首先是爬取了我们学校贴吧的贴吧数据,每个帖子都有是否是精品贴的标签。
根据帖子标题信息,实现了贴吧精品贴和普通贴的分类。错误率在10%左右。
切词用的是jieba吧,没有过滤点停用词和标点符号,因为标点符号其实也是可以算是区分帖子是否是精品贴的而一个重要特征;其实还可以增加几个特征,比如第一页是否含有音频、视频、图片的数量等等,有些重要的特征维度甚至可以多覆盖几个维度。分类的效果可能会更好。但是目前光看标题正确率已经达到了90%,说明朴素贝叶斯还真不错。
训练算法部分用的是朴素贝叶斯方法。测试部分,还是用的留出法。
先是爬虫部分代码:
1 __author__ = 'Oscar_Yang' 2 # -*- coding= utf-8 -*- 3 """ 4 本次目的 5 1、抓取列表页,标题 6 2、计算提拔关键词 7 """ 8 # 导入相关模块。 9 import re, requests, json, random, time, jieba,pymongo 10 import urllib.request 11 from bs4 import BeautifulSoup 12 """连接mongodb""" 13 client = pymongo.MongoClient("localhost",27017) 14 db_tieba = client["db_tieba"] 15 # sheet_tieba_ysu_good = db_tieba_ysu_good["sheet_tieba_ysu_good"] 16 # sheet_tieba_dq = db_tieba_dq["sheet_tieba_dq_test"] 17 # sheet_tieba_dbdx = db_tieba["sheet_tieba_dbdx"] 18 sheet_tieba = db_tieba["sheet_tieba_ysu_914"] 19 20 """设置代理""" 21 # resp = requests.get("http://tor1024.com/static/proxy_pool.txt") 22 # ips_txt = resp.text.strip().split(" ") 23 # # print(ips_txt) 24 # ips = [] 25 # for i in ips_txt: 26 # try: 27 # k = json.loads(i) 28 # ips.append(k) 29 # except Exception as e: 30 # print(e) 31 32 header = { 33 "User-Agent": 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/51.0.2704.106 Safari/537.36', 34 "Cookie": 'XXX' 35 } 36 37 38 # 定义获取base_urls的函数 39 40 def get_base_urls(): 41 urls = ["http://tieba.baidu.com/f?kw=%E7%87%95%E5%B1%B1%E5%A4%A7%E5%AD%A6&ie=utf-8&pn={}".format(str(i)) for i in range(0, 383400, 50)] 42 return urls 43 def get_base_good_urls(): 44 urls=["http://tieba.baidu.com/f?kw=%E9%87%8C%E4%BB%81%E5%AD%A6%E9%99%A2&ie=utf-8&pn={}".format(str(i)) for i in range(0,10000,50)] 45 return urls 46 def get_last_reply_time(detail_url): 47 web_data = requests.get(detail_url) 48 web_data.encoding = "utf-8" 49 soup = BeautifulSoup(web_data.text, "lxml") 50 detail_page_num = soup.find_all(class_="red")[1].text 51 detail_page_last_url=detail_url+"?pn={}".format(detail_page_num) 52 web_data1 = requests.get(detail_page_last_url) 53 web_data1.encoding = "utf-8" 54 soup1 = BeautifulSoup(web_data1.text, "lxml") 55 last_post_time_data_0 = soup1.find_all(class_="l_post j_l_post l_post_bright ") 56 last_post_time_data = last_post_time_data_0[len(last_post_time_data_0)-1].get("data-field") 57 last_reply_post_time = last_post_time_data[int(last_post_time_data.find("date")) + 7:int(last_post_time_data.find("vote_crypt") - 3)] 58 return last_post_time_data 59 60 def get_detail_data(detail_url): 61 res = requests.get(detail_url) 62 res.encoding = "utf-8" 63 soup = BeautifulSoup(res.text,"lxml") 64 post_time_data = soup.find_all(class_='l_post j_l_post l_post_bright noborder ')[0].get("data-field") 65 author_dengji = soup.select("div.d_author > ul > li.l_badge > div > a > div.d_badge_lv")[0].text 66 author_lable = soup.select("div.d_badge_title")[0].text 67 reply_nus = soup.find_all(class_="red")[0].text 68 title = soup.select("div.core_title.core_title_theme_bright > h1")[0].text 69 author_name = soup.select("div.d_author > ul > li.d_name > a")[0].text 70 authon_contents = soup.find_all(class_="d_post_content j_d_post_content clearfix") 71 jingyan_scores = post_time_data[int(post_time_data.find("cur_score"))+11:int(post_time_data.find("bawu"))-2] 72 post_time = post_time_data[int(post_time_data.find("date")) + 7:int(post_time_data.find("vote_crypt")) - 3] 73 phone_is = post_time_data[int(post_time_data.find("open_type")) + 12:int(post_time_data.find("date")) - 2] 74 sex_is = post_time_data[int(post_time_data.find("user_sex")) + 10:int(post_time_data.find("user_sex")) + 11] 75 pic_num_firstpage = soup.find_all(class_="BDE_Image") 76 voice_num = soup.find_all(class_="voice_player_inner") 77 video_num = soup.find_all(class_="BDE_Flash") 78 detail_page_num = soup.find_all(class_="red")[1].text 79 contents = [] 80 for i in range(len(authon_contents)): 81 contents.append(authon_contents[i].text.strip()) 82 data={ 83 "nick_name":author_name, 84 "post_time":post_time, 85 "vehicle":phone_is, 86 "level":author_dengji, 87 "honored_name":author_lable, 88 "reply_num":reply_nus, 89 "title":title, 90 "sex":sex_is, 91 "jingyan_scores":jingyan_scores, 92 "pic_num":len(pic_num_firstpage), 93 "video_num":len(video_num), 94 "voice_num":len(voice_num), 95 "detail_page_num":detail_page_num, 96 "contents":contents, 97 "tiezi_url":detail_url 98 } 99 #print(data) 100 # sheet_tieba_ysu_good.insert_one(data) 101 # sheet_tieba_dbdx.insert_one(data) 102 # sheet_tieba_dq.insert_one(data) 103 sheet_tieba.insert_one(data) 104 #data1file(data) 105 def data1file(s): 106 path = r"C:UsersOscarDesktop数据.txt" 107 file = open(path, "a",encoding="utf-8") 108 file.write(" ") 109 file.write(str(s)) 110 file.close() 111 112 def get_detail_urls(url): 113 detail_links = [] 114 res = requests.get(url) 115 res.encoding = "utf-8" 116 soup = BeautifulSoup(res.text, 'lxml') 117 link_tags = soup.select("#thread_list div.threadlist_title.pull_left.j_th_tit > a") 118 for link_tag in link_tags: 119 detail_links.append("http://tieba.baidu.com/" + link_tag.get("href")) 120 return detail_links 121 # print(detail_links) 122 123 # 获取列表页数据 124 def get_data(url): 125 web_data = requests.get(url) 126 web_data.encoding = "utf-8" 127 soup = BeautifulSoup(web_data.text, "lxml") 128 titles = soup.select('#thread_list div.threadlist_title.pull_left.j_th_tit > a') 129 reply_nums = soup.select("div > div.col2_left.j_threadlist_li_left > span") 130 zhurens = soup.select("div.threadlist_author.pull_right > span.tb_icon_author > span.frs-author-name-wrap > a") 131 link_tags = soup.select('#thread_list div.threadlist_title.pull_left.j_th_tit > a') 132 #time.sleep(random.randint(1, 2)) 133 for title, reply_num, link_tag, zhuren in zip(titles, reply_nums, link_tags, zhurens): 134 data = { 135 "标题": title.get_text(), 136 "回复数": reply_num.text, 137 "主人": zhuren.get_text(), 138 "原文链接": "http://tieba.baidu.com/" + link_tag.get("href") 139 140 } 141 print(data) 142 143 def get_counts(): 144 f = open(r'C:UsersOscarDesktop1.txt', 'r', encoding='utf-8') 145 sentence = f.read() 146 #words = jieba.cut(sentence, cut_all=True) 147 #words = jieba.cut(sentence, cut_all=False) 148 words = jieba.cut_for_search(sentence) 149 tf = {} 150 for word in words: 151 print(word) 152 word = ''.join(word.split()) 153 if word in tf: 154 tf[word] += 1 155 else: 156 tf[word] = 1 157 return tf 158 159 def top_counts_sorted(tf, n=50): 160 value_key_pairs = sorted([(count, tz) for tz, count in tf.items()], reverse=True) 161 print(value_key_pairs[:n]) 162 163 # top_counts_sorted(get_counts()) 164 if __name__ == '__main__': 165 count=0 166 167 for base_url in get_base_urls(): 168 count = count + 1 169 detail_urls = get_detail_urls(base_url) 170 for detail_url in detail_urls: 171 try: 172 get_detail_data(detail_url) 173 except Exception as e: 174 print(e) 175 # pass 176 #time.sleep(random.randint(1,3)) 177 print("完成了第{}页的抓取".format(count))
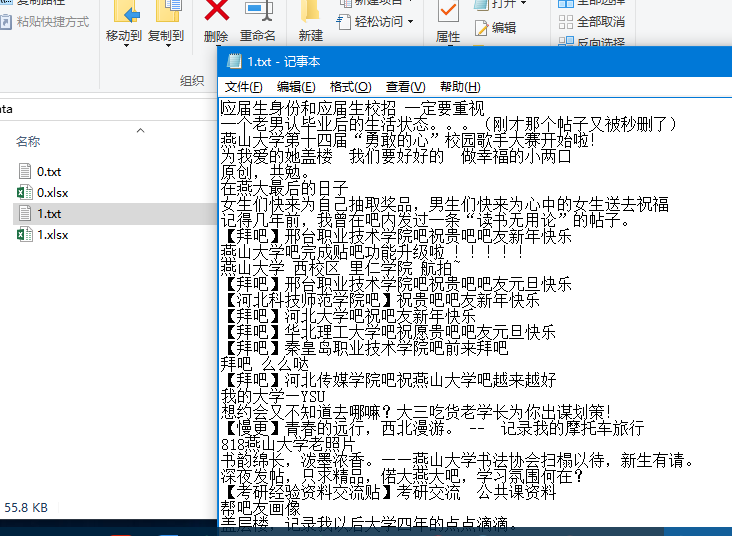
爬取后的数据存入到mongodb了,我最终导出到txt了。精品贴的标题和普通的贴的标题分别放在两个txt了,如下图所示(0.txt,1.txt)
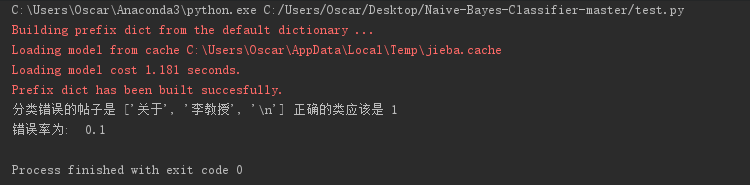
下面是 朴素贝叶斯的部分,没有包在类中,几个函数就行了,包括文件处理函数,创建单词表函数,训练函数,分类函数,主函数。
1 def text_split(textlist): 2 import re 3 word_cut = jieba.cut(textlist, cut_all=False) # 精确模式,返回的结构是一个可迭代的genertor 4 word_list = list(word_cut) # genertor转化为list,每个词unicode格式 5 return word_list 6 7 8 # 创建单词表 9 def createVocabList(dataSet): 10 vocabSet = set([]) # 创建一个空的集合 11 for document in dataSet: 12 vocabSet = vocabSet | set(document) # union of the two sets 13 return list(vocabSet) 14 15 16 def trainNB0(trainMatrix, trainCategory): 17 numTrainDocs = len(trainMatrix) # 训练矩阵的行数 18 numWords = len(trainMatrix[0]) # 字母表的维度,即训练矩阵的列数 19 pAbusive = sum(trainCategory) / float(numTrainDocs) # 先验信息 20 p0Num = ones(numWords); 21 p1Num = ones(numWords) # 改为 ones() 22 p0Denom = 2.0; 23 p1Denom = 2.0 # 改成 2.0 24 for i in range(numTrainDocs): 25 if trainCategory[i] == 1: 26 p1Num += trainMatrix[i] 27 p1Denom += sum(trainMatrix[i]) 28 else: 29 p0Num += trainMatrix[i] 30 p0Denom += sum(trainMatrix[i]) 31 p1Vect = log(p1Num / p1Denom) # 改为 log() 32 p0Vect = log(p0Num / p0Denom) # 改为 log() 33 return p0Vect, p1Vect, pAbusive 34 # 返回先验信息PAbusive,返回确定分类的条件下的每个单词出现的概率(此时概率为频率) 35 36 37 def classifyNB(vec2Classify, p0Vec, p1Vec, pClass1): 38 p1 = sum(vec2Classify * p1Vec) + log(pClass1) # 此时p1vec为对原始数组分别取对数之后的矩阵了,利用log(a*b)=sum(log(a)+log(b))再sum求和 39 # pClass1为先验概率,此时p1就是最终的概率值。同理p0,根据后验概率最大准则,判别 40 p0 = sum(vec2Classify * p0Vec) + log(1.0 - pClass1) 41 if p1 > p0: 42 return 1 43 else: 44 return 0 45 46 47 # 定义词袋模型,词出现几次算几次 48 def bagOfWords2VecMN(vocabList, inputSet): 49 returnVec = [0] * len(vocabList) # 初始化矩阵 50 for word in inputSet: 51 if word in vocabList: 52 returnVec[vocabList.index(word)] += 1 53 return returnVec 54 55 56 def spamTest(): 57 """" 58 文本矩阵化,构建文本矩阵和分类矩阵; 59 注意:由于有个文本的编码解码有问题,我给直接过滤掉了,所以最后矩阵有49行而不是50行 60 """ 61 docList = [];classList = [];fullText = [] 62 path=r"C:UsersOscarDesktopdata1.txt" 63 with open(path,encoding="utf8") as f: 64 i=0 65 while i<1046: 66 a=f.readline() 67 word_list=text_split(a) 68 docList.append(word_list) 69 classList.append(1) 70 fullText.extend(docList) 71 i=i+1 72 path=r"C:UsersOscarDesktopdata�.txt" 73 with open(path,encoding="utf8") as f: 74 i=0 75 while i<1546: 76 a=f.readline() 77 word_list=text_split(a) 78 docList.append(word_list) 79 classList.append(0) 80 fullText.extend(docList) 81 i=i+1 82 vocabList = createVocabList(docList) # 创建词汇表 83 84 trainingSet = list(range(2500)) 85 testSet = [] # 随机的构建测试集和训练集,留存交叉验证的方法 86 for i in range(10): # 测试集大小为10,训练集大小为49-10=39 87 randIndex = int(random.uniform(0, len(trainingSet))) 88 testSet.append(trainingSet[randIndex]) 89 trainingSet.pop(randIndex) 90 91 trainMat = [] 92 trainClasses = [] 93 for docIndex in trainingSet: 94 trainMat.append(bagOfWords2VecMN(vocabList, docList[docIndex])) 95 trainClasses.append(classList[docIndex]) 96 p0V, p1V, pSpam = trainNB0(array(trainMat), array(trainClasses)) 97 98 errorCount = 0 99 for docIndex in testSet: # classify the remaining items 100 wordVector = bagOfWords2VecMN(vocabList, docList[docIndex]) 101 if classifyNB(array(wordVector), p0V, p1V, pSpam) != classList[docIndex]: 102 errorCount += 1 103 print("分类错误的帖子是", docList[docIndex],"正确的类应该是",classList[docIndex]) 104 print('错误率为: ', float(errorCount) / len(testSet)) 105 # return vocabList,fullText 106 107 108 if __name__ == '__main__': 109 spamTest()