项目源码可以参考我的github:https://github.com/corolcorona/StacksSpider
1.明确需要获取的内容(标题,链接),然后把需要获取的内容写到items.py中,通过检查获取内容的html,可以看出我们要获取的内容标签
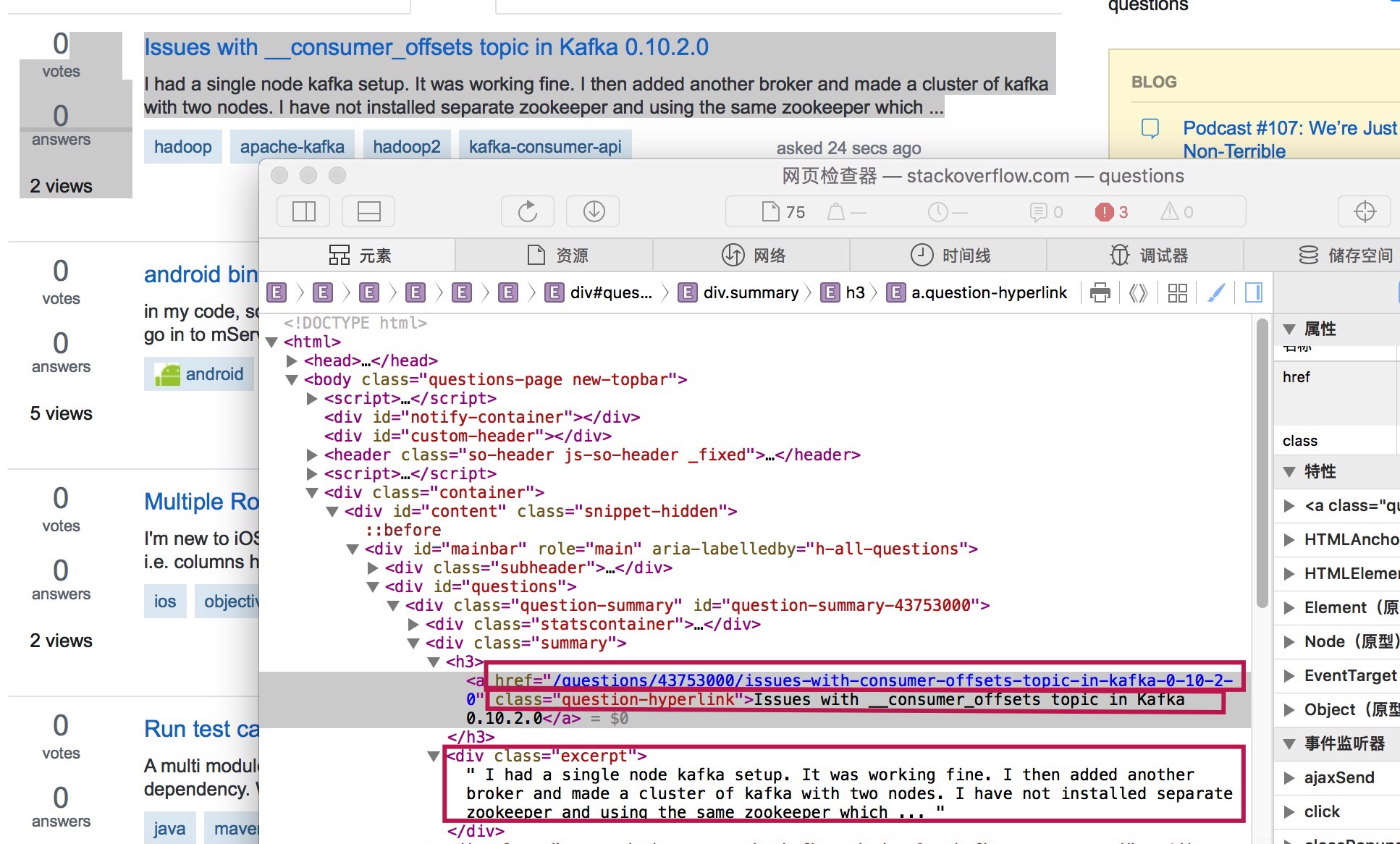
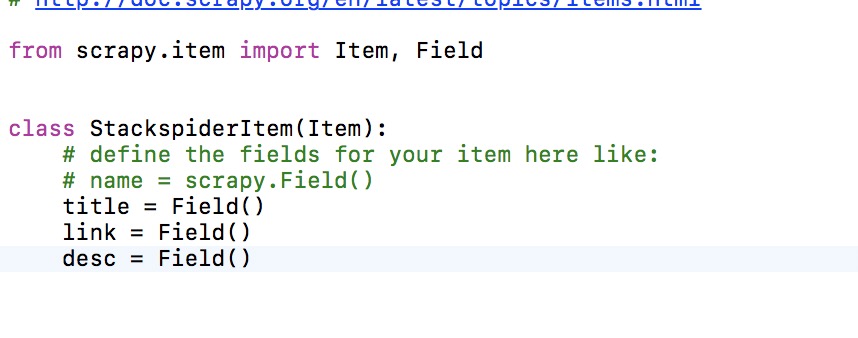
2.根据页面的html获取到我们需要的内容
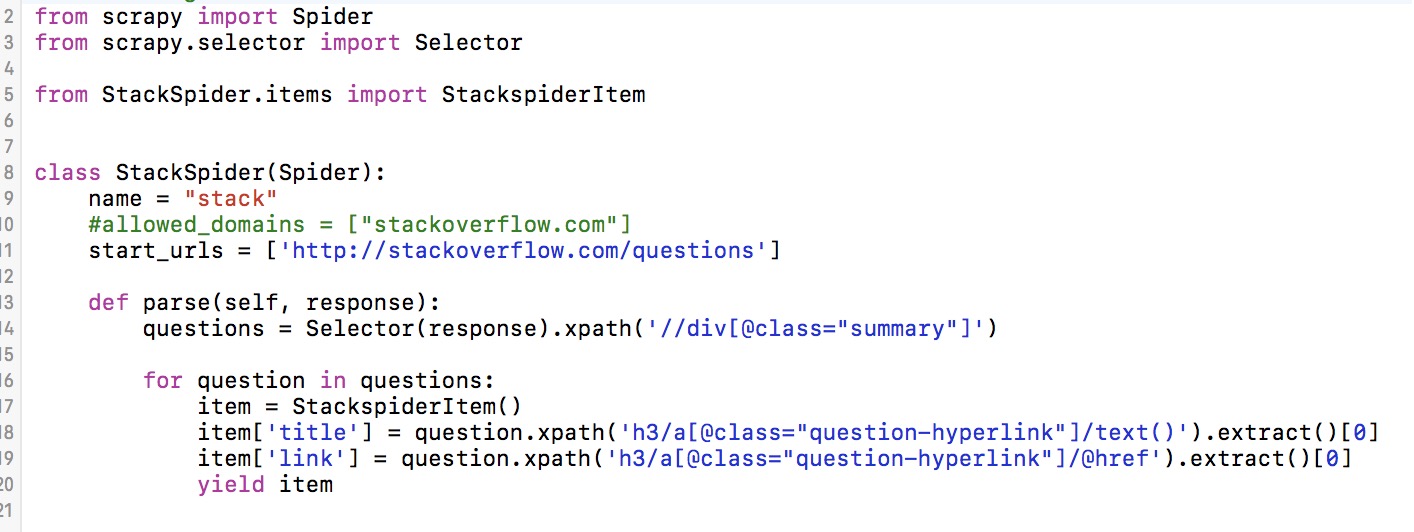
3.运行以下命令生成一个 items.json文件查看我们获取到的内容
scrapy crawl stack -s USER_AGENT='Mozilla/5.0' -o items.json -t json