准备
启动一个centos容器
docker run -i -t --name hadoop centos /bin/bash
下载好需要的包
[root@CyzLearnCloud sparklearn]# wget --no-check-certificate --no-cookies --header "Cookie: oraclelicense=accept-securebackup-cookie" https://www.apache.org/dyn/closer.cgi/hadoop/common/hadoop-3.2.1/hadoop-3.2.1.tar.gz
[root@CyzLearnCloud sparklearn]# wget http://distfiles.macports.org/scala2.12/scala-2.12.12.tgz
[root@CyzLearnCloud sparklearn]# wget https://mirror.bit.edu.cn/apache/hadoop/common/hadoop-3.2.1/hadoop-3.2.1.tar.gz
[root@CyzLearnCloud sparklearn]# wget https://mirror.bit.edu.cn/apache/spark/spark-3.0.1/spark-3.0.1-bin-hadoop3.2.tgz
解压 上传

[root@CyzLearnCloud sparklearn]# docker cp hadoop-3.2.1 e9d7c:/opt
[root@CyzLearnCloud sparklearn]# docker cp jdk1.8.0_131 e9d7c:/opt
[root@CyzLearnCloud sparklearn]# docker cp scala-2.12.12 e9d7c:/opt
[root@CyzLearnCloud sparklearn]# docker cp spark-3.0.1-bin-hadoop3.2 e9d7c:/opt
配置jdk
设置java 环境变量,配置profile
vi /etc/profile
在文件末尾加上
JAVA_HOME=/opt/jdk1.8.0_131/
JAVA_BIN=/opt/jdk1.8.0_131/bin
JRE_HOME=/opt/jdk1.8.0_131/jre
CLASSPATH=/opt/jdk1.8.0_131/jre/lib:/opt/jdk1.8.0_131/lib:/opt/jdk1.8.0_131/jre/lib/charsets.jar
export JAVA_HOME JAVA_BIN JRE_HOME PATH CLASSPATH
使得配置立马有效
source /etc/profile
配置 bashrc
vi ~/.bashrc
在文件末尾加上
export JAVA_HOME=/opt/jdk1.8.0_131
export PATH=$JAVA_HOME/bin:$PATH
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
使得配置立马有效
source ~/.bashrc
查看成功: java -version
配置scala
配置环境变量
vim /etc/profile
export SCALA_HOME=/opt/scala-2.12.12
export PATH=$PATH:$SCALA_HOME/bin
环境变量生效
source /etc/profile
查看scala版本
scala -version
配置Hadoop
在hadoop目录下
vi etc/hadoop/hadoop-env.sh
在文件末尾添加jdk目录(这里=后面添加的是你的jdk目录)
export JAVA_HOME=/opt/jdk1.8.0_131
检查安装的hadoop是否可用 ./bin/hadoop version (注意要在hadoop的安装目录下执行)

- 配置hadoop环境变量
前面在验证hadoop命令的时候需要在hadoop的安装目录下执行./bin/hadoop,为了方便在任意地方执行hadoop命令,配置hadoop的全局环境变量,与java一样,修改~/.bashrc文件
执行vi ~/.bashrc
添加内容
export HADOOP_HOME=/usr/local/hadoop
export PATH=$PATH:${JAVA_HOME}/bin:${HADOOP_HOME}/bin:${HADOOP_HOME}/sbin

source ~/.bashrc 使环境变量生效
hadoop version 验证变量生效

安装ssh
yum install openssh-clients
yum install openssh-server
验证ssh安装
/usr/sbin/sshd
ssh localhost
可能会出现
Unable to load host key: /etc/ssh/ssh_host_rsa_key
Unable to load host key: /etc/ssh/ssh_host_ecdsa_key
Unable to load host key: /etc/ssh/ssh_host_ed25519_key
的错误,运行以下即可
#RUN ssh-keygen -t dsa -f /etc/ssh/ssh_host_dsa_key
#RUN ssh-keygen -t rsa -f /etc/ssh/ssh_host_rsa_key
#RUN ssh-keygen -t ecdsa -f /etc/ssh/ssh_host_ecdsa_key -N ""
#RUN ssh-keygen -t dsa -f /etc/ssh/ssh_host_ed25519_key
commit
docker commit -m "centos7 with hadoop and ssh" e9d7 centos7-hadoop-sshtest

编写Dockerfile
这一步的主要目的是,让容器启动的时候自动运行ssh
mkdir centos7-hadoop-ssh
cd centos7-hadoop-ssh
vi Dockerfile
加入以下内容
# 选择一个已有的os镜像作为基础r
FROM centos7-hadoop-sshtest
# 镜像的作者
MAINTAINER cyz
# 启动sshd服务并且暴露22端口
RUN mkdir /var/run/sshd
EXPOSE 22
CMD ["/usr/sbin/sshd", "-D"]
~
构建镜像
docker build -t centos7-hadoop-ssh .

插曲
docker容器无法ping?因为没有DNS
以下配置
我们可以在宿主机的 /etc/docker/daemon.json 文件中增加以下内容来设置全部容器的 DNS:
{
"dns" : [
"114.114.114.114",
"8.8.8.8"
]
}
设置后,启动容器的 DNS 会自动配置为 114.114.114.114 和 8.8.8.8。
配置完,需要重启 docker 才能生效。
/etc/init.d/docker restart
然后启动容器 ping www.badiu.com就正常了
搭建hadoop分布式集群
集群规划
准备搭建一个具有三个节点的集群,一主两从
主节点:hadoop0 ip:192.168.2.10
从节点1:hadoop1 ip:192.168.2.11
从节点2:hadoop2 ip:192.168.2.12
启动容器
docker run --name hadoop0 --hostname hadoop0 --net hadoop --ip 192.168.2.10 -dit --privileged=true -P -p 50070:50070 -p 8088:8088 -p 9870:9870 centos7-hadoop-ssh
docker run --name hadoop1 --hostname hadoop1 --net hadoop --ip 192.168.2.11 -dit -P --privileged=true centos7-hadoop-ssh
docker run --name hadoop2 --hostname hadoop2 --net hadoop --ip 192.168.2.12 -dit -P --privileged=true centos7-hadoop-ssh
注意!后面不要跟/bin/bash,不然Dockerfile文件中的CMD会被覆盖,导致ssh没有启动

网上的教程使用的50070,我查了一下资料,50070是hadoop2的webUI端口,hadoop3的webUI端口是9870,我做到最后才发现的,在启动的时候使用的是老命令
docker run --name hadoop0 --hostname hadoop0 --net hadoop --ip 192.168.2.10 -dit --privileged=true -P -p 50070:50070 -p 8088:8088 centos7-hadoop-ssh但是正确的应该是正文写的
固定IP
在宿主机上下载pipework
git clone https://github.com/jpetazzo/pipework.git
cp -rp pipework/pipework /usr/local/bin/
安装bridge-utils
yum -y install bridge-utils
创建网络
brctl addbr br0
ip link set dev br0 up
ip addr add 192.168.2.1/24 dev br0
给容器设置固定ip
pipework br0 hadoop0 192.168.2.10/24
pipework br0 hadoop1 192.168.2.11/24
pipework br0 hadoop2 192.168.2.12/24
三台docker主机互ping一下,没问题
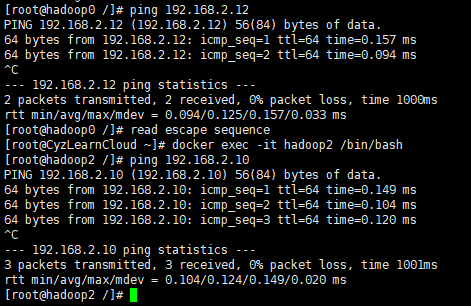
但是这时候我两个容器之间ping成功了,ssh却提示no route to host
尝试用docker network解决
docker network create --subnet=192.168.2.0/24 hadoop
配置hadoop集群
我们的目的只是为了搭建HDFS
对三台容器都进行设置
- 设置主机名与ip的映射,修改
vi /etc/hosts
添加下面配置
192.168.2.10 hadoop0
192.168.2.11 hadoop1
192.168.2.12 hadoop2
- 设置ssh免密码登录
cd ~
mkdir .ssh
cd .ssh
ssh-keygen -t rsa(一直按回车即可)
ssh-copy-id -i localhost
ssh-copy-id -i hadoop0
ssh-copy-id -i hadoop1
ssh-copy-id -i hadoop2
hadoop0上配置hadoop
进入到/opt/hadoop-3.2.1/etc/hadoop
HDFS的配置文件:大多数默认是XML和TXT格式存在。配置文件默认存放在/etc/hadoop目录下。
HDFS中6个重要的配置文件:
- core-site.xml:Hadoop全局的配置文件,也包含一些HDFS的宏观配置。
- dfs-site.xml:HDFS配置文件。
- yarn-site.xml:YARN配置文件。
- mapred-sie.xml:MapReduce配置文件。
- slaves:从节点列表。
- hadoop-env.sh:与运行脚本的环境变量相关的配置文件。
-
core-site.xml
<configuration> <property><!--指定namenode的地址--> <name>fs.defaultFS</name> <value>hdfs://hadoop0:9000</value> </property> <property><!--用来指定使用hadoop时产生文件的存放目录--> <name>hadoop.tmp.dir</name> <value>/opt/hadoop-3.2.1/tmp</value> </property> <property> <name>fs.trash.interval</name> <value>1440</value> </property> </configuration> -
hdfs-site.xml
dfs-site.xml:HDFS的重要配置文件,其Namenode节点和Datanode节点相关的配置项不同。
Namenode主要有3个配置项:dfs.namenode.name.dir、dfs.blocksize、dfs.replication。
Datanode主要有1个配置项:dfs.datanode.data.dir。
<configuration> <property> <name>dfs.http.address</name> <value>hadoop0:9870</value> </property> <property> <name>dfs.namenode.name.dir</name> <value>/opt/dfs/name</value> <description>namenode的目录位置,对应的目录需要存在value里面的路径</description> </property> <property> <name>dfs.datanode.data.dir</name> <value>/opt/dfs/data</value> <!--datanode的目录位置,对应的目录需要存在value里面的路径,可以是一个或多个用逗号分隔的本地路径--> </property> <property> <name>dfs.replication</name> <value>1/value> <!--s系统的副本数量--> </property> </configuration> -
yarn-site.xml
<configuration> <property> <description>The hostname of the RM.</description> <name>yarn.resourcemanager.hostname</name> <value>hadoop0</value> </property> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <property> <name>yarn.log-aggregation-enable</name> <value>true</value> </property> </configuration> -
mapred-site.xml
<configuration> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> </configuration> -
对于start-dfs.sh和stop-dfs.sh文件,添加下列参数:
#!/usr/bin/env bash HDFS_DATANODE_USER=root HADOOP_SECURE_DN_USER=hdfs HDFS_NAMENODE_USER=root HDFS_SECONDARYNAMENODE_USER=root对于start-yarn.sh和stop-yarn.sh文件,添加下列参数:
#!/usr/bin/env bash YARN_RESOURCEMANAGER_USER=root HADOOP_SECURE_DN_USER=yarn YARN_NODEMANAGER_USER=root重新开始start...就可以了。
-
修改hadoop0中hadoop的一个配置文件etc/hadoop/slaves
删除原来的所有内容,修改为如下
hadoop1
hadoop2
- 在hadoop0中执行命令
scp -rq /opt/hadoop-3.2.1 hadoop1:/opt
scp -rq /opt/hadoop-3.2.1 hadoop2:/opt
- 格式化
进入到/usr/local/hadoop目录下
bin/hdfs namenode -format
注意:在执行的时候会报错,是因为缺少which命令,安装即可
执行下面命令安装
yum install -y which
启动成功
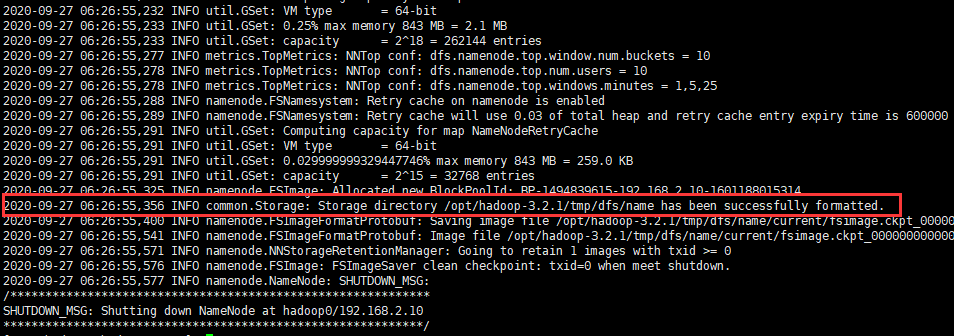
启动HDFS
在所有 NameNode 上启动:
$HADOOP_HOME/bin/hdfs --daemon start namenode
在所有 DataNode 上启动:
$HADOOP_HOME/bin/hdfs --daemon start datanode
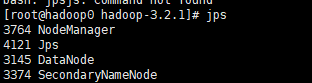
jps命令查看如下
NameNode(hadoop0):

DataNode(hadoop1/2):

验证
VNC连接到宿主机,登录到http://192.168.2.10:9870/,查看成功
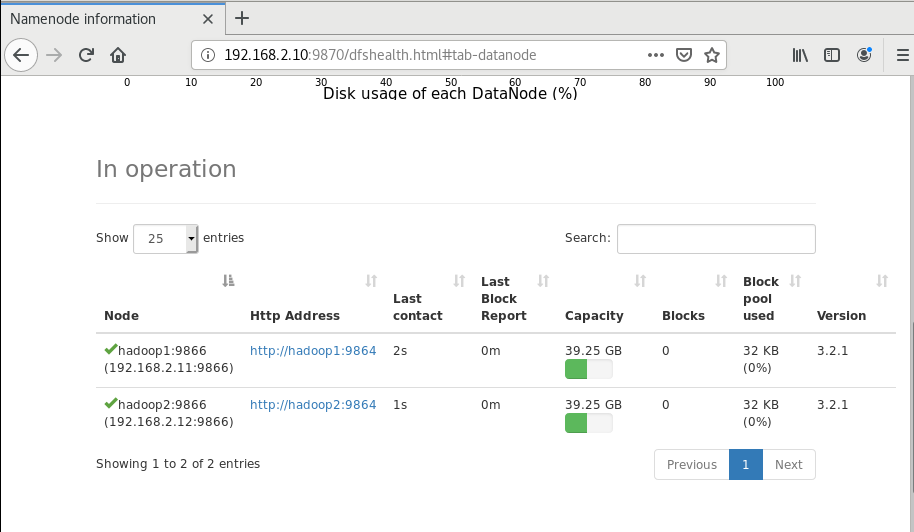
使用验证
创建目录
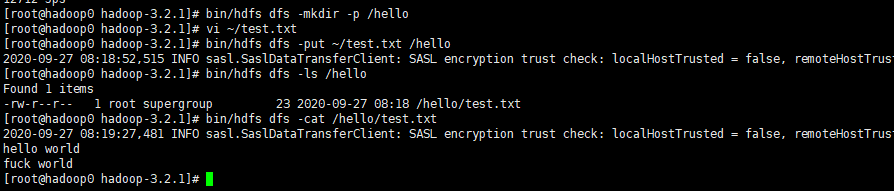
$ ./bin/hdfs dfs -mkdir -p /hello
上传文件到HDFS
首先先新建一个本地文件,
$ vim ~/test.txt
hello world
fuck world
然后使用下面命令进行上传,
$ ./bin/hdfs dfs -put ~/test.txt /hello
查看目录和文件内容
$ ./bin/hdfs dfs -ls /hello
/hello/test.txt
$ ./bin/hdfs dfs -cat /hello/test.txt
hello world
fuck world
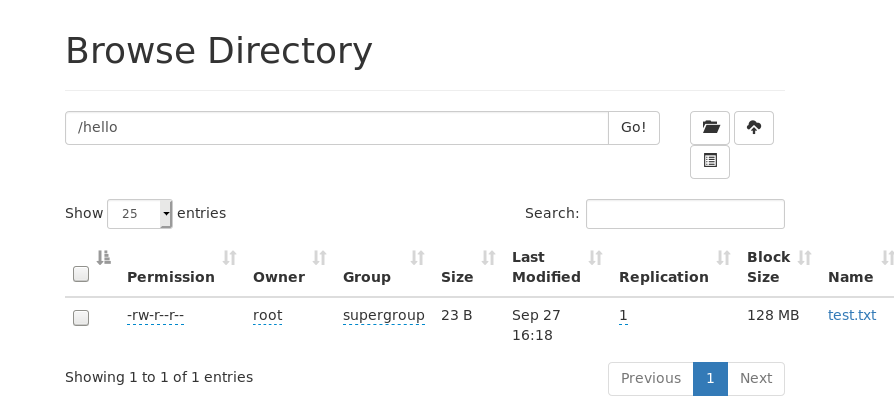
当然,在webUI中也可以看到
启动Spark
先启动好HDFS(如上)
master节点
在master节点(192.168.2.10)上,直接进入到spark目录下,运行./sbin/start-master.sh

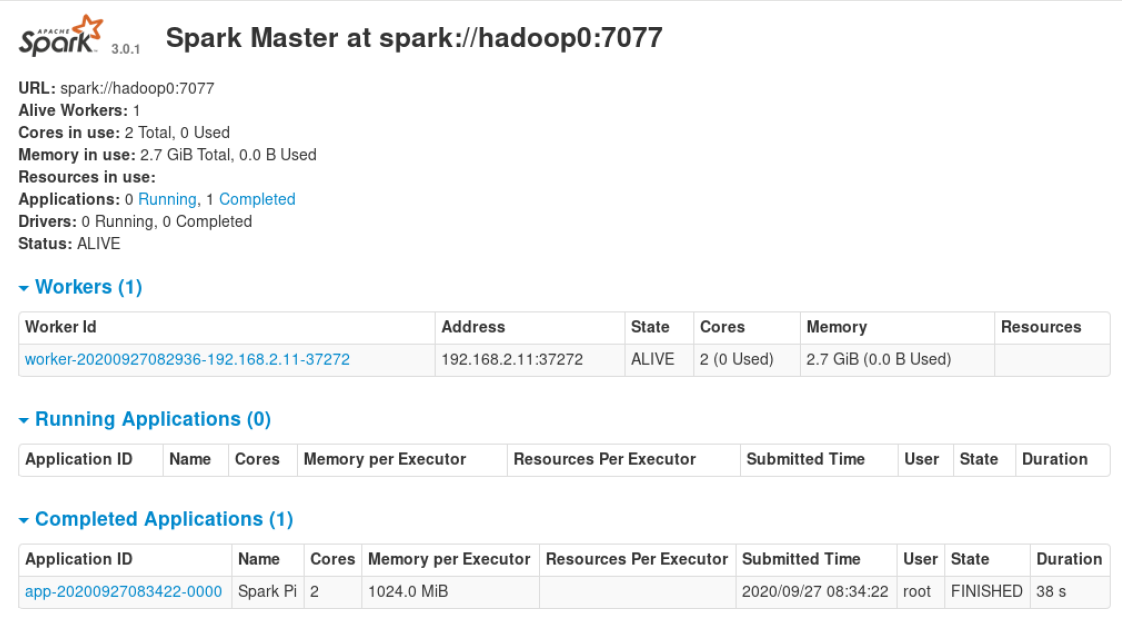
启动成功后通过8080端口进行查看
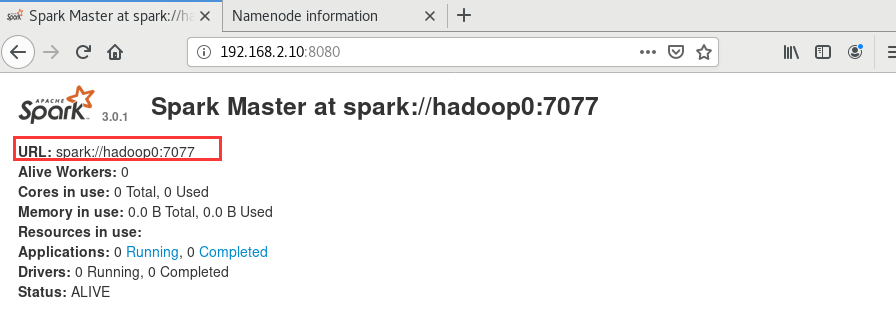
记住这个URL
worker节点
在 worker 上启动 worker 并连接(注册)到 master 上:
./sbin/start-slave.sh <url>成功启动 worker 后,在 master 上刷新 localhost:8080 页面,可以看到添加的 worker 信息。
以hadoop2为例,进入到spark目录下,sbin/start-slave.sh spark://hadoop0:7077
这边就有了
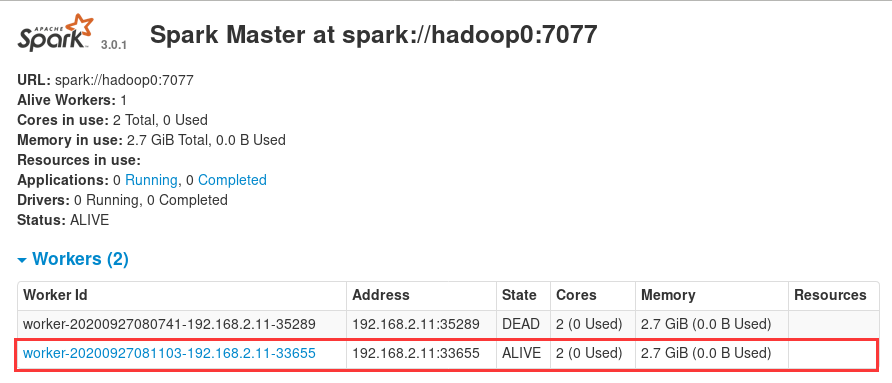
验证
在worker节点(hadoop1)上跑一个spark给的demo程序
./bin/spark-submit --class org.apache.spark.examples.SparkPi --master spark://hadoop0:7077 examples/jars/spark-examples_2.12-3.0.1.jar 100
参考
https://www.cnblogs.com/shiyiwen/p/5076561.html
https://blog.csdn.net/shenzhen_zsw/article/details/73927848
https://blog.csdn.net/chongchen1581/article/details/100862753
https://blog.51cto.com/13670314/2341236
https://www.cnblogs.com/Jing-Wang/p/10672609.html
https://blog.csdn.net/xu470438000/article/details/50512442