错甚至崩溃。
- 如果path参数所指的文件或文件夹存在,调用os.path.exists(path)将返回True,否则返回False。
- 如果path参数存在,并且是一个文件,调用os.path.isfile(path)将返回True,否则返回False。
- 如果path参数存在,并且是一个文件夹,调用os.path.isdir(path)将返回True,否则返回False。
>>> os.path.exists('D:script\python') True >>> os.path.isfile('D:script\python') False >>> os.path.isdir('D:script\python') True
二、函数
2.1 函数介绍
函数是什么?
函数一词来源于数学,但编程中的「函数」概念,与数学中的函数是有很大不同的,具体区别,我们后面会讲,编程中的函数在英文中也有很多不同的叫法。在BASIC中叫做subroutine(子过程或子程序),在Pascal中叫做procedure(过程)和function,在C中只有function,在Java里面叫做method。
定义: 函数是指将一组语句的集合通过一个名字(函数名)封装起来,要想执行这个函数,只需调用其函数名即可
特性:
- 减少重复代码
- 使程序变的可扩展
- 使程序变得易维护
def sayhi(): #函数名 print("helelo world!") sayhi() #调用函数
带参数、返回值
def squ(a,b): c = a**b return c #返回函数执行的结果 result = squ(2,3) #执行函数,参数为a=2,b=3,将函数的执行结果赋给result print(result) 输出: 8
2.2 函数参数和局部变量
2.2.1 形参和实参
形参变量只有在被调用时才分配内存单元,在调用结束时,即刻释放所分配的内存单元。因此,形参只在函数内部有效。函数调用结束返回主调用函数后则不能再使用该形参变量
实参可以是常量、变量、表达式、函数等,无论实参是何种类型的量,在进行函数调用时,它们都必须有确定的值,以便把这些值传送给形参。因此应预先用赋值,输入等办法使参数获得确定值
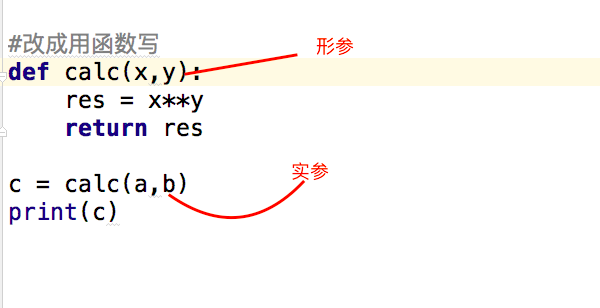
2.2.2 位置参数、默认参数、关键参数
例如,要写一个学生信息注册的函数,由于地址基本都是上海,可以将address默认设置为SH,只有个别不是上海的再单独写明,这样就可以省下很多时间
def student_info(name,age,address='SH'): print('%s is %d years old,from %s'%(name,age,address)) student_info('xiaohong',12) student_info('xiaowang',11,'BJ') 输出: xiaohong is 12 years old,from SH xiaowang is 11 years old,from BJ
如上面例子:student_info('xiaowang',11,'BJ'), 里面的三个参数就是位置参数,'xiaowang',11,'BJ'按照顺序对应name,age,address
'xiaowang',11,address='BJ',这里address='BJ'就是关键参数。
正常情况下,给函数传参数要按顺序,不想按顺序就可以用关键参数,只需指定参数名即可,但记住一个要求就是,关键参数必须放在位置参数之后
2.2.3 非固定参数(*args和**kwargs)

还可以有一个**kwargs

2.3 变量
全局与局部变量

2.4 返回值
要想获取函数的执行结果,就可以用return语句把结果返回
注意:
- 函数在执行过程中只要遇到return语句,就会停止执行并返回结果,so 也可以理解为 return 语句代表着函数的结束
- 如果未在函数中指定return,那这个函数的返回值为None
2.5 嵌套函数

函数内部定义的函数类似于局部变量,在函数外面是无效的
2.6 递归函数
在函数内部,可以调用其他函数。如果一个函数在内部调用自身本身,这个函数就是递归函数。

递归特性:
1. 必须有一个明确的结束条件
2. 每次进入更深一层递归时,问题规模相比上次递归都应有所减少
3. 递归效率不高,递归层次过多会导致栈溢出(在计算机中,函数调用是通过栈(stack)这种数据结构实现的,每当进入一个函数调用,栈就会加一层栈帧,每当函数返回,栈就会减一层栈帧。由于栈的大小不是无限的,所以,递归调用的次数过多,会导致栈溢出)
堆栈扫盲http://www.cnblogs.com/lln7777/archive/2012/03/14/2396164.html
2.7 匿名函数
匿名函数就是不需要显式的指定函数

2.8 高阶函数
变量可以指向函数,函数的参数能接收变量,那么一个函数就可以接收另一个函数作为参数,这种函数就称之为高阶函数

2.9 函数式编程
函数是Python内建支持的一种封装,我们通过把大段代码拆成函数,通过一层一层的函数调用,就可以把复杂任务分解成简单的任务,这种分解可以称之为面向过程的程序设计。函数就是面向过程的程序设计的基本单元。
函数式编程中的函数这个术语不是指计算机中的函数(实际上是Subroutine),而是指数学中的函数,即自变量的映射。也就是说一个函数的值仅决定于函数参数的值,不依赖其他状态。比如sqrt(x)函数计算x的平方根,只要x不变,不论什么时候调用,调用几次,值都是不变的。
Python对函数式编程提供部分支持。由于Python允许使用变量,因此,Python不是纯函数式编程语言。
一、定义
简单说,"函数式编程"是一种"编程范式"(programming paradigm),也就是如何编写程序的方法论。
主要思想是把运算过程尽量写成一系列嵌套的函数调用。举例来说,现在有这样一个数学表达式:
(1 + 2) * 3 - 4
传统的过程式编程,可能这样写:
var a = 1 + 2;
var b = a * 3;
var c = b - 4;
函数式编程要求使用函数,我们可以把运算过程定义为不同的函数,然后写成下面这样:
var result = subtract(multiply(add(1,2), 3), 4);
这段代码再演进以下,可以变成这样
add(1,2).multiply(3).subtract(4)
这基本就是自然语言的表达了。再看下面的代码,大家应该一眼就能明白它的意思吧:
merge([1,2],[3,4]).sort().search("2")
因此,函数式编程的代码更容易理解。
要想学好函数式编程,不要玩py,玩Erlang,Haskell,。
2.10 内置函数

内置参数详解 https://docs.python.org/3/library/functions.html?highlight=built#ascii
以大多数参考自alex的:http://www.cnblogs.com/alex3714/articles/5740985.html