树的典型应用有很多,比如计算机的文件系统就是一棵树,根目录就是根节点。树的重要应用之一就是搜索树,搜索树通常分为二叉搜索树和多路搜索树。
二叉搜索树
二叉搜索树是一颗有序的树,每个结点不小于其左子树任意结点的值,不大于右子树任意结点的值。二叉搜索树还有一个有趣的特性,它的中序遍历得到的是有序数列。
二叉搜索树能提高搜索的效率,搜索次数最多是树的深度次,最少能到log(n)。
搜索树有搜索,插入,删除等操作。搜索即搜索整棵树,查找是否有匹配的节点;还有搜索最大值和最小值操作,最大值在树的最右侧,最小值在最左侧,因此都很好实现。
treenode find(tree T,int val){ /*搜索操作*/ if(T==NULL) return NULL; if(T->data > val) return find(T->left,val); else if(T->data < val) return find(T->right,val); else return T; }
插入,也是采用递归实现,插入的结点都放到了叶子节点。
treenode insert(tree T,int val){ if(T==NULL) { T=(treenode)malloc(sizeof(struct node)); T->data=val; T->right=T->left=NULL; } else if(T->data >= val) T->left = insert(T->left,val); else T->right = insert(T->right,val); return T; }
删除,这种操作比较复杂,因为可能会破坏BST的规则,需要进行调整。删除操作分几种情况:
1)当删除的结点是叶子节点,直接删除即可,如删除下图中的7结点;
2)当删除非叶节点,且该节点只有一个子节点时,我们可以删除该节点,并让其父节点连接到它的子节点即可;如删除8结点,直接让5结点连接到7即可;
3)当非叶节点,且有两个子节点时,可以删除该节点,然后抓出左子树中最大的元素(或者右树中最小的元素),来补充被删元素产生的空缺。但抓出的元素可能也不是叶节点,所以它所产生的空缺需要它的子树某个结点补充…… 直到最后用来填充的是一个叶节点。上述过程可以递归实现。如删除2结点,可以用1替换或者用3替换。
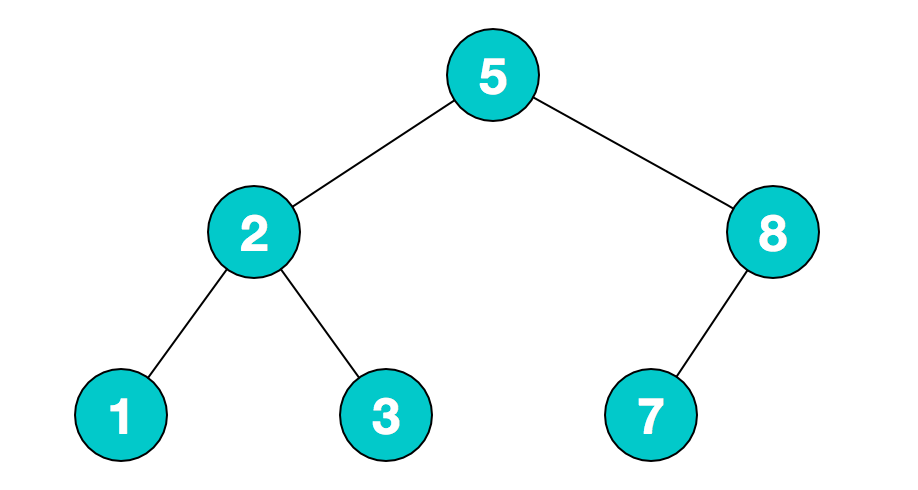
通常删除使用递归实现,如果非递归需要记录父节点,并且被删结点是根节点需要特殊处理,比较麻烦。
AVL树
AVL树是用发明它的人的名字命令的,AVL树的任意节点的左子树深度和右子树深度相差不超过1。
因此AVL树是一个平衡的树,不会偏向一侧,保证了搜索的时间复杂度为O(logn)。AVL树的大部分操作和二叉搜索树相同,只有插入和删除操作大有不同,因为可能会破坏平衡,我们需要恢复平衡。树的平衡需要理解旋转操作。
(网上很多关于AVL插入调整的博客,删除的博客较少,下面借鉴Vamei大神的博客,讲讲插入操作。)
先看看失衡时如何调整为不失衡的例子:
1)一次单旋调整平衡
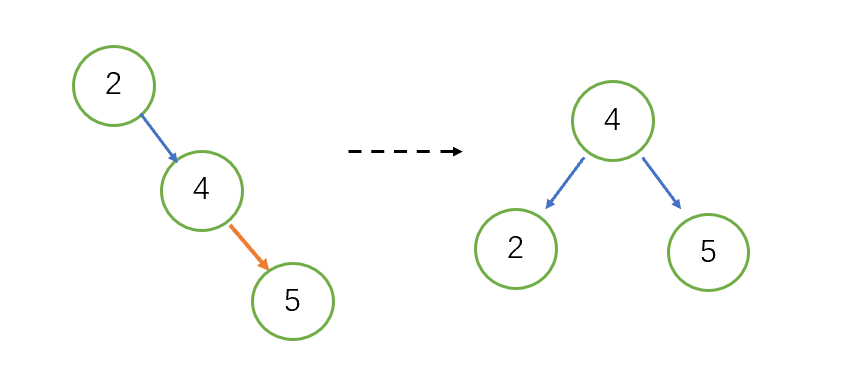
当插入5结点时,2结点失衡,左子树深度0,右子树为2。结点2的右边超重,因此我们进行左旋,旋转中心为结点4,旋转后4为根节点,如图,恢复了AVL性质。这样的旋转称为‘左单旋’。
同样的,如果都是指向左边,那就是左边超重,进行‘右单旋’。
2)两次单旋调整平衡
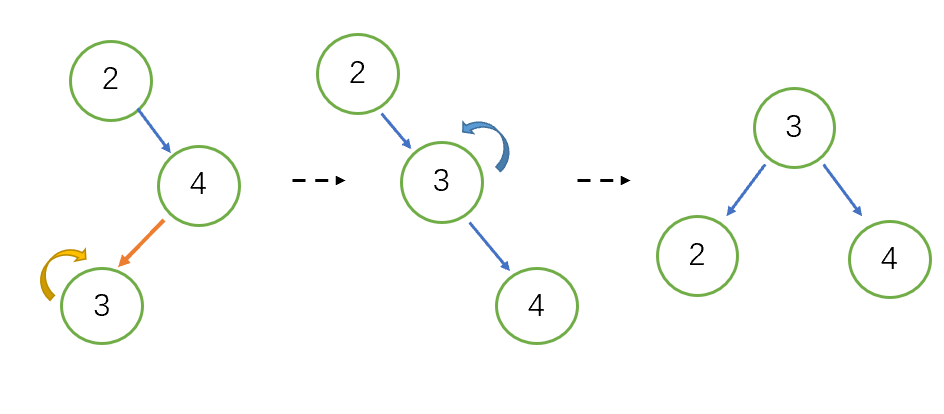
如图如果插入的是结点3,那么旋转中心为结点3,先进行一次右单旋,再以3为中心进行一次左单旋即恢复平衡。这种旋转称为‘右左旋转’,同样还有‘左右旋转’。
对某个结点进行单旋的结果可以一般化为下图:

总结插入的一般流程:
1.按照常规BST的插入,将节点插为叶节点;
2.从插入节点开始回溯,寻找第一个出现失衡的结点;
3.找到失衡结点(暂称为结点A)失衡的一侧,是左右哪一侧导致的失衡;
4.失衡结点的失衡侧的根节点(暂称为结点B),判断B节点的左右子树哪个更深;
5.如果步骤3和4的方向一致,均为左(右),则以B结点进行一次右(左)单旋;如果方向不一致,如步骤3为左侧失衡,步骤4为右侧子树更深,则以结点B的右结点进行两次单旋,先左单旋,再右单旋。
#练习几个实例:

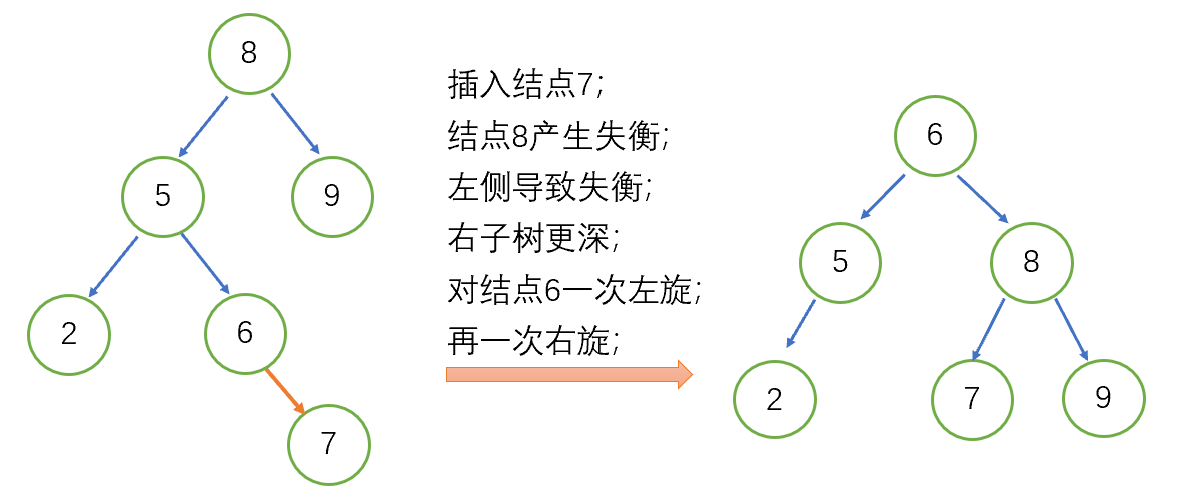
具体代码要实现回溯和恢复AVL,因此节点结构需要额外记录父节点和结点深度。代码就不细看了,简单看看Vamei写的恢复AVL树的函数代码:
/* tr是整个AVL树的根,np是插入节点的位置 */ TREE recover_avl(TREE tr, position np) { int myDiff; while (np != NULL) { update_root_depth(np); myDiff = depth_diff(np); if (myDiff > 1 || myDiff < -1) { if (myDiff > 1) { /* left rotate needed */ if(depth_diff(np->rchild) > 0) { np = left_single_rotate(np); } else { np = left_double_rotate(np); } } if (myDiff < -1) { if(depth_diff(np->lchild) < 0) { np = right_single_rotate(np); } else { np = right_double_rotate(np); } } /* if rotation changes root node */ if (np->parent == NULL) tr = np; break; } np = np->parent;/* backtracking */ } return tr; }
红黑树
红黑树也是一种自平衡的二叉查找树,相比于AVL树,没有严格的深度差要求,但是结点多了颜色的特性。红黑树的时间复杂度为O(logn),红黑树应用广泛,Javad的TreeMap、C++STL的map、linux的CFS调度器都是基于红黑树实现的。
红黑树的特征:
1. 节点是红色或黑色。
2. 根节点是黑色。
3. 所有叶节点都是黑色。(红黑树的叶子节点指的是NULL节点)
4. 每个红色节点的两个子节点都是黑色。(所有路径上不能有两个连续的红色节点)
5. 从任一节点到其每个叶子的所有路径都包含相同数目的黑色节点。
性质4、5保证了红黑树的深度差最大为1倍,也就是保证了树的平衡,不会倒向一侧。
红黑树特点:
· 同AVL树一样,由于有平衡条件限制,插入和删除可能需要调整平衡;
· 红黑树应用广泛,实际很少用AVL树,因为AVL树对平衡要求过于苛刻,节点变动可能需要很多次旋转才能恢复平衡,而红黑树最多只需要3次旋转(插入最多两次,删除最多3次)就能恢复平衡;
· 红黑树查询效率略低于AVL树,但是插入删除效率比AVL树高;
· 红黑树是一种以2叉树表示的平衡2-3-4叉搜索树,只不过3叉和4叉的表示形式被做了限定。
参考:(找了几篇讲得不错的红黑树博客)
哈夫曼树
哈夫曼树是一种节点带权的最优二叉树。最优的意思是该树的带权路径长度最小。
所谓树的带权路径长度,就是树中所有的叶结点的权值乘上其到根结点的路径长度。
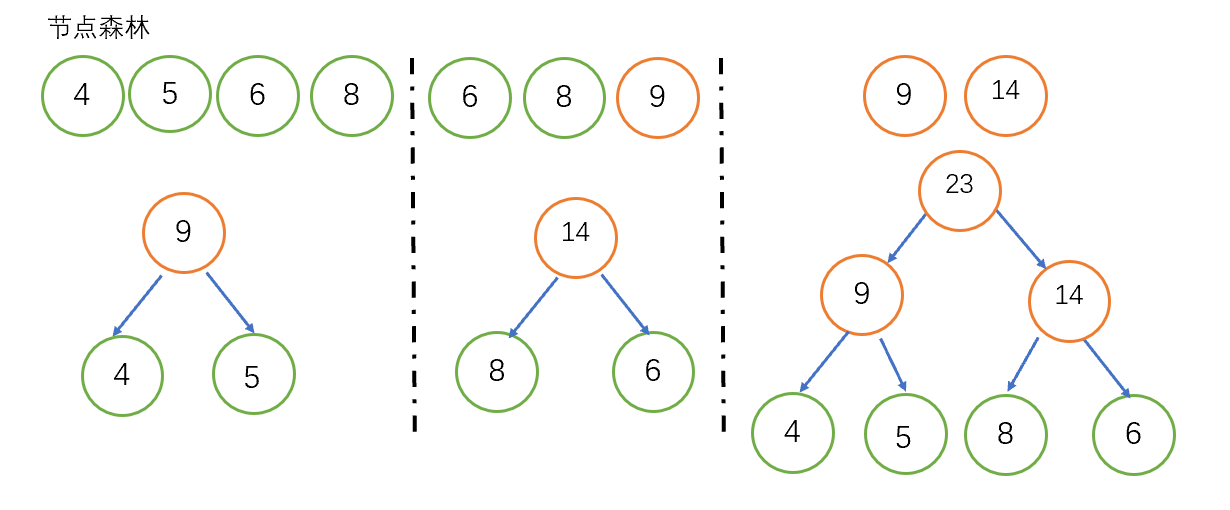
哈夫曼树主要内容是建树,假设已有n个具有权值的结点,构造一个有n个叶节点的哈夫曼树步骤如下:
1.将结点看成n棵树组成的森林;
2.从森林中取出根节点权值最小的两棵树分别作为左右子树,形成新的父节点的权值为子节点权值之和,然后将新树放到森林中;
3.重复步骤2,直到森林中只剩一棵树。
# 哈夫曼编码
哈夫曼树的由来,用于变长编码的。哈夫曼编码典型应用就是用于字符编码,计算机中对字符也是采用01编码,我们最容易想到的是每个字符都采用等长的01串进行编码,但哈夫曼的变长编码缩短了编码长度。哈夫曼的思想是出现频率高的字符用更短的编码表示。对每个字符串设定权值,构造一颗哈夫曼树,左侧的路径编号为0,右倾为1,那么字符的哈夫曼编码就等于从根到各个字符路径上01的组合。
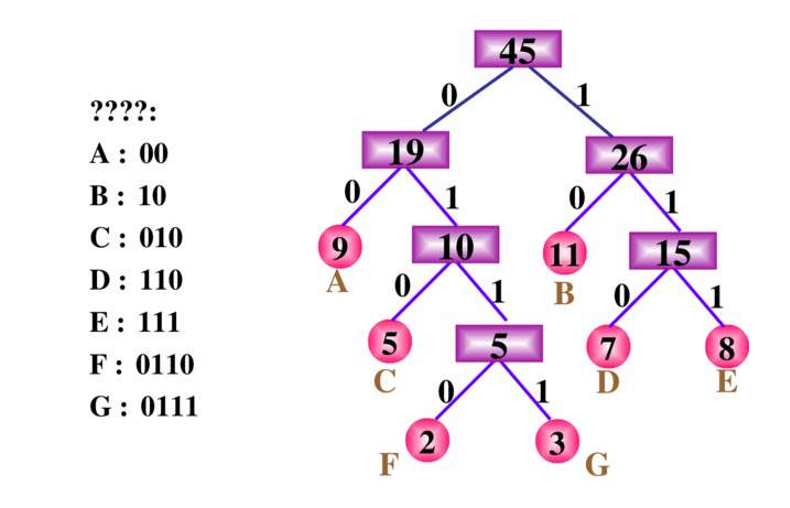
由于哈夫曼树的有效节点都是叶子节点,所以不会产生一个字符的编码等于另一个字符编码前缀的情况。解码方采用同样的哈夫曼树规则即可实现解码。
哈夫曼编码常用于压缩文件。
Treap树堆
Treap = tree + heap,树堆本身是一颗二叉搜索树,每个结点附有不同的优先级,单看优先级形成一个堆,所以树堆其实是树和堆的组合。树堆不需要保证树的深度差,只保证优先级的堆成立。树结点变化时,通过旋转使得保持堆的性质。
Splay伸展树
关于数据查询有个90-10规律,就是90%的查找发生在10%的数据上。那如果经常查找的数据放得离根结点近就会提高效率,伸展树就是基于这样的想法实现的。
伸展树也是一种自平衡的二叉查找树,不过它左右子树的深度差没有规定。只是规定了每次查找完后通过旋转将被查找结点移至根节点,旋转操作可以分为三类,zig,zig-zag,zig-zig操作。伸展树的平均时间复杂度为O(logn).
最坏情况下,伸展树会恶化为一条单链;伸展树空间效率很高,不需要额外的标记信息,如深度,颜色等;总体效率在搜索树中也很高。
B树
B树是一种平衡多路查找树。每个结点可以有多个子节点。
B树是为文件系统和数据库而生的,因为磁盘访问的IO时间相对于计算时间很长,而每次访问一个结点就要进行一次IO,因此树深度越小,IO代价越小。于是B树诞生了,它可以压缩树的深度到很小,以减少IO次数。
数据库索引文件有可能很大,关系型数据存储了上亿条数据,索引文件大则上G,不可能全部放入内存中,而是需要的时候换入内存,方式是磁盘页。一般来说树的一个节点就是一个磁盘页。如果使用二叉查找树,那么每个节点存储一个元素,查找到指定元素,需要进行大量的磁盘IO,效率很低。
而B树解决了这个问题,通过单一节点包含多个data,大大降低了树的高度,大大减少了磁盘IO次数。一个B树的结点通常和一个完整的磁盘页一样大。
常用于文件系统和部分数据库索引。
B+树
和B树很像,不过B+树的数据节点都是叶子节点,内部节点不存储数据。
常用于MySql数据库的索引。
搜索树还有很多,如SBT结点平衡搜索树、替罪羊树、区间树、线段树……
随着技术发展,不断有更多的搜索树被发明出来,还要一直学习呀!