The present invention relates to processing of time series data. There is disclosed a method and apparatus for processing time series data, the method comprising: receiving a time series data set, wherein each element of the time series data set contains a timestamp and an original value associated with the timestamp, and times represented by all timestamps constitute a time series having fixed time intervals; converting each original value into a coded value occupying a smaller storage space, according to a predetermined monotone numerical compression coding scheme; dividing the times represented by all timestamps into a plurality of time intervals having a predetermined length; assembling coded values corresponding to all timestamps within each time interval into a data package such that the data package contains coded values arranged in an order of timestamps; and storing in a database record each data package and its associated identification of a time interval.
BACKGROUND
The present invention relates to the processing of time series data, and more specifically, to storage and retrieval of time series data in a database.
In applications involving the Internet of Things/sensors, it is required to process in real time large-scale time series data such as stock price fluctuations, temperature variations, blood pressure differences, tide tables, etc. Time series data consist of times and values.
Time series data contains timestamps and values associated with timestamps, e.g. containing sampling times and sampling values from a sensor. In various applications, such time series data need to be persistently stored in a database for query. Usually an approach to storing time series data in the prior art is to store the sampling times and the sampling values in one-to-one correspondence in a database. In association with such an approach, sampling times and sampling values are respectively used as keywords of an index file when creating the index file for the purpose of query. In such storage and indexed modes, data and index files occupy a large storage space, and the query speed is affected during data query because more I/O operations are needed. Waste of storage spaces during persistent storage of massive time series data and huge throughput requirements during querying massive time series data become especially prominent.
Therefore, there is a need to persistently store massive time series data with a low storage capacity while conveniently and rapidly querying such-stored massive time series data.
SUMMARY
In view of the existing situation, it is an object of the present invention to provide an improved method and apparatus for processing time series data.
On one hand, there is disclosed a method and apparatus for processing time series data, the method comprising: receiving a time series data set, wherein each element of the time series data set contains a timestamp and an original value associated with the timestamp, and times represented by all timestamps constitute a time series having fixed time intervals; converting each original value into a coded value occupying a smaller storage space according to a predetermined monotone numerical compression coding scheme; dividing the times represented by all timestamps into a plurality of time intervals having a predetermined length; assembling coded values corresponding to all timestamps within each time interval into a data package such that the data package contains coded values arranged in an order of timestamps; and storing in a database record each data package and its associated identification of a time interval.
On the other hand, there is disclosed a method and apparatus for processing time series data, the method comprising: receiving a time series data set, wherein each element of the time series data set contains a timestamp and an original value associated with the timestamp; converting each original value into a coded value occupying a smaller storage space, according to a predetermined monotone numerical compression coding scheme; dividing coded values into coded value intervals; for each coded value interval, assembling each coded value in the coded value interval and its timestamp into a data package such that the data package contains a low-order byte of each coded value and a timestamp corresponding to the coded value; and storing in a database record each data package together with an identification characterizing a corresponding coded value interval.
DETAILED DESCRIPTION
The present invention relates to processing of time series data, which may be implemented at computer system 100 shown in FIG. 1.
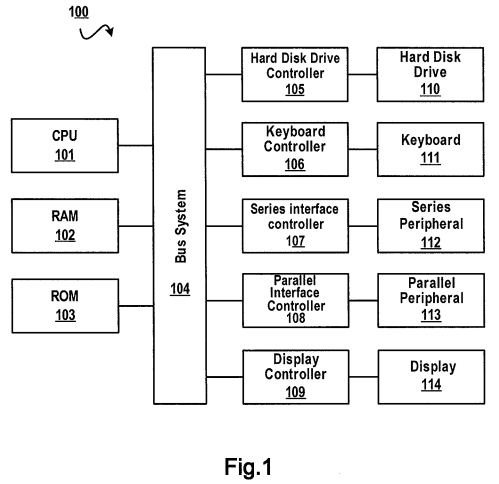
It is a general concept of the present invention to, in view of characteristics of time series data, compress time series data and store compressed time series data according to a corresponding data structure, thereby reducing a storage space required for storage of time series data and increasing the query speed of a range query of time series data.
The various embodiments are now illustrated with respect to the accompanying drawings.
First refer to FIG. 2. This figure schematically shows a flowchart of a method for processing time series data according to one embodiment of the present invention. The method for processing time series data as shown in FIG. 2 comprises the following steps.
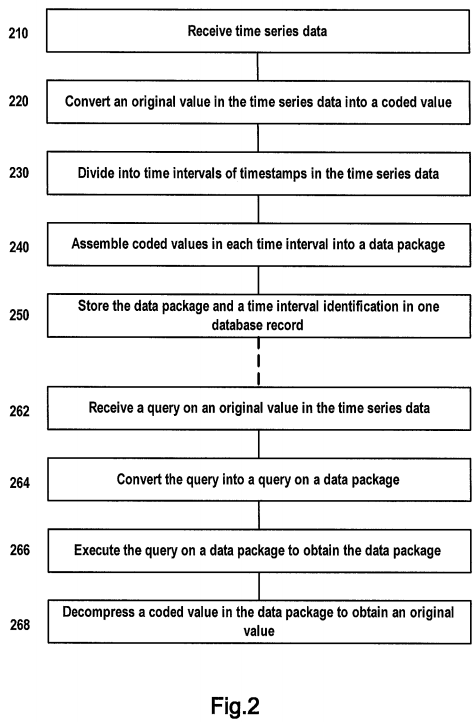

In Step 210, a time series data set is received, wherein each element of the time series data set contains a timestamp and an original value associated with the timestamp, and times represented by all timestamps constitute a time series having fixed intervals.
FIG. 4A schematically shows an example of a time series data set. In this figure, Table 411 represents a time series data set S. In the header of Table 411, "Line_No" represents a line number; "TS" represents a timestamp; and "OV" represents an original value. Each line of Table 411 represents an element of time series data set S, each element containing a timestamp and an original value associated with the timestamp. For example, the element at the 1st line contains a timestamp "20120716.10:47:00" and a value "32.0" associated with this timestamp, the timestamp representing a time "10:47:00 on Jul. 16, 2012." Times represented by all timestamps in Table 411 constitute a time series having fixed intervals. For example, an interval between a time represented by a timestamp "20120716.10:47:10" at the 2nd line and a time represented by the timestamp "20120716.10:47:00" at the 1st line is 10 seconds; an interval between times represented by timestamps at the 3rd line and the 2nd line is also 10 seconds, and so on and so forth.
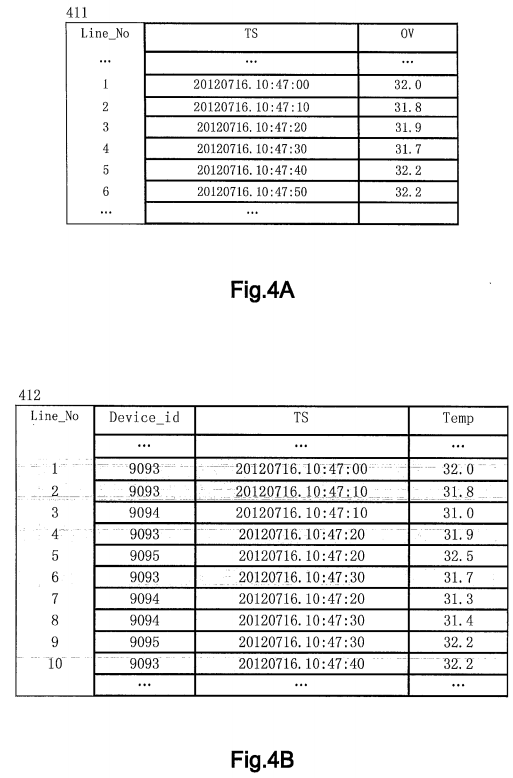
To facilitating description, an element in time series data set S is also referred to as "timestamp/original value pair," recorded as "<TS, OV>." For example, the element at the 1st line of Table 411 is recorded as <TS,OV>=<20120716.10:47:00,32.0>, representing the timestamp "20120716.10:47:00" and its associated original value "32.0."
TS (timestamp) and OV (original value) in <TS, OV> are correlated with each other. In different application, the original value might have different physical meanings. For example, <20120716.10:47:00,32.0> may be used to represent a sampling time and a sampling value generated by a temperature sensor, just as shown in FIG. 4B.
With reference to FIG. 4B, this figure schematically represents time series data generated by a sensor. More specifically, FIG. 4B schematically represents sampling times and sampling values received from different temperature sensors (not shown) by Table 412. In the header of Table 412, "Device_id" represents an identifier of a sensor, "TS" represents a sampling time, and "Temp" represents a temperature sampling value. Therefore, each line of Table 412 represents respectively a temperature value measured at a certain sampling time by a certain temperature sensor. For example, the 1st line represents a temperature value "32.0" measured at the time "20120716.10:47:00" by a sensor with an identifier of "9093"; the 3rd line represents a temperature value "31.8" measured at the time "20120716.10:47:10" by another sensor (with an identifier of "9094") . . . .
According to one embodiment of the present invention, time series data set S in Step 210 may contain time series data received from a sensor, a timestamp and an original value associated with the timestamp as contained in each element of time series data set S represents a sampling time of the sensor and a sampling value measured at the sampling time, respectively.
As an example, time series data set S shown in Table 411 may be regarded as a subset of sampled data shown in Table412, wherein each <TS, OV> of Table 411 is a sampling time and a sampling value from one identical temperature sensor with an identifier of "9093." In this case, timestamp TS represents a sampling time of the temperature sensor, and original value OV represents a temperature value associated with the sampling time.
Hereinafter the various embodiments of the present invention will be illustrated by taking time series data set S as an example. Note Table 411 shows only 6 elements contained in time series data set S, which, however, is merely exemplary. In practical applications, the amount of elements contained in a time series data set is huge. For example, if a sensor's sampling frequency is 10 Hz, then the sensor may generate 600 timestamp/original value pairs in 1 minute.
Now return to FIG. 2. Step 220 is executed after Step 210.
In Step 220, each original value is converted into a coded value occupying a smaller storage space, according to a predetermined monotone numerical compression coding scheme.
Various embodiments of Step 220 are illustrated below by way of example.
Numerical compression refers to converting an original value into a coded value such that a storage space required to store the coded value is smaller than a storage space required to store the original value. A monotone numerical compression coding scheme refers to that there exists a one-to-one correspondence between an original value and a coded value converted from a numerical compression; in other words, a coded value may be restored to an original value by using the same monotone numerical compression coding scheme.
According to one embodiment of the present invention, the predetermined monotone numerical compression coding scheme is a quantization compression coding scheme.
The quantization compression coding scheme is a monotone numerical compression coding scheme; by means of quantization compression, a double-precision floating-point of 8 bytes may be compressed into an integer of only 2 bytes. An algorithm of the quantization compression coding scheme is as shown by Equation (1) below:
CV=[(OV−LB)/(UB−LB)*65536]Equation (1)
In Equation (1), symbol "CV" represents a coded value or a compressed value, "OV" represents an original value; "UB" represents an Upper Bound; "LB" represents a Lower Bound; and "[ ]" represents a rounding operation.
The original value OV may be any value, e.g. a double-precision floating-point number of 8 bytes. The Upper Bound UB and the Lower Bound LB are both constants. In practically implementing the present invention, appropriate values may be set for the constants UB and LB according to concrete applications (such as a range of sampling values), empirical data and precision requirements.
For example, time series data set S in Table 411 represents data of temperature values generated by a temperature sensor and involving different sampling times. In this case, according to characteristics of temperature values, it may be set LB=−50 and UB=200.
For example, regarding the original value of the 1st element of the time series data set S, OV=32.0, the process for converting the original value into the coded value CV according to Equation (1) is as below:
CV=[((32.0−(−50))/(200−(−50))*65536]=[21495.808]=21496
"32.0" is a double-precision floating-point with a length of 8 (bytes), i.e. a storage space of 8 bytes is required in order to store the original value "32.0"; a hexadecimal value of the coded value CV="21496" is "OX53F8," with a length of 2 (bytes). This means that the length difference between the original value and the corresponding coded value is 6 bytes.
To facilitate illustration, the "length' of a numerical value mentioned below refers to the byte number required by this numerical value. A symbol "OX" is a prefix, representing that a numerical value following immediately is in hexadecimal format. For example, "OX53F8" represents a 2-byte hexadecimal value "53F8," which may be recorded as B1B2=0X53F8, i.e. the high-order byte B1=0X53 and the low-order byte B2=0XF8.
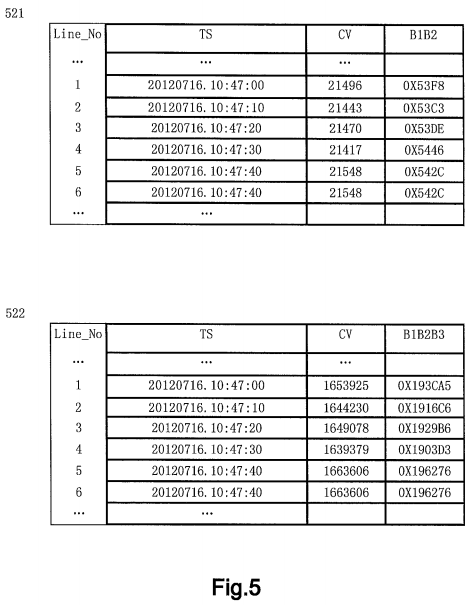
Similarly, other original values shown in Table 411 may be converted into corresponding coded values, with a result as shown in the 3rd column of Table 521 in FIG. 5. For example, original value OV=32.0 is converted into coded value CV=21496, original value OV=31.8 is converted into coded value CV=21443 . . . and original value OV=32.2 is converted into coded value CV=21548. The 4th column shows hexadecimal representation of each coded value, wherein symbol "B1B2" in the header represents a two-byte hexadecimal value. For example, the hexadecimal representation of coded value CV=21496 is B1B2=0X53F8, wherein the high-order byte B1=0X53 and the low-order byte B2=0XF8.
The quantization compression coding scheme is characterized in that an original value OV in double-precision floating-point format occupying 8 bytes may be converted into an integral coded value CV occupying 2 bytes, or a coded value CV may be restored to an original value OV. It can be verified that, although a rounding operation is employed in Equation (1), the loss of precision caused by the rounding operation may be reduced to a negligible extent by setting appropriate parameters according to a concrete application and experience.
Using a quantization compression coding scheme as the predetermined monotone numerical compression coding scheme has been illustrated above. However, the present invention is not limited to this. According to one embodiment of the present invention, the predetermined monotone numerical compression coding scheme in Step 220 may further be an arc tangent compression coding scheme.
Arc tangent compression coding is also a monotone numerical compression coding method, which can compress a double-precision floating-point of 8 bytes into an integer occupying a storage space of only 3 bytes. An algorithm of arc tangent compression coding is as shown by Equation (2) below:
CV=[256*256*256*arctan(OV/100)/π]Equation (2)
Wherein symbol "CV" represents a coded value; "OV" represents an original value; "arctan( )" is an arc tangent function; "π" is circumference ratio; and "[ ]" represents a rounding operation.
Take an original value OV=32.0 in time series data set S as an example.
The hexadecimal format of value 1653925 is 0X193CA5, occupying 3 bytes.
CV=[256*256*256*arctan(32.0/100)/π]=1653925
Similarly, other original values shown in Table 411 may be converted into corresponding coded values, with a result as shown in Table 522 in FIG. 5. The structure of Table 522 is similar to that of Table 521, except that symbol "B1B2B3" in the header shown in the 4th column represents a 3-byte hexadecimal value. For example, the hexadecimal representation of coded value CV=1653925 is B1B2B3=0X193CA5, wherein the high-order byte B1=0X19 and the low-order bytes B2B3=0X3CA5.
By means of the arc tangent compression coding scheme, an original value OV in double-precision floating-point format and occupying 8 bytes may be converted into an integral coded value CV occupying 3 bytes or a coded value CV may be restored to an original value OV.
The two embodiments of a monotone compression coding scheme have been illustrated by the above examples. Those skilled in the art should understand the present invention is not limited to this. In implementing the present invention, any other monotone compression coding scheme may also be adopted. An advantage of adopting a monotone compression coding scheme is after obtaining a coded value from an original value by a coding scheme, the original value may be derived from the coded value by the same coding scheme without requiring an additional storage space to store a mapping relationship between original values and coded values, thereby saving a storage space.
Step 230 is executed following Step 220.
In Step 230, the times represented by all timestamps are divided into a plurality of time intervals having a predetermined length.
Take time series data set S as an example. Suppose the predetermined length is 1 minute, then the times (20120716.10:47:00, 20120716.10:47:10, . . . ) represented by all timestamps in set S may be divided into a plurality of 1-minute time intervals, for example, 20120716.10:47:00 to 20120716.10:48:00 (excluded) is a 1-minute time interval. The number of timestamps displayed in Table 411 is rather limited, whereas times represented by timestamps that are not shown may be divided into more 1-minute time intervals, for example,
20120716.10:48:00 to 20120716.10:49:00 (excluded)
. . .
In Step 240, coded values corresponding to all timestamps in each time interval are assembled into a data package, such that the data package contains coded values arranged in an order of the timestamps.
A coded value is generated by converting an original value with a corresponding timestamp. According to an association between the original value and the timestamp, the coded value also has the same association with the timestamp corresponding to the original value.
For example, coded values CVs corresponding to timestamps in the time interval 20120716.10:47:00 to 20120716.10:48:00 (excluded) are 21496, 21443, 21470, 21417, 21548 and 21548. Therefore, these coded values are assembled into a data package (TVP) such that the data package TVP contains coded values 21496, 21443, 21470, 21417, 21548 and 21548 that are arranged in an order of timestamps.
With reference to FIG. 6, this figure schematically shows various data structures for storing time series data according to one embodiment of the present invention.
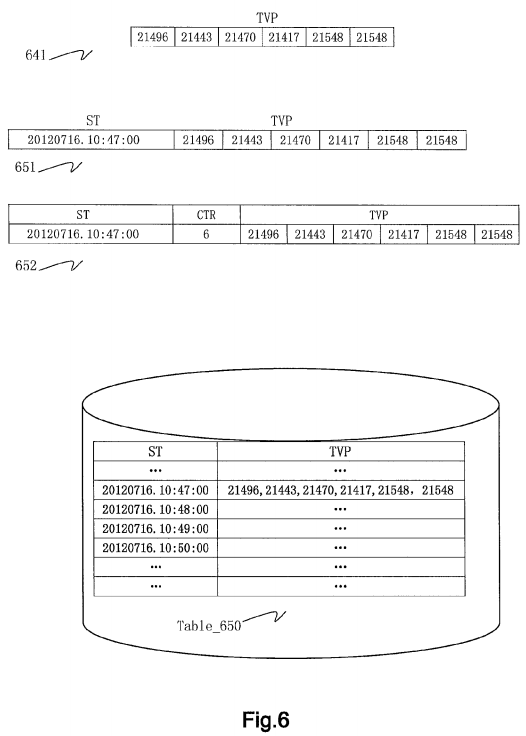
In FIG. 6, numeral 641 denotes a data package. Specifically, a data package 641 contains 6 coded values 21496, 21443, 21470, 21417, 21548 and 21548 corresponding to timestamps in the time interval 20120716.10:47:00 to 20120716.10:48:00 (excluded), which coded values are arranged in an order of timestamps and each of which coded values occupies two bytes.
After Step 240, the flow proceeds to Step 250 in which each data package and an identification of a time interval associated with the data package are stored in a database record.
With reference to FIG. 6, a numeral 651 in this figure denotes an example of database record. As shown in this figure, a database record 651 at least contains two fields, namely a time interval identification ST and a data package TVP.
Since a time interval having a predetermined length may be identified by start time of the time interval, according to one embodiment of the present invention, a start time ST of a time interval is used as an identification of the time interval, i.e. a time interval identification.
A time interval associated with the data package TVP field in database record 651 as shown in FIG. 6 is 20120716.10:47:00 to 20120716.10:48:00 (excluded). Therefore, a start time 20120716.10:47:00 of the time interval is used as an identification ST of the time interval, representing that the time interval is a time interval starting from 20120716.10:47:00 with a length of 1 minute.
Those skilled in the art should understand where times represented by timestamps constitute a time series having fixed intervals (e.g. 10 seconds), a timestamp corresponding to any coded value contained in a data package may be derived using such a data structure.
For example, a timestamp corresponding to the first coded value 21496 in data package TVP equals start time ST+0*10, i.e. 20120716.10:47:00; a timestamp corresponding to the second coded value 21443 equals start time ST+1*10 seconds, i.e. 20120716.10:47:10, . . . and so on and so forth.
With reference to FIG. 6, symbol Table_650 in this figure denotes an example of database table, and a database table Table_650 is a database table corresponding to Table 411. Database table Table_650 as shown in this figure contains a plurality of database records having a data structure as shown by numeral 651. For example, a database record contains a start time ST=20120716.10:47:00 and a corresponding data package TVP=<21496, 21443, 21470, 21417, 21548, 21548>.
Those skilled in the art should understand that in practically implementing the present invention, time intervals may be characterized in other manners. For example, a time interval having a fixed length may be characterized by an end time of the time interval. Therefore, the embodiment that a time interval having a fixed length is characterized by a start time is merely exemplary and does not constitute limitation on the various embodiments of the present invention.
According to one embodiment of the present invention, a count value may also be contained in each database record, representing the number of coded values contained in the data package. A structure of such a database record is as shown by a numeral 652. A count field CTR is contained in this database record, representing the number of coded values contained in data package TVP. For example, data package TVP of the database record as shown contains 6 coded values, and accordingly, a value of field CTR is 6.
The above-described process of a method for processing time series data involves storage of time series data. It should be pointed out that the order of steps in the method shown in FIG. 2 is merely exemplary and may have many variations in practice. For example, even if the order of Step 820 and Step 830 is changed, no impact is exerted on effects of the embodiments of the method of the present invention. Therefore, the order of the various steps shown in FIG. 2 does not constitute a strict limitation on the present invention. By means of the above method, not only a storage space for storing time series data can be reduced, but also the number of database records of time series data can be stored; therefore, disk I/O operations for accessing stored time series data can be reduced, so that the performance of the entire database system can be improved.
After time series data are stored using the above method, a query may be executed in response to a query request for time series data.
FIG. 2 schematically shows a process for processing a query on time series data according to one embodiment of the present invention, the process comprising Steps 262-268 below.
In Step 262, a query on an original value in time series data is received, the query containing a timestamp-based query condition.
The received query may be, for example, a query Q1 on an original value of a sensor with a device identification of "9093":
"getValueResult(*,Temperature, 20120716.10:47:00, 20120716.10:50)"
Query Q1 contains a timestamp-based query condition "20120716.10:47:00, 20120716.10:50," i.e. "a timestamp between 20120716.10:47:00 and 20120716.10:50 (excluded)." In other words, query Q1 means querying an original value OV, i.e. "temperature" conforming to the query condition in the database table with the data structure as shown in Table 411, by taking timestamp TS as an entry.
In Step 264, a corresponding query on a data package is generated according to the received query Q1.
For example, a query Q2 on a data package TVP is generated according to query Q1:
"select TVP from Table_650 where TS>=20120716.10:47:00 and TS<20120716.10:50:00"
Query Q2 means querying a data package TVP whose start time ST is between 20120716.10:47:00 and 20120716.10:50:00 (excluded) in a database table Table_650 shown in FIG. 6.
In Step 266, the generated query is executed to obtain a data package.
For example, with respect to the database table shown in FIG. 4B, three data packages may be obtained, which are data packages of records with respective start times of 20120716.10:47:00, 20120716.10:48:00 and 20120716.10:49:00.
In Step 268, according to the predetermined monotone numerical compression coding scheme, a coded value in the obtained data package conforming to the query condition is restored to a corresponding original value as a result of the received query.
For example, coded values of the data package with a start time of 20120716.10:47:00 which conform to the query condition are 21496, 21443, 21470, 21417, 21548 and 21548 respectively, which are generated from respective original values according to Equation (1). Therefore, these coded values are restored to corresponding original values according to the same Equation (1).
Take a coded value 21496 as an example. At this point, CV=21496, and an inverse operation is performed below according to Equation (1):
OV=[CV/65536*(200−(−50))−50]=32.00071=32.0
OV=32.0 is an original value resulting from restoring the coded value 21496 according to the predetermined monotone numerical compression coding scheme.
In the above equation, "[ ]" represents a rounding operation.
It can be verified that in the manner, 21443, 21470, 21417, 21548 and 21548 in data packages with a start time of a database record 20120716.10:47:00 can be restored to 31.8, 31.9, 31.7, 32.2 and 32.2 respectively.
Similarly, coded values in data packages (not shown) with start times of records 20120716.10:48:00 and 20120716.10:49:00 that conform to the query condition can be respectively restored to corresponding original values, which is not detailed here.
Note in the foregoing illustration, the descriptions of Query Q1, Query Q2 and the process of query are illustrative. Those skilled in the art may design various queries and various embodiments of execution based on the data structure shown in FIG. 7.

Note in the above manner of querying time series data on the basis of the data structure of storing time series data of the method according to the embodiment of the present invention, the number of database records to be outputted is cut down, so that disk I/O operations are reduced. Since the CPU speed is much larger than the disk I/O operation speed, the time spent in processing numerical conversion in the above process is trivial as compared with the time saved by reducing disk I/O operations.
A method for storing and querying time series data has been illustrated in conjunction with embodiments. Under the same inventive concept, the present invention further discloses another method for processing time series data.
FIG. 3 schematically represents a flowchart of a method for processing time series data according to another embodiment of the present invention.
Various embodiments of the method shown in FIG. 3 are illustrated in detail below with reference to figures.
As shown in FIG. 3, the method for processing time series data starts in Step 310.
In Step 310, a time series data set is received, wherein each element of the time series data set contains a timestamp and an original value associated with the timestamp.
Step 310 is substantially the same as Step 210 of the method shown in FIG. 2 and thus is not detailed. Hereinafter, still take time series data set S in FIG. 4A as the example of the time series data set received in Step 310.
In Step 320, each original value is converted into a coded value occupying a smaller storage space, according to a predetermined monotone numerical compression coding scheme.
Also, Step 320 is substantially the same as step 220 shown in FIG. 2, and a result is also as shown in Table 521 and Table522 in FIG. 5, which is not detailed here.
In Step 330, coded value intervals are divided for coded values.
According to one embodiment of the present invention, the dividing coded value intervals for coded values of Step 330comprises: dividing coded values with the same high-order byte into one coded value interval and using the high-order byte as a coded value interval identification.
Take a coded value B1B2 shown in the 4th column of Table 521 in FIG. 5 as an example. Since the high-order byte B1 of 0X53F8, 0X53C3 and 0X53DE is 0X53, 0X53F8, 0X53C3 and 0X53DE are divided into the same coded value interval, and B1=0X53 is used as a coded value interval identification for this coded value interval.
Likewise, since the high-order byte B1 of X5446, 0X542C and OX542C is 0X54, X5446, 0X542C and 0X542C are divided into the same coded value interval, and B1=0X54 is used as a coded value interval identification for this coded value interval.
For another example, take an example of a coded value B1B2B3 shown in the 4th column of Table 522 in FIG. 5, since their high-order byte B1 is 0X19, X193CA5, 0X1916C6, 0X1929B6 . . . are divided into the same coded value interval, and 0X19 is used as a coded value interval identification for this coded value interval.
In Step 340, regarding each coded value interval, each coded value and its timestamp in the coded value interval are packaged into a data package such that the data package contains a low-order byte of each coded value and a timestamp corresponding to the coded value.
With reference to FIG. 7, this figure schematically shows various data structures for storing time series data according to one embodiment of the present invention.
A numeral 741 in FIG. 7 denotes a data package VTP that is assembled from each coded value in a coded value interval characterized by B1=0X53 and its timestamp. As described above, the coded value interval characterized by B1=0X53 contains 3 coded values, whose low-order bytes are 0XF8, 0XC3 and 0XDE respectively. Data package VTP 741 contains low-order bytes of all coded values in the coded value interval characterized by B1=0X53 and timestamps corresponding to the coded values: <0XF8,20120716.10:47:00>, <0XC3,20120716.10:47:10> and <0XDE,20120716.10:47:20>.
According to one embodiment of the present invention, times represented by all timestamps in the time series data set constitute a time series having fixed intervals. In this case, a data package that is assembled from each coded value in a coded value interval and its timestamp contains the following data: a reference timestamp, a low-order byte (B2 in Table521 of FIG. 5 or B2B3 in Table 522 of FIG. 5) of each coded value, as well as a time difference A between a timestamp corresponding to the coded value and the reference timestamp.
A numeral 742 in FIG. 7 denotes another example of data package VTP that is assembled from each coded value in a coded value interval characterized by B1=0X53 and its timestamp.
The data package denoted by numeral 742 contains two portions:
- a reference timestamp ST, e.g. 20120716.10:47:00; and
- a low-order byte B2 of each coded value and a time difference A between a timestamp corresponding to the coded value and the reference timestamp, i.e. <0XF8,00>, <0XC3,10> and <0XDE,20>.
Time difference A may be a value representing the number of intervals. For example, Δ=10 (intervals) may represent there is a difference of 10 intervals between a timestamp corresponding to a coded value and reference timestamp ST. Since the time length L of each interval is fixed, it may be derived from reference timestamp ST, Δ and L that a timestamp corresponding to the coded value is ST+Δ*L.
Time difference Δ may also be a time value, e.g. Δ=10 (seconds). In this case, a timestamp corresponding to the coded value is ST+Δ.
In a word, each coded value and its corresponding timestamp may be derived from data pairs <0XF8,00>, <0XC3,10> and <0XDE,20>. Hereinafter, the various embodiments of the present invention are illustrated in the context where time difference Δ is a time value.
For example, in the data pair <0XF8, 00>, B2=0XF8, since the target's high-order byte B1="0X53," it may be derived that the coded value is B1B2="0X53F8." Δ=0 is a time difference between a timestamp corresponding to the coded value and a reference timestamp; since the reference timestamp is 20120716.10:47:00, it may be derived that a timestamp corresponding to the coded value is 20120716.10:47:00+0, i.e. "20120716.10:47:00."
Likewise, it may be derived from <0XC3,10> that it represents a coded value 0X53C3 and a corresponding timestamp 20120716.10:47:10; and it may be derived from <0XDE, 20> that it represents a coded value 0X53DE and a corresponding timestamp 20120716.10:47:20.
In Step 350, the data package and the coded value interval are stored in a database record.
With reference to FIG. 7, a numeral 751 in FIG. 7 denotes an example of database record. As shown in this figure, a database record 751 at least contains two fields: a coded value interval identification B1 and a data package VTP.
The coded value interval identification here adopts a common high-order byte B1=0X53 of all coded values in the coded value interval.
With reference to FIG. 7, a symbol Table_750 in FIG. 7 denotes an example of database table which corresponds to Table411. Database table Table_750 as shown in FIG. 7 contains a plurality of database records having a data structure as shown by numeral 751. For example, a database record contains a coded value interval identification B1=0X53 and a corresponding data package VTP=20120716.10:47:00, <0XF8,0>,<0XC3,10>,<0XDE,20>.
According to one embodiment of the present invention, each database record further contains a count value, representing the number of coded values contained in the data package. A structure of such a database record is as shown by a numeral752. A count field CTR is contained in this database record, representing the number of coded values contained in data package VTP. For example, data package VTP of the database record as shown contains 3 coded values, and accordingly, the value of field CTR is 3.
Those skilled in the art should understand in practically implementing the present invention, coded values intervals may be represented in other manners. For example, a coded value interval may be characterized by one or more bits of the coded value or two high-order bytes of a three-byte coded value B1B2B3. Therefore, the embodiment of using a high-order byte B1 of a two-byte coded value B1B2 to characterize a coded value interval is merely exemplary and does not constitute limitation on the various embodiments of the present invention.
Similar to the method for processing time series data as shown in FIG. 2, the above-described method for processing time series also involves storage of time series data. By means of the above method, not only a storage space for storing time series data can be reduced, but also the number of database records of time series data can be stored; therefore, disk I/O operations for accessing stored time series data can be reduced, so that the performance of the entire database system can be improved.
After time series data are stored using the above method, a query may be executed in response to a query request for time series data.
FIG. 3 schematically shows a process for processing a query on time series data according to one embodiment of the present invention, the process comprising Steps 362-366 below.
In Step 362, a query on a timestamp in time series data is received, the query containing an original value-based query condition.
The received query may be, for example, a query Q3 on a timestamp of a sensor with a device number of 9093:
"getTSResult(*,TS, 32.0,32.5)"
Query request Q3 contains an original value-based query condition "32.0,32.5," i.e. an original value between 32.0 and 32.5. In other words, query Q3 means querying timestamps corresponding to all original values that conform to the query condition in the database table as shown in Table 411, by taking original value OV as an entry.
In Step 364, the query on a timestamp in time series data is converted into a query on a timestamp on a data package according to the predetermined monotone numerical compression coding scheme.
For example, key values in range query Q3 are 32.0 and 32.5. Then, a query Q4 on a data package VTP in the database table Table_750 is generated according to query Q3.
According to Equation (1), original value 32.0 is converted into 0X53F8, and original value 32.5 is converted into 0X547B.
Q4="select TS from Table_750 where B1>=0X53 and B1<=0X54"
Query Q4 means querying in database table Table_4 a data package VTP whose high-order byte characterizing a coded value interval is between 0X53 and 0X54.
In Step 366, the generated query Q4 is executed to obtain a data package, and timestamps contained in the data package corresponding to each coded value that conforms to the query condition are regarded as a query result.
For example, with respect to database table Table_750 shown in FIG. 7, 2 data packages may be obtained:
contents of the first data package VTP are <20120716.10:47:00>,<0XF8,00>,<0XC3,10>,<0XDE,20>; from this data package, the following timestamps conforming to the query condition specified in Q3 may be derived: 20120716.10:47:00, 20120716.10:47:10, 20120716.10:47:20.
contents of the second data package VTP are <20120716.10:47:00>,<0X1903D3 ,30>,<0X0X196276,40>,<0X0X196276,50>; from this data package, the following timestamps may be derived: 20120716.10:47:30, 20120716.10:47:40, 20120716.10:47:50.
Note in the foregoing illustration, the descriptions of instances such as time series data set S, database table Table_750, Query Q3 and Query Q4 and the description of the process of corresponding queries are illustrative. In implementing the present invention, those skilled in the art may design other variations of the above embodiments for various application environments, based on the foregoing descriptions and with respect to the data structure shown in FIG. 7.
The various embodiments of the method for processing time series data of the present invention have been illustrated above. Under the same inventive concept, the present invention further provides an apparatus for processing time series data.
With reference to FIG. 8, this figure schematically shows a block diagram of an apparatus for processing time series data according to one embodiment of the present invention.
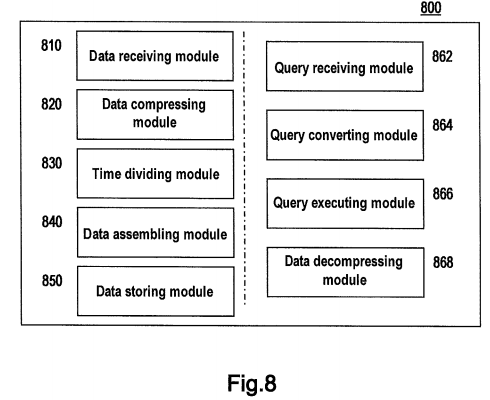
An apparatus 800 for processing time series data as shown in FIG. 8 comprises: a data receiving module 810, a data compressing module 820, a time dividing module 830, a data assembling module 840 and a data storing module 850.
Data receiving module 810 is configured to receive a time series data set, wherein each element of the time series data set contains a timestamp and an original value associated with the timestamp, and times represented by all timestamps constitute a time series having fixed time intervals.
Data compressing module 820 is configured to convert each original value into a coded value occupying a smaller storage space, according to a predetermined monotone numerical compression coding scheme.
Time dividing module 830 is configured to divide the times represented by all timestamps into a plurality of time intervals having a predetermined length.
Data assembling module 840 is configured to assemble coded values corresponding to all timestamps within each time interval into a data package such that the data package contains coded values arranged in an order of timestamps.
Data storing module 850 is configured to store in a database record each data package and its associated identification of a time interval.
According to one embodiment of the present invention, the predetermined monotone numerical compression coding scheme comprises any one of a quantization compression coding scheme and an arc tangent compression coding scheme.
According to one embodiment of the present invention, apparatus 800 further comprises: a query receiving module 862, a query converting module 864, a query executing module 866 and a data decompressing module 868.
Query receiving module 862 is configured to receive a query on an original value in the time series data, the query containing a timestamp-based query condition.
Query converting module 864 is configured to generate a corresponding query on a data package according to the received query.
Query executing module 866 is configured to execute the generated query to obtain the data package.
Data decompressing module 868 is configured to restore a coded value in the obtained data package conforming to the query condition to a corresponding original value as a request of the received query, according to the predetermined monotone numerical compression coding scheme.
According to one embodiment of the present invention, the data storing module of apparatus 800 is further configured to store in the database record the number of coded values contained in the data package.
According to one embodiment of the present invention, the time series data set contains time series data received from a sensor, wherein the timestamp and a value associated with the timestamp contained in each element of the time series data set are a sampling time from the sensor and a value associated with the sampling time respectively.
With reference to FIG. 9, this figure schematically shows a block diagram of an apparatus for processing time series data according to another embodiment of the present invention.
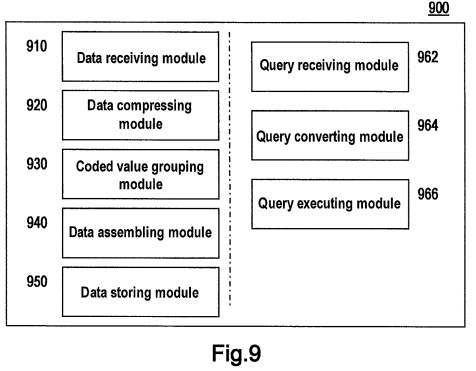
An apparatus 900 for processing time series data as shown in FIG. 9 comprises: a data receiving module 910, a data compressing module 920, a coded value grouping module 930, a data assembling module 940 and a data storing module950.
Data receiving module 910 is configured to receive a time series data set, wherein each element of the time series data set contains a timestamp and an original value associated with the timestamp, and times represented by all timestamps constitute a time series having fixed intervals.
Data compressing module 920 is configured to convert each original value into a coded value occupying a smaller storage space, according to a predetermined monotone numerical compression coding scheme.
Coded value grouping module 930 is configured to divide coded values into coded value intervals.
Data assembling module 940 is configured to, for each coded value interval, assemble each coded value in the coded value interval and its timestamp into a data package such that the data package contains a low-order byte of each coded value and a timestamp corresponding to the coded value.
Data storing module 950 is configured to store in a database record each data package together with an identification characterizing a corresponding coded value interval.
According to one embodiment of the present invention, the predetermined monotone numerical compression coding scheme comprises any one of a quantization compression coding scheme and an arc tangent compression coding scheme.
According to one embodiment of the present invention, coded value grouping module 930 is further configured to divide coded values having the same high-order byte into one coded value interval, and data storing module 950 is further configured to use the high-order byte as an identification of the coded value interval.
According to one embodiment of the present invention, times represented by all timestamps in the time series data set constitute a time series having fixed time intervals, and data assembling module 940 is further configured to cause the data package to contain a reference timestamp, a low-order byte of each coded value and a time difference between a timestamp corresponding to the coded value and the reference timestamp.
According to one embodiment of the present invention, apparatus 900 further comprises: a query receiving module 962, a query converting module 964 and a query executing module 966.
Query receiving module 962 is configured to receive a query on a timestamp in the time series data, the query containing an original value-based query condition.
Query converting module 964 is configured to convert the query on the timestamp in the time series data into a query on a timestamp in a data package, according to the predetermined monotone numerical compression coding scheme.
Query executing module 966 is configured to execute the generated query to obtain the data package and regard timestamps in the data package corresponding to each coded value that conforms to the query condition as a query result.