mysql中查询的关键字是SELECT,其完整语法为:(下面会分别介绍每个段的用法,可以先看后面的再回过头看前面)
SELECT DISTINCT <select_list> FROM <left_table> <join_type> JOIN <right_table> ON <join_condition> WHERE <where_condition> GROUP BY <group_by_list> HAVING <having_condition> ORDER BY <order_by_condition> LIMIT <limit_number>
要提一下的是,为了高效操作,一条语句中每步的操作都会产生一个虚表,下一步即对这个虚表进行操作,虚表会在内部自动生成和删除。
查询语句很多时候绕的晕,其实是你不熟悉每条语句的执行顺序。在引擎内部的语句执行的顺序和语法写的顺序是不一样的,下面看看select机器内部的执行顺序:
1. FROM <left_table> #先对表进行笛卡尔乘积,得到虚表T1 2. ON <join_codition> #对T1进行条件筛选,得到T2 3. <join_type> JOIN <right_table> #根据连接类型,对T2进行信息补充,比如left join,左边表未匹配到的部分会适当添加NULL后加入到T2中,形成T3 4. WHERE <where_condition> #对T3进行筛选,得到T4 5. GROUP BY <group_by_list> #根据要分组的列,对T4进行分组,得到T5 6. HAVING <HAVING_condition> #对T5进行筛选,得到T6 7. SELECT #这时才选择列,选择T6中指定的列,得到T7 8. DISTINCT <select_list> #对T7除重 得到T8 9. ORDER BY <order_by_condition> #对T8 进行排序 得到T9 10. LIMIT <limit_number> #对T9进行截取,得到最终结果
基本查询
查询表中的某列,多个列名可以用逗号分隔,所有列可以用 * 代替,语法:
SELECT list_name1,list_name2 … FROM table_name;
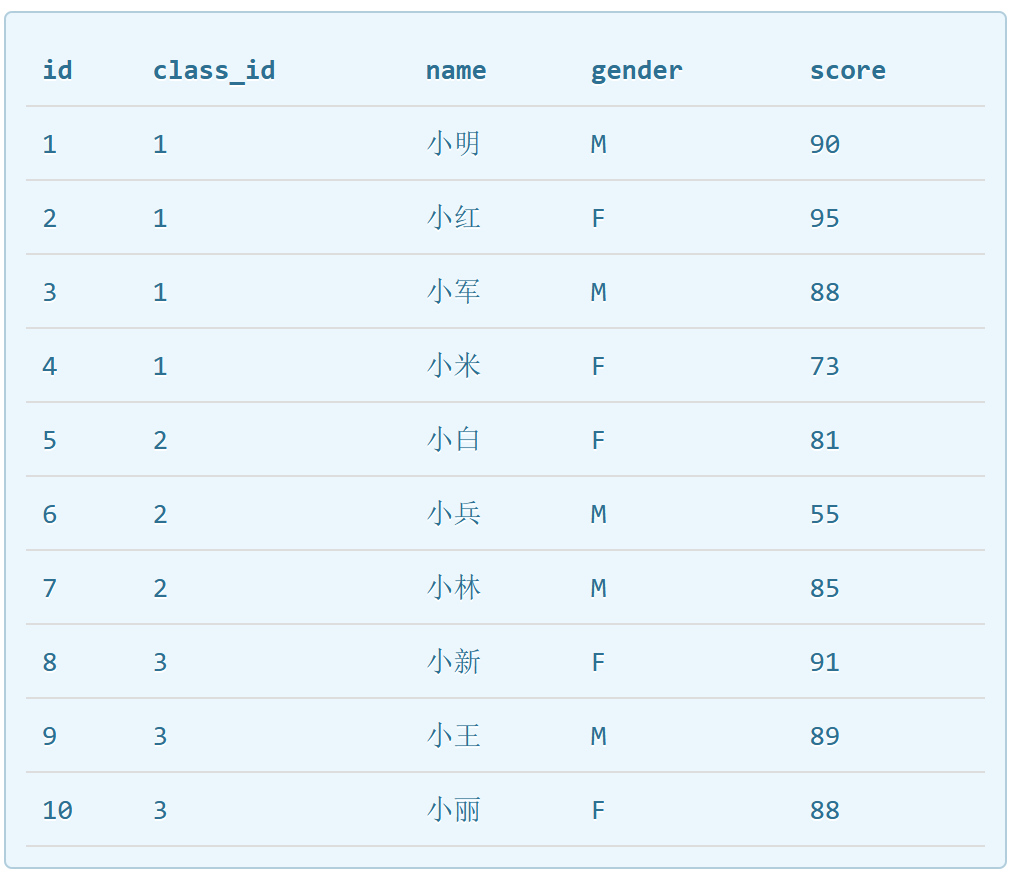
eg:SELECT * FROM students; #查看学生表
选择性查询
选择性的查询记录,通过where子句,进行字段的精确筛选。语法如下:
SELECT * FROM table_name WHERE <条件表达式>;
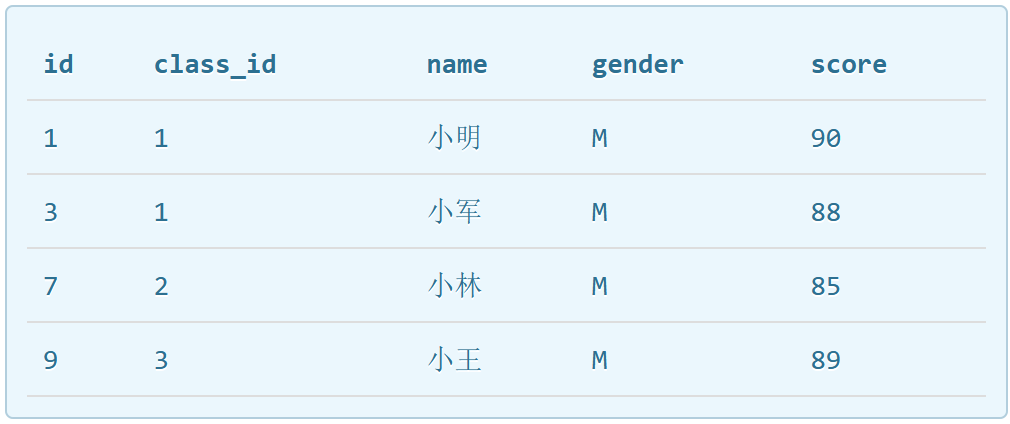
eg: SELECT * FROM students WHERE score >= 80 AND gender = 'M';
除了可以用<>=等运算符进行筛选,还可以使用BETWEEN,如where score BETWEEN 0 AND 60;筛选不及格记录。
用于where条件组合的四个操作符:AND、OR、IN、NOT。
IN用来指定条件范围,符合的条件都在括号内用逗号隔开,如where score IN(100,60);可以筛选满分和刚好及格的记录。IN比OR快。NOT用于否定条件,如前面语句改为NOT IN,筛选的就是及格的记录。
筛选过滤还可以采用通配符,关于LIKE、正则表达式见 MySQL 其他常用语法。
子查询
查询可以嵌套,即可以查询另一个查询的结果。
SELECT * FROM ( SELECT * FROM students WHERE scour<60 ) WHERE gender='M';
上面的语句当然可以用1条select完成,这里只是展示其用法。当业务需求复杂时,如从多个表获取信息时,子查询是十分灵活的选择。
聚合查询
使用聚合函数进行对数据汇总的查询。聚合函数有5个,COUNT、SUM、AVG、MAX、MIN。
比如统计一张表符合筛选条件的记录数,用COUNT()函数。格式为COUNT([DISTINCT|ALL] <列名>),DISTINCT表示不统计重复项,默认为ALL统计重复项。
SELECT COUNT(*) num FROM students; 统计表中记录条数,返回一个2*1的二维表,字段名为num SELECT COUNT(id) boys FROM students WHERE gender = 'M'; where执行在select之前,因此count统计的是筛选后的数据,结果如下

·count():count(list)统计list不为null的记录数;count(*)统计所有的记录数,null也会被统计,因为主键不会为null,相当于统计主键个数。
·avg()、sum()、max()、min():需要指定列名,也会忽略null。
分组查询
用GROUP BY对查询结果按字段列表进行分组,字段值相等的记录分为一组;语法如下:
[GROUP BY 字段列表] [HAVING <条件表达式>],HAVING用于过滤组,仅输出满足条件的组。
使用分组需要注意:
· NULL也会作为一个分组返回。
· GROUP BY中列出的每个列只能是检索列或有效表达式,不能是聚集函数。
· 除了聚集函数外,SELECT中列出的每个列也都必须在GROUP BY中列出。
比如现在想知道每个班的人数,可以这样做:
SELECT COUNT(*) num FROM students GROUP BY class_id; 按班级分组,count是对每组进行计数
SELECT class_id, COUNT(*) num FROM students GROUP BY class_id; 可以把class_id列也放入结果集
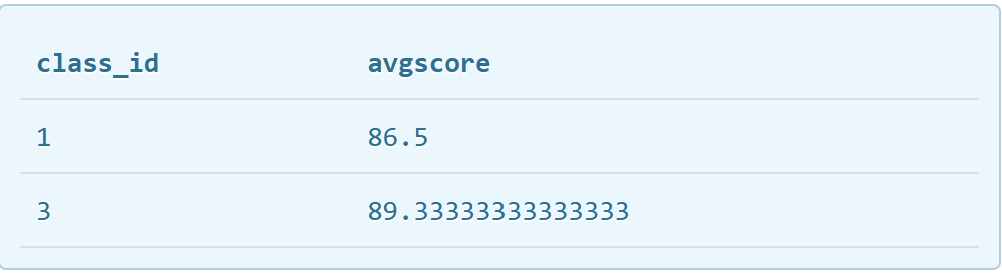
查出每个班级的平均分,并只看平均分高于80的班级,语句如下,结果如图: SELECT class_id, AVG(score) avgscore FROM students GROUP BY class_id HAVING AVG(score)>80;
having和where不同,where是过滤记录,having是过滤组,where在分组前就过滤完,having在分组后过滤。
多表查询
mysql还可以同时查询多个表,得到的结果整合到一张表里,即students表的每一行与classes表的每一行都两两拼在一起返回。结果集的列数是students表和classes表的列数之和,行数是students表和classes表的行数之积。这种查询叫笛卡尔查询,又称交叉查询。
SELECT * FROM students, classes;
一般这样查询的结果,很多记录是没有意义的。如上语句,如果没有筛选,那么会出现小明既在一班又在其他班的记录,这明显是错误的。多表查询,表之间肯定是有某种联系联合起来才有意义,因此多表查询一般必须添加联结条件。上例中,学生表和班级表的联系就是class_id,正确的写法:
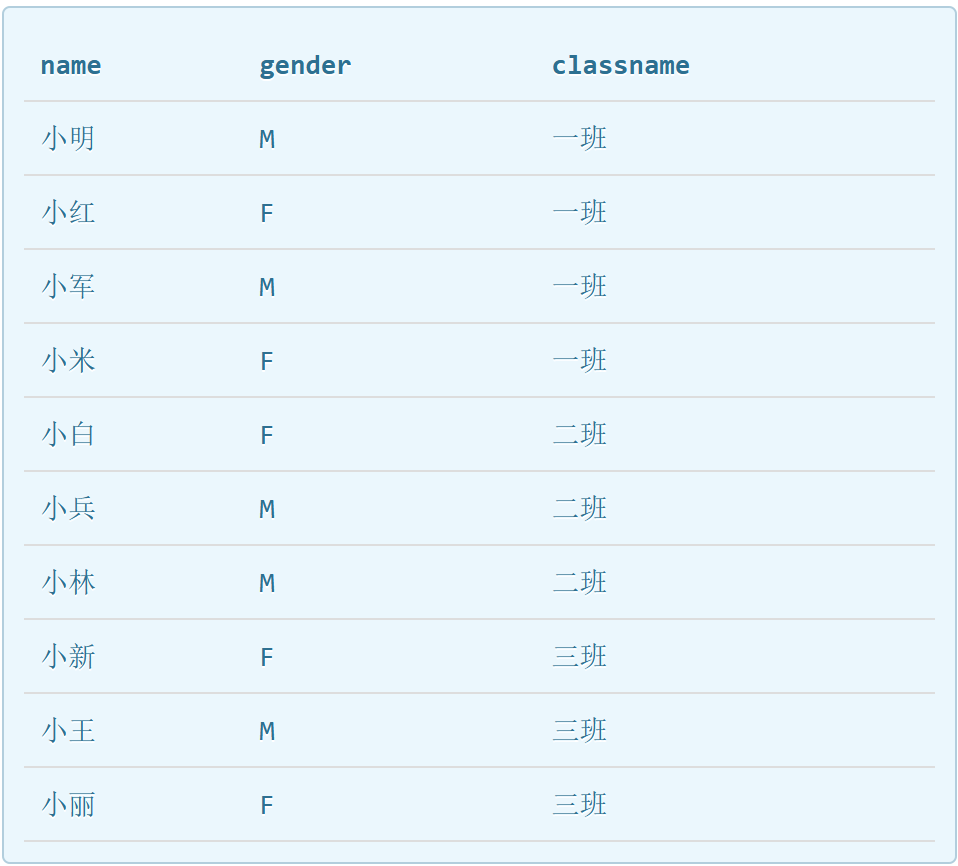
SELECT s.name name,gender,c.name classname from students s,classes c where s.class_id=c.id;
连接查询
很多时候多张表之间是有联系的,它们可能有相同的列,因此可以联结多个表进行查询。连接查询也是多表查询,通常使用多表查询时优先用连接查询,而不是上面介绍的多表查询。
语法:SELECT <列> FROM <表1> JOIN <表2> ON <条件...>;
连接的规则有两种:
· 内连接INNER JOIN:join前加inner关键字,不加的话,默认join也为内连接。返回笛卡尔积中符合连接条件的数据行,和上述的多表查询是一样的,不过SQL推荐使用联结写法,这样能避免忘记填写筛选条件。
· 外连接:又分三种;
· 左连接LEFT OUTER JOIN:通过ON条件筛选后,将左表中其余未在结果中展示的记录也添加进来,空的字段补NULL。
· 右连接RIGHT OUTER JOIN:类似左连接,补齐右表中的所有记录。
· 全连接FULL OUTER JOIN:左表和右表的所有行数据都补齐,空的地方填NULL。
其中INNER和OUTER关键字可以省略,但使用全连接时不能省略。
值得注意的是,如果没有ON筛选,那么结果就是笛卡尔积。
内连接和上述多表连接产生相同效果,下面举例理解一下外连接,假如新学期开学了,二班的同学都毕业了,学校撤销了二班,并且新增了一个五班,有两名同学在五班念书,学校的管理混乱,只更新了students表。此时students表如下:
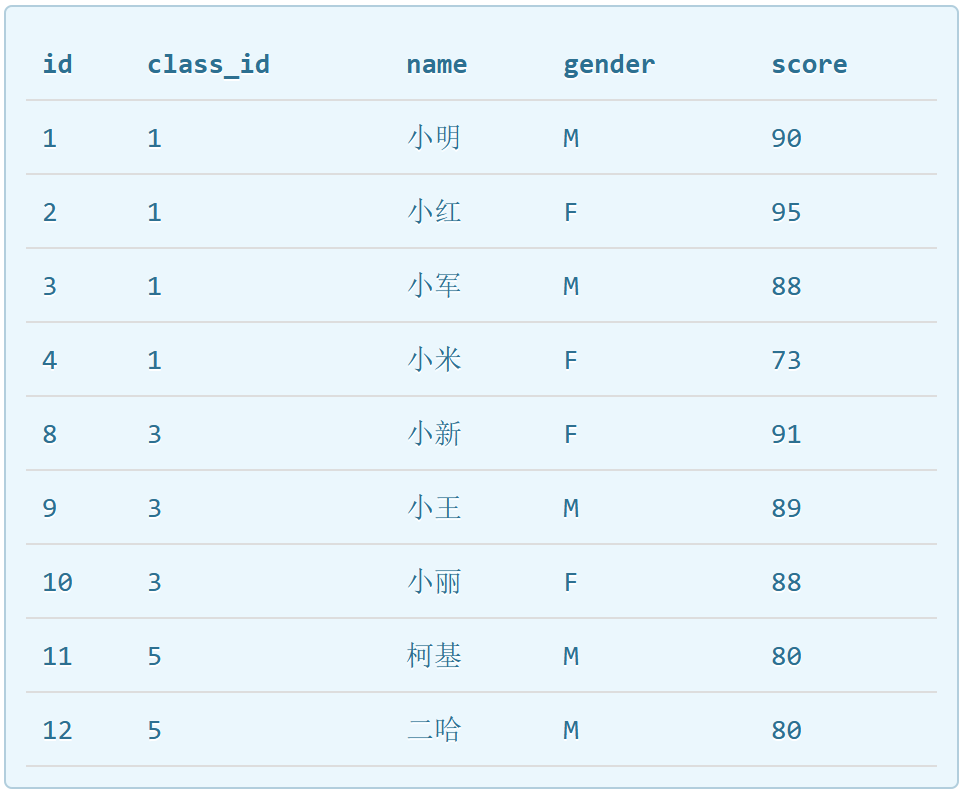
classes表如下:
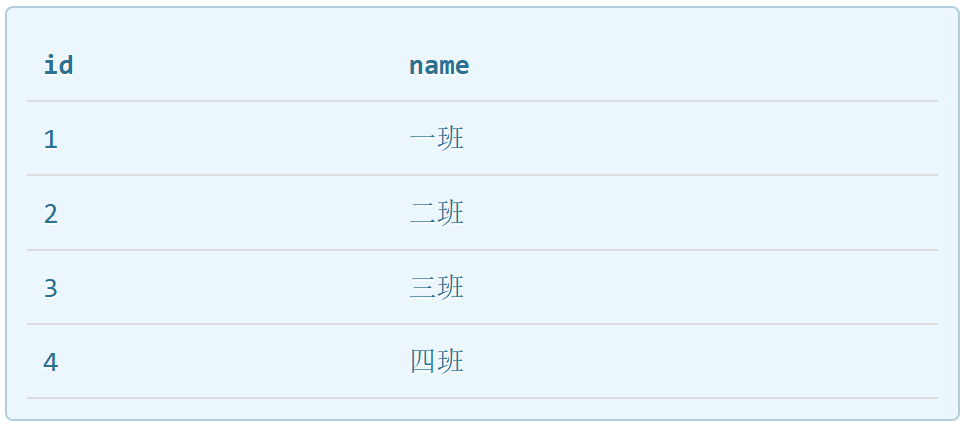
此时我们如果想将班级信息和学生信息统计在一张表,如果使用内连接,筛选条件为students.class_id=classes.id,那么新入学的柯基和二哈就不会显示。此时如果使用外连接,可以选择补齐哪个表的未匹配记录。
左连接
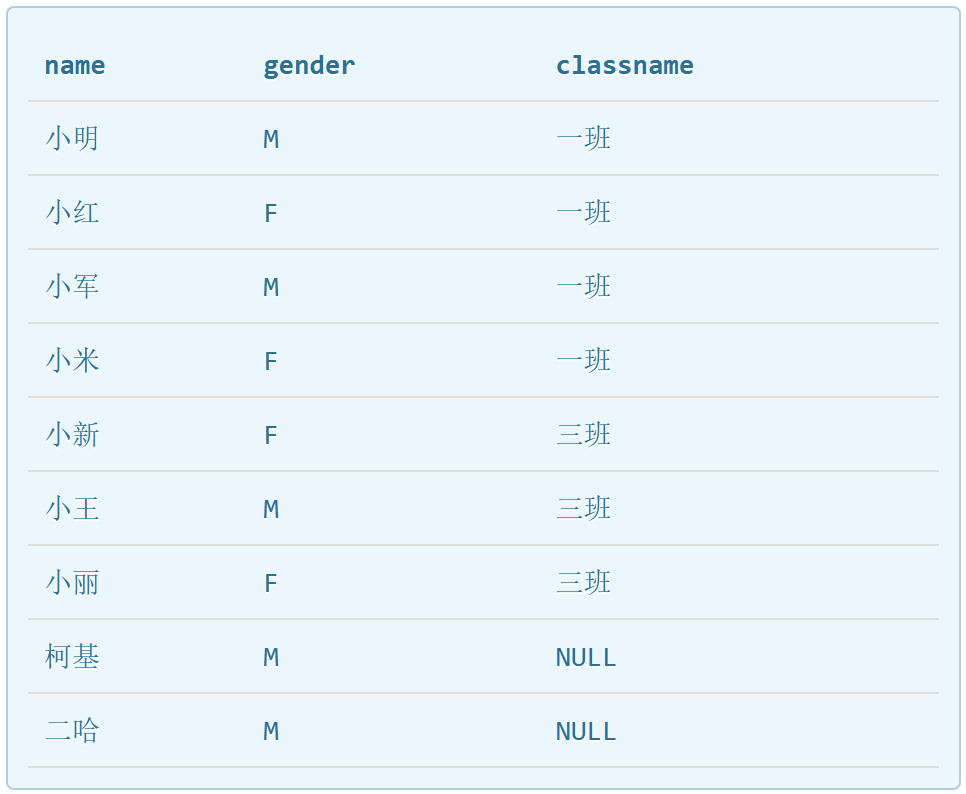
SELECT students.name,gender,classes.name FROM students LEFT JOIN classes ON students.class_id=classes.id;
#一个表不允许重复的列名,因此将class的name重命名为classname;
#由下图可以看到,前7条记录是由ON筛选出来的,后两条是因为left join额外补齐的。
那么右连接和全连接的结果就很容易能想到了。
组合查询
组合查询通过UNION将多个SELECT查询结果组合到一张表中返回。
语法:SELECT … FROM … UNION SELECT … FROM … ORDER BY … LIMIT … ;
值得注意的是:
· 组合的两个select表需要有相同的列,聚合函数和表达式,不过它们的列可以顺序不同;
· 列的类型必须兼容,不必完全相同,但必须是可以隐式转换的类型。例如TINYINT和INT;
· 默认组合会去除重复的记录,即两个表中都有的记录。可以通过在UNION后加ALL关键词显示重复记录;
· ORDER是对组合后的结果进行排序,只允许有一个ORDER,且必须在最后。
排序
查询的结果集通常是按照表中实际存放顺序排序的,但可以自定义条件排序。通过ORDER BY命令可以指定通过什么字段排序,比如通过score排序:
SELECT * FROM students ORDER BY score;
默认是按照升序排序,也可以指定为降序ORDER BY score DESC;
可以对多列进行排序,即第一个排序条件相同时,比较后面的排序条件;
如果有WHERE子句,ORDER子句要放到其后面,逻辑上就是在筛选出的记录中排序。
分页
数据太多可以分页查看,M表示最多显示M条记录,N表示偏移量。LIMIT永远在语句最后,其语法是:
LIMIT <M> OFFSET <N>;
eg:SELECT * FROM students LIMIT 3 OFFSET 6; 表示显示3条记录,偏移6条记录,从第7条记录开始
还可以省略offset写成:LIMIT m,n; 表示偏移m条显示n条
参考:廖雪峰的SQL教程 、《MySQL必知必会》