框架图
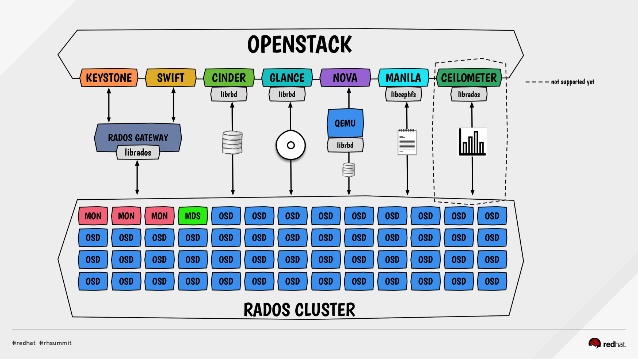
介绍
一种为优秀的性能、可靠性和可扩展性而设计的统一的、分布式文件系统
特点
CRUSH算法
Crush算法是ceph的两大创新之一,简单来说,ceph摒弃了传统的集中式存储元数据寻址的方案,转而使用CRUSH算法完成数据的寻址操作。
Crush确定PG和osd之间的多对多关系
CRUSH在一致性哈希基础上很好的考虑了容灾域的隔离,能够实现各类负载的副本放置规则,例如跨机房、机架感知等。
Crush算法有相当强大的扩展性,理论上支持数千个存储节点
高可用
Ceph中的数据副本数量可以由管理员自行定义,并可以通过CRUSH算法指定副本的物理存储位置以分隔故障域,支持数据强一致性
ceph可以忍受多种故障场景并自动尝试并行修复
高扩展性
Ceph不同于swift,客户端所有的读写操作都要经过代理节点。
一旦集群并发量增大时,代理节点很容易成为单点瓶颈。
Ceph本身并没有主控节点,扩展起来比较容易,并且理论上,它的性能会随着磁盘数量的增加而线性增长
特性丰富
Ceph支持三种调用接口:对象存储,块存储,文件系统挂载。三种方式可以一同使用。
在国内一些公司的云环境中,通常会采用ceph作为openstack的唯一后端存储来提升数据转发效率
在线修改配置文件
Ceph 生态系统架构
1. Clients:客户端(数据用户)
2. cmds:Metadata server cluster,元数据服务器(缓存和同步分布式元数据)
3. cosd:Object storage cluster,对象存储集群(将数据和元数据作为对象存储,执行其他关键职能)
一块硬盘拥有一个 osd daemon 进程,这个守护进程单独管理一块硬盘
一个osd节点上可以对应多个osd daemon
4. cmon:Cluster monitors,集群监视器(执行监视功能)
文件存储过程
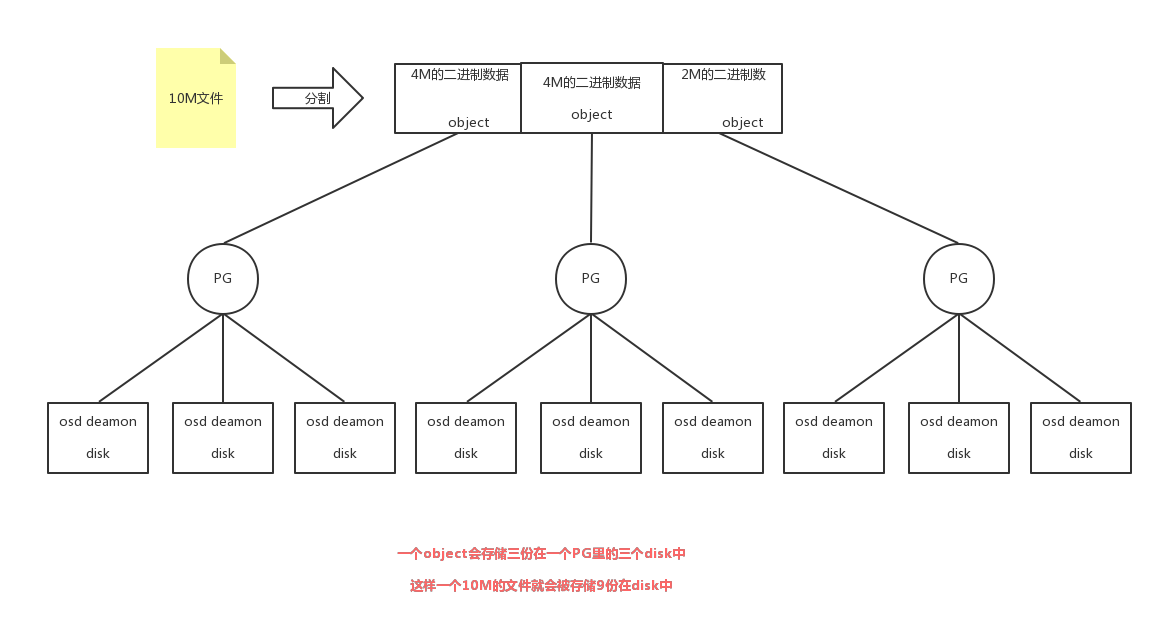
1 在qemu层次会调用librbd将文件转换为二进制,并分成三份,每一份称为object,一份object拥有一个ID号(默认4M切割一个object单位) 2 客户端会调用librbdos连接到集群中monitor机器上,从该机器获取到crushmap(PG和osd的映射关系) 3 客户端知道自己的存储pool id和pg count、整个存储信息 4 获取pool id 和object id的哈希值能计算出模为[pg count]的pg id 5 pg通过crushmap将数据object交付给组长osd daemon 6 osd daemon负责存储和备份数据到disk的工作 7 通常1T的disk对应需要预留1G的memory空间
关联关系
PG和object是多对一的关系
PG和osd daemon是多对多的关系
osd daemon和disk是一对一的关系
集群分类
1. disk集群
2. osd daemon集群
可以一个硬盘一个osd daemon(最好的方案)
可以一个硬盘几个分区几个osd daemon
可以几个硬盘做一个raid一个osd daemon
3. monitor daemon
一台机器只能放一个monitor软件
可以有若干个monitor节点(通常是奇数个)
...
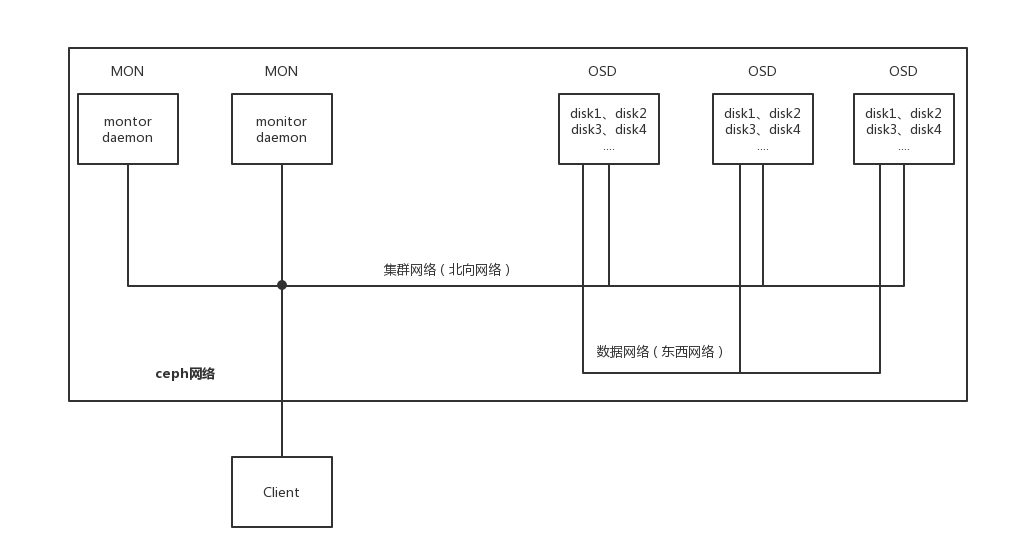
一个简单网络架构
n台monitor、n个osd节点(运行多个osd daemon)
集群网络(北向网络)
一定要是万兆网络
与客户端沟通的网络
n个节点都连接上
复制网络(东西网络)
osd daemon之间的数据复制
万兆网络
PG
将若干个osd daemon集中到一个PG管理 epoach:单调递增的版本号(垃圾清理、文件扫描时使用) 拥有一个acting set 这是一个有序列表,里面存放的是osd,排在第一位的osd是组长,负责存储任务的调度 第一个为primary osd ,其它 replicated osd up set:acting set过去版本(通常和acting set一样,当pg出现tmp状态时不一致) pg tmp:osd出现故障时 如果副本数定义为3,那么PG重的osd daemon个数就为3个 状态(任意一台monitor:ceph -s) creating 学习PG组信息 peering 认识PG组成员 active 可以写数据了 clean 数据备份也完成 stable 组内成员没有在2S内汇报状态信息 backfilling 有新osd加入PG内,组内中一个成员向新加成员做全量拷贝 recovery 老组员恢复状态重新加入,组内中一个成员向老成员做增量拷贝
OSD Daemon
功能 1. 存储和复制 2. 监控自己以及组内其他osd daemon的状态,如果自己宕了,同组的其它成员会代替组长报告给monitor 状态(默认每2S汇报自己和组内其他osd状态给mon) up 可以提供IO down 挂掉,不能提供IO 300S还不汇报状态数据 --> out in 有数据 out 没数据 被踢出PG
MON功能
1. mon集群通信功能 2. 接收osd daemon汇报的状态 3. pg-monitor:检测新创建的pool,有无需要创建的PG。如果有,进入creating状态,将创建信息放入队列中。 通过crush算法找到pg包含的osd,进入peering状态,定义好PG组长和组员,发送消息给新pg的组长,由组长想新PG信息发送给组员
rados
能够在动态变化和异质结构的存储设备机群之上提供一种稳定、可扩展、高性能的单一逻辑对象(Object)存储接口和能够实现节点的自适应和自管理的存储系统
通过这种分布方式,授权给OSDs自主管理对象复制,OSD集群扩展,错误检测和恢复的权利,来实现在能力和总体性能的线性增长。
RADOS将文件映射到Objects后利用Cluster Map通过CRUSH计算而不是查找表方式定位文件数据在存储设备中的位置。省去了传统的File到Block的映射和BlockMap管理
pool
1. 类似于vg的概念,不是真实的分区,本质就是一堆PG的集合 2. 副本数 3. crush规则(pg--->osd:acting set) 4. 用户及权限
pool数据存储类型
1. 复杂类型 2. 纠错码类型 缺点 速度慢 不能做所有ceph操作(垃圾清理、scrubling天size校验周hash校验)
ceph缓存机制
1. 客户端:rbd缓存 请求调用流程:libvirt --> qemu(io) --> librbd(librados) --> rbd cache (-->1.write back asyn机制 2.write through sync机制) ---> ceph:rados write back 客户端把存储数据先存一份到本地缓存,在从缓存取数据到ceph 优点 速度快 缺点 不安全 数据不一致 适用场景 对数据安全性不高 使用于读写混合型的 write through 边写边存数据到ceph 优点 读数据速度快 安全性高 缺点 写数据速度慢 适用场景 读多写少 2. ceph服务端:cache tiering 请求调用流程: Client --> sshd pool(一发送读写命令马上返回结果)--> volumes pool(真实的存储池) 优点 可以提升性能 缺点 成本高 性能提升不明显 二者对比 一个是内存级别的,一个是sshd缓存 服务器端缓存不存在数据不一致
ceph数据存储
数据存储请求到主osd,osd写入自己的日志文件(带日志文件的文件系统),然后同步给从osd,从osd写入自己的日志文件系统,然后把结果返回给主osd 主osd接收到所有从osd发送过来的结果,主osd在把结果返回给客户端 等主osd把自己日志文件中的数据同步到真实存储数据区,并且从osd也同步到真实存储数据区返回了结果,主osd再次向客户端返回一个结果 提高效率解决方案 日志文件磁盘使用固态硬盘 一个osd节点案例 8个120G的固态盘SAS口 每个固态盘要分成两个分区,因为每块磁盘对应有一个日志盘 固态盘最好不要分区,默认最小分区4K字节,但是固态盘还支持以前的MBR分区方案,导致边缘扇区效率不高 固态盘最好不使用太多的空间,分小分区,否则容易出现写放大现象,还要预留一部分空间给固态盘做优化整理 16个2T的机械盘SAS口 一个公式 日志盘大小 = min[网络带宽、硬盘带宽] * 脏数据最大同步时间 * 2 37.5G = min[10bps,12bps] / 8 * 15 * 2 每个机械盘分区为40G大小 2个SATA做系统盘raid1