1. 简介
Go的优点
-
编译速度快
-
天生支持并发
编写并发程序非常简便
-
高效GC回收
-
runtime系统调度机制
-
语法简洁
-
面向对象语言
-
目前大厂钟爱
Go的缺点
- 包管理还不完善:大部分包私人托管在github上
- 没有泛型
- 争议:将所有Exception都用Error处理
Go适合做什么
- 云计算基础设施:docker, k8s, cloudflare CDN
- 基础后端软件: tidb, influxdb
- 微服务
- 互联网基础设施: 以太坊, hyperledger
2. 基础语法
hello world
package main
import "fmt"
func main(){
fmt. Println("hello world.")
}
特点
-
行末可不加分号,编译器会自动加
因此有一些换行要求,如:
- 函数起始大括号 { 一定要和函数名同一行
-
主程序包名为 main
类型
- bool
- 数值类型
- int8, int16, int32, int64, int
- uint8, uint16, uint32, uint64, uint
- float32, float64
- complex64, complex128
- byte
- rune
- string
-
默认就用int,32位机器就是int32
-
complex是复数, complex64是实部虚部都是float32的复数,complex128都是float64
// 几种初始化复数变量方法 f := 10 + 5i f := complex(10, 5) -
byte是uint8的别名
-
rune是int32的别名
类型转换
Go是强类型语言,不会自动转换类型。
比如: c = a+b 如果a和b的类型不同,就不能相加,而c中可以,int+float会转为float。
和c、java一样,通过 类型(变量)强制转换类型。int(b)
变量和常量
声明变量
如果变量未被赋值,Go 会自动地将其初始化,赋值该变量类型的零值
1. var a int // 使用var起始表示变量,先写变量名,再写类型
2. var b int = 100 // 给定初始化值,默认为0
3. var c = 100 // var可以根据初始化值推测类型
4. d := 100 // 使用 := 是最常用的,会根据值推断类型
方法4最常用,但是不支持声明全局变量
//多个变量
var {
a int = 100
b string = "abc"
}
var a, b int = 100, 200
var a, b = 100, "abc"
常量
const pi float32 = 3.14
const {
A = 100
B = 200
C = 300
}
// 枚举
// iota会从 0 “逐行”累加,下面即 A=0,B=1,C=2
const {
A = iota
B
C
}
// iota还可以进行一些运算
const {
A = iota * 2
B
C
D = iota + 2
F
}
// 以上 A=0 B=2 C=4 D=5 F=6
打印
引入 fmt 包
fmt.Println("hello")
-----
var a int = 100
fmt.Println("a = ", a)
-----
var a int = 100
fmt.Ptintf("a = %d", a)
fmt.Ptintf("type of a is %T", a) // %T打印变量类型
函数
函数结构
// 无返回值 无形参
func funcA {
...
}
// 单返回值 单形参
func funcA(a int) int {
return a + 1
}
//单返回值 多形参
func funcA(a int, b int) int {
return a + b
}
// 多返回值
func funcA(a int, b int) (int, int) {
return a+1, b*2
}
// 指定返回值名称
func funcA(a int, b int) (r1 int, r2 int) {
r1 = a + 1
r2 = b * 2
return // 之前赋值过了,可以直接return
}
init函数
go程序执行过程:
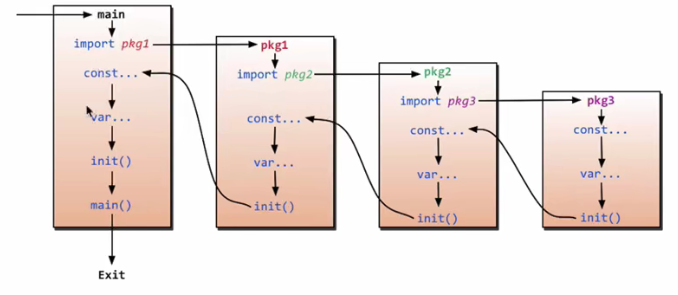
每个包都可以有自己的init函数,不定义就没有。init函数用于执行一些资源初始化,不能显示调用,也没有参数和返回值。
defer
延迟函数defer。含有 defer 语句的函数,会在该函数将要返回之前,调用另一个函数。类似AOP的功能。通常用于释放资源,错误处理。
匿名函数
函数可以没有名字,匿名函数可以直接调用。
func main() {
func() {
fmt.Println("hello world first class function")
}()
}
func main() {
func(n string) { // 还可以接收参数
fmt.Println("Welcome", n)
}("Gophers")
}
闭包
闭包是由函数及其相关引用环境组合而成的实体(即:闭包=函数+引用环境)。
当一个匿名函数所访问的变量定义在函数体的外部时,就产生了闭包:
func main(){
a := 5
func() {
fmt.Println("a=",a)
}()
}
匿名函数中并没有定义a,a是调用它的环境中定义的,它只是引用环境变量。
func main() {
a := 5
f1 := func() {
a++
fmt.Println("a=",a)
}
f1()
f1()
}
闭包所引用的环境变量会在堆中新建一份,而不是使用栈中的那份。
func adda() func() {
a := 5
c := func() {
a++
fmt.Println("a=",a)
}
return c
}
func main() {
f1 := adda()
f2 := adda()
f1()
f2() // f1、f2产生了闭包, 在堆中会生成属于该闭包的环境变量a
adda()() // 直接调用没产生闭包,a使用的依然是栈中的
fmt.Println()
f1()
f2()
adda()()
}
上述程序输出:
a= 6
a= 6
a= 6
a= 7
a= 7
a= 6
头等函数
go是支持头等函数特性的语言。头等函数特性是指,函数可以赋值给变量,可以作为其他函数的参数,作为函数的返回值。这个特性的意思是 函数是类似类型一样的“头等公民”。
头等函数的特性使得函数式编程变得非常灵活。
看看将一个匿名函数赋值给变量,然后调用:
func main() {
a := func() {
fmt.Println("hello world first class function")
}
a()
fmt.Printf("%T", a)
}
函数也类似一种类型,我们也可以通过 type 定义自己的函数类型。
type add func(a int, b int) int // add 是该函数类型的名称
func main() {
// 变量a是add类型,并赋值了一个符合add类型签名的函数
var a add = func(a int, b int) int {
return a + b
}
s := a(5, 6)
fmt.Println("Sum", s)
}
函数作为参数传递给其他函数:
func simple(a func(a, b int) int) {
fmt.Println(a(60, 7))
}
func main() {
f := func(a, b int) int {
return a + b
}
simple(f)
}
函数作为返回值:
func simple() func(a, b int) int {
f := func(a, b int) int {
return a + b
}
return f
}
func main() {
s := simple()
fmt.Println(s(60, 7))
}
使用示例1:
// 过滤数据
type student struct {
firstName string
lastName string
grade string
country string
}
// 传入过滤函数就可以过滤
func filter(s []student, f func(student) bool) []student {
var r []student
for _, v := range s {
if f(v) == true {
r = append(r, v)
}
}
return r
}
func main() {
s1 := student{ "Naveen","Ramanathan", "A","India",}
s2 := student{ "Samuel","Johnson","B","USA",}
s := []student{s1, s2}
f := filter(s, func(s student) bool { // 调用时传入过滤函数
if s.grade == "B" {
return true
}
return false
})
fmt.Println(f)
}
使用示例2:
// 将切片的每个元素扩大5倍
func iMap(s []int, f func(int) int) []int {
var r []int
for _, v := range s {
r = append(r, f(v))
}
return r
}
func main() {
a := []int{5, 6, 7, 8, 9}
r := iMap(a, func(n int) int {
return n * 5
})
fmt.Println(r)
}
包
Go程序执行的入口是main包下的main函数
一般来说,属于某一个包的源文件都应该放置于一个和包同名的文件夹里。
-
空白标识符
导入包却不使用在Go中非法,编译会报错,这是为了极致压缩编译时间。
有时只需要某个包的init,而不用到它。可以这样做避免报错
import _ packagename"_"是空白标识符,用于屏蔽一些错误,避免报错。
if-else
if a > 0 {
...
} else if a < 0{
...
} else {
...
}
if 还有另外一种形式,它包含一个 statement 可选语句部分,它在条件判断之前运行。
if a = 1; a > 0 {
...
} else {
...
}
注意 else 和 if 的结束大括号在同一行,不在同一行会报错,因为 go 中的分号是自动添加的,不在同一行if结束就会自动加上分号。
循环
和c一样,分号和逗号一样的用法,不过没有括号而已
for init; condition; post {
}
---
for i := 0; i < 10; i++ {
...
}
---
// 可以作while用
i := 0
for i < 10 {
...
i++
}
---
// 死循环
for {
...
}
switch
finger := 4
switch finger {
case 1:
fmt.Println("Thumb")
case 2:
fmt.Println("Index")
case 3:
fmt.Println("Middle")
case 4:
fmt.Println("Ring")
case 5:
fmt.Println("Pinky")
default:
fmt.Println("incorrect finger number")
case 可以有多个匹配项,用逗号分隔。
3. 常用类型
数组
// 定义数组
var arr [10]int
arr := [10]int
arr := [3]int{1,2,3}
arr := [...]int{1,2,3,4,5} // 使用...将自动计算数组长度
len(arr) // 获取数组长度
// 遍历
// range方法
for i, v := range arr {
fmt.Printf(v)
}
// 如果不需要索引
for _, v := range arr {
...
}
go中数组的大小是类型的一部分,也就是说 int[5] 和 int[10] 是两种数据类型,在设置形参的时候可以指定数组大小,传入的数组就必须和指定的大小相等。这样使用起来会比较麻烦,所以go还有切片slice。
此外与java不同的是,go中的数组是值类型而不是引用类型。也就是说数组变量传递是拷贝一份数组,java中数组是引用对象,拷贝的是对象引用地址。
切片 slice
切片只是对数组的引用。
// 创建
a := [5]int{1,2,3,4,5}
var s []int = a[1:3] //创建一个切片,引用数组a的a[1]-a[3]
var s []int{1,2,3} // 创建一个数组,并且返回一个对该数组引用的切片
var s []int = make([]int,3) //使用make创建切片,长度和容量为3
len(s) // 获取长度
cap(s) // 获取容量
切片有长度和容量两个属性。长度是切片包含的元素个数,容量是当前能容纳的元素个数,切片可以自动扩容。
-
切片追加元素
使用 append 可以追加新的元素,并且超过容量后会进行扩容,扩大2倍。扩容是将原来的元素复制到一个更大的数组中。
// 追加元素 s := []int{1,2,3} s = append(s, 4) // 追加一个切片 "..." s1 := []int{1,2,3} s2 := []int{4,5} s1 = append(s1, s2...)
map
make(map[type of key]type of value) 是创建 map 的语法。
map必须初始化后才能使用,未初始化之前它是零值 nil,通常使用make初始化。
map也是引用类型。
var mymap map[string]int // 未初始化
mymap = make(map[string]int) // 初始化
// 或者
mymap := make(map[string]int)
// 或者创建时指定元素来初始化,那么也就不需要make
mymap := map[string]int {
"a": 1,
"b": 2, // 注意最后的","也是必须的
}
map用起来和数组一样。
mymap := make(map[string]int)
// 给map添加元素
mymap["a"] = 1
mymap["c"] = 3、
// 获取元素
v := mymap["a"]
// 获取不存在的元素返回改类型的零值
v, has := map["a"] // 第二个返回值是bool类型,map中存在该元素则为true
// 遍历
for k,v := range mymap {
...
}
// 删除元素
delete(mymap, "a")
string
go中的string是一个字节切片。(go中采用utf-8编码)
所以我们可以通过 [i] 访问每个字节。虽然utf-8大部分常用字符都是一个字节,不过也有很多字符编码成两个或三个字节。go中提供了 rune (意:符文)类型,rune代表一个代码点,无论多少个字节的字符都可以用一个rune表示。
// 可以将字符串转为rune类型,然后遍历
s := "hello 你好"
runes := []rune(s) // go中这些转换还是很方便
for i,v := range runes{
...
}
// 或者直接使用字符串的range遍历,它是通过字符而非字节遍历
for i,v := range s{
...
}
与java一样,string也是不可修改的。
指针
和c一样,*T代表指向T类型的指针,使用&取变量地址。不一样的是go不支持指针运算,例如 p++ 非法。
指针的零值是 nil,引用变量的零值都是 nil,相当于 null 。
结构体
// 定义
type Person struct {
name string
age int
}
// 创建
p1 := Person{"Peng",24}
// 创建时若未初始化字段,则为字段类型的零值
相同类型的字段可以写在同一行,更加紧凑。
还可以使用匿名结构体,可以即时的创建一个匿名结构体变量来使用。
// 提前没有定义
p2 := struct {
name string
age int
}{
"Peng",24
}
...
和其他语言一样,使用 . 访问结构体字段。
4. 面向对象
go中似乎是采用结构体取代类。
方法
go不是一个纯面向对象的语言,而且没有class,为了达到与class相似的效果,go新增了一个特性叫做“方法”。
type Person struct {
name string
age int
}
func (p Person) show() {
fmt.Printf("%s is %d", p.name, p.age)
}
func main(){
p1 := Person {"Peng", 24}
p1.show()
}
如上,在show方法中 func 和 方法名之间加入了一个特殊的接收器类型,那么我们可以像调用对象的方法一样,这样写起来的代码就很有面向对象的感觉了。
加上了接收器,我们就可以称它为该接收器类型的一个方法,而不是普通的函数了。
相同名称的方法可以定义在不同类型上,而函数不允许重名。
结构体定义和方法定义必须在一个包中。
指针接收器
上述的接收器是值接收器,也就是说方法的调用者是将接收器复制一份传给方法,在方法内部对接收器字段的任何改变都不影响调用者结构。
有时候我们需要使用引用传递而非值传递,这就要使用指针接收器。
func (p *Person) changeAge(newAge int){
p.age = newAge
}
如果是指针接收器,一般来说我们需要通过接收器指针来调用方法,如写成&p.changeAge(18),不过go种提供了语法糖让我们可以省略 &。
匿名字段的方法
type Person struct {
name string
age int
Child // Child 也是一个结构体,假设其有一个方法 play()
}
// 匿名字段的方法可以直接这样调用
p.play()
在非结构体上的方法
非结构体类型即是语言自带的类型,如int,string。
// 给 int 类型新增一个方法
func (a int) add(b int) {
}
func main() {
}
// 这样无法通过编译,因为int类型的定义和方法定义不在一个包中
可以这样解决:
type myInt int
func (a myInt) add(b myInt) myInt {
return a + b
}
接口
go中也有接口,这样定义:
type TestInterface interface {
// 接口方法签名
// ...
}
go中的接口实现是隐式的,不需要 implement 这样的关键字,一个类型定义了接口中的所有方法就说明它实现了这个接口。
空接口
没有方法的接口,表示为 interface{},所有类都实现了空接口。因此可以使用空接口作为形参,表示函数可以接收任何类型。
func test(i interface{}) {
...
}
类型断言
i.(T),断言接口 i 的具体类型是不是 T。
func test(i interface{}) {
v := i.(int) // 若传入类型不是int,则会报错
}
// 不希望报错的用法
v, ok := i.(int) // 如果不是int,则v赋值为int类型的零值,ok为fasle
断言还可以结合 switch 使用:
func findType(i interface{}) {
switch i.(type) {
case string:
fmt.Printf("I am a string and my value is %s\n", i.(string))
case int:
fmt.Printf("I am an int and my value is %d\n", i.(int))
case MyInterface:
fmt.Printf("I am an class, and I implement MyInterface interface)
default:
fmt.Printf("Unknown type\n")
}
} // 这很有意思
嵌套接口
type SalaryCalculator interface {
DisplaySalary()
}
type LeaveCalculator interface {
CalculateLeavesLeft() int
}
type EmployeeOperations interface {
SalaryCalculator
LeaveCalculator
}
结构体取代类
go中使用结构体来实现类的功能。面向对象语言中类是通过构造器新建的,go中也可以实现类似的做法。
如果你想创建一个类,那么单独把这个结构体放到一个包中。
如果将结构体的名称首字母小写,那么该结构体将不可引用,也就是说我们不能 p := person.Person {...} (person包中的Person结构体)这样来得到一个结构体变量。类似构造器,go中的习惯是在该结构体的包中定义一个名称为 New 的函数来模拟构造器。
package person
type person struct {
name string
age int
}
func New(name string, age int) person {
p := person {name, age}
return p
}
package main
import "person"
func main() {
p := person.New("Peng", 24) // 通过 New 新建“类对象”
}
组合取代继承
go使用组合来代替继承。结构体可以随意嵌套,这就是go的组合。
如果结构体A内嵌套了结构体B字段,那我们可以在A中直接访问B的字段,好像这些字段属于外部结构体一样。好像B就是A的子类。
多态
使用接口就可以实现多态。
5. 并发
- 并行不一定会加快运行速度,因为并行运行的组件之间可能需要相互通信。在我们浏览器的例子里,当文件下载完成后,应当对用户进行提醒,比如弹出一个窗口。于是,在负责下载的组件和负责渲染用户界面的组件之间,就产生了通信。在并发系统上,这种通信开销很小。但在多核的并行系统上,组件间的通信开销就很高了。所以,并行不一定会加快运行速度.
go 原生支持并发,使用Go 协程(Goroutine) 和信道(Channel)来处理并发。
go协程
Go 协程可以看作是轻量级线程。
-
相比线程而言,Go 协程的成本极低。堆栈大小只有若干 kb,并且可以根据应用的需求进行增减。而线程必须指定堆栈的大小,其堆栈是固定不变的。
-
Go 协程会复用OS 线程。即使程序有数以千计的 Go 协程,也可能只有一个线程。如果该线程中的某一 Go 协程发生了阻塞(比如说等待用户输入),那么系统会再创建一个 OS 线程,并把其余 Go 协程都移动到这个新的 OS 线程。好消息是程序员不需要关心这些细节。
-
Go 协程使用信道来进行通信。信道用于防止多个协程访问共享内存时发生竞态条件(Race Condition)。
启动协程
在调用函数或者方法时,在前面加上 go,则会创建一个协程并发运行。
main 函数运行在一个特有的协程上,称为 Go 主协程。主协程结束,程序也即结束。
func hello() {
fmt.Println("Hello world goroutine")
}
func main() {
go hello()
time.Sleep(1 * time.Second) // 等待上面协程运行
fmt.Println("main function")
}
信道
类似linux中的管道,用于协程间通信。
无缓冲信道
信道 chan 创建需要关联一种类型,然后该信道就只能传输该类型数据。
// 创建信道
a := make(chan int)
// 读取信道
data := <- a
// 写入信道
a <- data
// 注意,读写默认都是阻塞的。
使用信道:
func hello(done chan bool) {
...
done <- true
}
func main() {
done := make(chan bool)
go hello(done)
<-done // 没有接受值也是可以的
}
以上程序利用信道实现了通信,协程hello在运行完后向信道写入信号,主协程则阻塞等待直到信道信号的到来。
再看一个使用信道的例子:
// 程序目的是计算一个数中每一位的平方和与立方和。设置了两个协程,一个计算平方和,一个计算立方和,主协程计算它俩的和。
func calcSquares(number int, squareop chan int) {
sum := 0
for number != 0 {
digit := number % 10
sum += digit * digit
number /= 10
}
squareop <- sum
}
func calcCubes(number int, cubeop chan int) {
sum := 0
for number != 0 {
digit := number % 10
sum += digit * digit * digit
number /= 10
}
cubeop <- sum
}
func main() {
number := 589
sqrch := make(chan int)
cubech := make(chan int)
go calcSquares(number, sqrch)
go calcCubes(number, cubech)
squares, cubes := <-sqrch, <-cubech
fmt.Println("Final output", squares + cubes)
}
以上,可以看到可以通过信道将结果返回,非常高效方便。
关闭信道:
通常由发送方关闭信道,告知接收方不再发送数据。从信道接收数据时,可以多使用一个变量检查信道是否已经关闭:
v,ok := <- ch
遍历信道:
func producer(chnl chan int) {
for i := 0; i < 10; i++ {
chnl <- i
}
close(chnl)
}
func main() {
ch := make(chan int)
go producer(ch)
for v := range ch { // 循环会直到信道关闭才结束
fmt.Println("Received ",v)
}
}
-
死锁
上面说到无缓冲信道读写都是阻塞的,有写必须要有读。如果只有写入,没有协程读取,程序就会 出现死锁。
单向信道
上述所说都是双向信道,go还提供单向信道,即只能写或只能读。
通常我们不会直接创建一个单向信道,而是将双向信道转换为单向传入函数,这样在函数中使用信道就只能读或写,用于保护信道信息安全。
// 使用 chan<- 定义只能写入的信道, <-chan 定义只能读的信道
func sendData(sendch chan<- int) {
sendch <- 10
}
func main() {
cha1 := make(chan int)
go sendData(cha1)
fmt.Println(<-cha1)
}
缓冲信道
上述所说的无缓冲信道中不能缓冲数据,因此读写必须成对出现。此外还有缓冲信道,信道可以指定缓冲容量,无缓冲信道容量默认为0.
ch := make(chan type, capacity)
缓冲信道容量未满之前写入不会阻塞,数据未被及时读取导致容量满了仍然会阻塞。
WaitGroup
WaitGroup是一个结构体类型,用于等待一批Go协程执行结束,类似于java中的circlebarrier?
func process(i int, wg *sync.WaitGroup) {
fmt.Println("started Goroutine ", i)
time.Sleep(2 * time.Second)
fmt.Printf("Goroutine %d ended\n", i)
wg.Done()
}
func main() {
no := 3
var wg sync.WaitGroup
for i := 0; i < no; i++ {
wg.Add(1)
go process(i, &wg)
}
wg.Wait()
fmt.Println("All go routines finished executing")
}
waitgroup使用计数器工作,Add方法增加计数器,Done将计数器减一,Wait方法则阻塞直到计数器为0。
注意,将waitgroup作为参数传给协程时,应该传递地址,否则协程得到的是一个拷贝。
使用缓冲信道实现工作池
go中的worker pool其实也就是线程池,不过go中是协程。
看一个例子,这个例子中工作是计算一些随机数的每个位之和。
package main
import (
"fmt"
"math/rand"
"sync"
"time"
)
type Job struct {
id int
randomno int
}
type Result struct {
job Job
sumofdigits int
}
var jobs = make(chan Job, 10)
var results = make(chan Result, 10)
func digits(number int) int {
sum := 0
no := number
for no != 0 {
digit := no % 10
sum += digit
no /= 10
}
time.Sleep(2 * time.Second)
return sum
}
func worker(wg *sync.WaitGroup) {
for job := range jobs {
output := Result{job, digits(job.randomno)}
results <- output
}
wg.Done()
}
func createWorkerPool(noOfWorkers int) {
var wg sync.WaitGroup
for i := 0; i < noOfWorkers; i++ {
wg.Add(1)
go worker(&wg)
}
wg.Wait()
close(results)
}
func allocate(noOfJobs int) {
for i := 0; i < noOfJobs; i++ {
randomno := rand.Intn(999)
job := Job{i, randomno}
jobs <- job
}
close(jobs)
}
func result(done chan bool) {
for result := range results {
fmt.Printf("Job id %d, input random no %d , sum of digits %d\n", result.job.id, result.job.randomno, result.sumofdigits)
}
done <- true
}
func main() {
startTime := time.Now()
noOfJobs := 100
go allocate(noOfJobs)
done := make(chan bool)
go result(done)
noOfWorkers := 10
createWorkerPool(noOfWorkers)
<-done
endTime := time.Now()
diff := endTime.Sub(startTime)
fmt.Println("total time taken ", diff.Seconds(), "seconds")
}
select
用于在多个信道中做选择。select 会一直阻塞,直到发送/接收操作准备就绪,如果有多个操作同时准备好,那么会随机执行其中一个。语法类似switch。
func server1(ch chan string) {
time.Sleep(6 * time.Second)
ch <- "from server1"
}
func server2(ch chan string) {
time.Sleep(3 * time.Second)
ch <- "from server2"
}
func main() {
output1 := make(chan string)
output2 := make(chan string)
go server1(output1)
go server2(output2)
select {
case s1 := <-output1:
fmt.Println(s1)
case s2 := <-output2:
fmt.Println(s2)
}
}
上述例子中,明显server2更快发送数据,因此select会执行case2。
select还可以有default,没有case满足时,执行default。
Mutex
就是锁。提供两个方法 Lock 和 Unlock。
看个使用的例子:
var x = 0
func increment(wg *sync.WaitGroup, m *sync.Mutex) {
m.Lock()
x = x + 1
m.Unlock()
wg.Done()
}
func main() {
var w sync.WaitGroup
var m sync.Mutex
for i := 0; i < 1000; i++ {
w.Add(1)
go increment(&w, &m)
}
w.Wait()
fmt.Println("final value of x", x)
}
其实使用缓冲信道也可以实现锁。
var x = 0
func increment(wg *sync.WaitGroup, ch chan bool) {
ch <- true
x = x + 1
<- ch
wg.Done()
}
func main() {
var w sync.WaitGroup
ch := make(chan bool, 1)
for i := 0; i < 1000; i++ {
w.Add(1)
go increment(&w, ch)
}
w.Wait()
fmt.Println("final value of x", x)
}
容量为1的缓冲信道,第一个协程向信道写入数据后,必须要执行完x=x+1,并将数据消耗掉,其他协程才能继续往信道中写入,否则在写入处阻塞。
6. 错误处理
go中所有的异常、错误统称为错误 error 。
// 打开文件
f, err := os.Open("/test.txt")
if err != nil {
fmt.Println(err)
return
}
fmt.Println(f.Name(), "opened successfully")
err 接收一个 error 类型,如果没有出错,err 则为 nil。
error 是一个接口类型:
type error interface {
Error() string
}
可能出错的类型都可以实现它。fmt.Println(err) 在打印错误时,会在内部调用 Error() string 方法来得到该错误的描述。
判断错误类型
看看常见的error使用方法:
-
断言
看看 Open 函数返回的错误类型:
type PathError struct { Op string Path string Err error } func (e *PathError) Error() string { return e.Op + " " + e.Path + ": " + e.Err.Error() }它对 error 进行了包装,是一个PathError。
f, err := os.Open("/test.txt") // 可以通过断言看是不是PathError类型,然后就可以提取出错的路径 if err, ok := err.(*os.PathError); ok { fmt.Println("File at path", err.Path, "failed to open") return } -
直接比较
error可以直接用 == 比较。看个例子:
filepath包中的Glob用于返回所有满足glob模式的文件名,如果模式格式不对,则会返回一个 ErrBadPattern 错误,该错误定义如下:
var ErrBadPattern = errors.New("syntax error in pattern")// 使用的时候 files, error := filepath.Glob("[") // 此处模式提供格式错误 if error != nil && error == filepath.ErrBadPattern { fmt.Println(error) return }
不能忽略错误
此前学过 _ 符号可以忽略参数,同样也可以用它忽略错误。在实际工程项目中不建议这样做,所有的错误都应该被及时发现及时处理。
自定义错误
有哪些方法创建自定义错误?
-
使用 errors.New
使用New可以创建自定义错误,如上面的 ErrBadPattern 错误就是使用 New定义的。
-
使用 fmt 的 Errorf
Errorf 能格式化输出错误以提供不止于字符串的错误信息。
和 Printf 用法一样,不过它会返回一个 error 类型。
-
使用结构体类型
和之前的PathError例子一样,我们可以对错误进行结构体包装。
Panic
上面所说的错误其实在java中都是异常,真正的错误是类似虚拟机故障,内存不足,死锁之类,通常这时程序已经无法恢复需要停止,go中把这些称为 panic (恐慌)。不过go中的panic可以使用recover重新获取对程序的控制。
panic用于系统错误,程序员使用时一般只需要 error 即可。
发生 panic
发生 panic 时, 函数会停止运行,但 defer 函数仍会被执行,然后将控制权返回函数调用方,直到当前协程的所有函数都退出。然后控制台会打印 panic 信息,接着打印堆栈跟踪信息,然后程序终止。
看一个例子:
func fullName(firstName *string, lastName *string) {
defer fmt.Println("deferred call in fullName")
if firstName == nil {
panic("runtime error: first name cannot be nil")
}
if lastName == nil { // 产生panic
panic("runtime error: last name cannot be nil")
}
fmt.Printf("%s %s\n", *firstName, *lastName)
fmt.Println("returned normally from fullName")
}
func main() {
defer fmt.Println("deferred call in main")
firstName := "Elon"
fullName(&firstName, nil) // 传入的lastname为nil
fmt.Println("returned normally from main")
}
- 该程序会打印:
deferred call in fullName
deferred call in main
panic: runtime error: last name cannot be nil
goroutine 1 [running]:
main.fullName(0x1042bf90, 0x0)
/tmp/sandbox060731990/main.go:13 +0x280
main.main()
/tmp/sandbox060731990/main.go:22 +0xc0
recover panic
通过在defer函数内部调用 recover,panic可以被恢复,恢复后的panic将继续执行剩下的程序。
依然是上面名字的例子:
func recoverName() {
if r := recover(); r!= nil {
fmt.Println("recovered from ", r) // r 即 panic 的传参
}
}
//
func fullName(firstName *string, lastName *string) {
defer recoverName()
...
}
注意,recover 只能恢复同一个协程发出的 panic。
运行时 panic
类似 java 的运行时异常,比如数组越界访问,这种情况会产生 panic。这种panic同样可以恢复。
恢复后获得堆栈跟踪
panic恢复后即不会打印堆栈跟踪信息,如果仍然想获取这些信息,可以使用 Debug 包中的 PrintStack 函数。通常我们在defer函数中recover后调用。
7. 文件处理
文件操作完记得 close
读文件
读取整个文件
使用 ioutil 包中的 ReadFile 函数。
data, err := ioutil.ReadFile("test.txt")
如果 err 为 nil,则读取成功了,该函数返回的数据是一个字节切片。
import (
"fmt"
"io/ioutil"
)
func main() {
data, err := ioutil.ReadFile("test.txt")
if err != nil {
fmt.Println("File reading error", err)
return
}
fmt.Println("Contents of file:", string(data))
}
上述程序读取test.txt 文件,并打印。test.txt文件应该放在运行go install的目录下,否则将找不到文件报错。因此文件可以放在任意位置,取决于你在哪个地方编译程序。还可以使用下面三种方法解决路径问题。
- 使用绝对路径
- 使用命令行标记来传递文件路径
- 将文件绑定在二进制文件中
分块读取文件
文件很大时可能需要分块读取,bufio 包提供了这样的功能。bufio的NewReader
逐行读取文件
bufio还提供了逐行读取的功能,bufio的NewScanner
写文件
写字符串
f, err := os.Create("test.txt") // 创建文件
l, err := f.WriteString("Hello World") // 写入字符串
写字节
Write方法,可传入字节切片