1. 单词查找树
跟各种查找树一样,单词查找树也使用了一种树形结构。从根结点出发,指向了R个结点(R是字母表的大小)。然后底下的每个结点又都分别对应了R个结点。下图中只是示意图,只画出了部分结点的字结点,其实每个结点都有R个子结点。

以一个映射表为例:
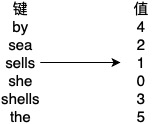
转化成单词查找树的结构即为下图:

注意上图只画出了非空的结点。同时注意上图中键对应的值也写出来了,这个值其实是每个结点对应的一个属性。
在查找过程中,只有当查找结尾是有值的结点才是真正的键。如果提前遇到了空结点,或者最后的结点没有值,那么均表示查找失败。
插入过程也是同样的道理,假如在尾字符之前就遇到了空结点,此时需要为未被检查的字符创建对应的结点并将值保存在最后一个结点中。假如尾字符对应不是空结点,就把该结点的值设置为键所对应的值。
1)查找树的数据结构
public class TrieST<Value> { private static int R = 256; private Node Root; private static class Node { private Object val; //如果没有值,那么val = null private Node[] next= new Node[R]; } public Value get(String key) { Node x = get(Root, key, 0); if(x==null) return null; return (Value)x.val; } private Node get(Node x, String key, int d) { if(x==null) return null; if(d==key.length()) return x; char c = key.charAt(d); return get(x.next[c], key, d+1); } public void put(String key, Value val) { Root = put(Root, key, val, 0); } //注意这里每次都要返回x自己,相当于每新建一个node,都要返回,然后沿着这个新的Node继续 private Node put(Node x, String key,Value val ,int d) { if(x==null) x= new Node(); if(d == key.length()) { x.val = val; return x; } char c = key.charAt(d); x.next[c] = put(x.next[c], key, val, d+1); return x; } public int size() { return size(Root); }
private int size(Node x) { if(x==null) return 0; int cnt = 0; if(x.val!=null) cnt++; for(char c=0;c<R;c++) cnt += size(x.next[c]); return cnt; }
}
2) 查找所有键的函数
//查找所有键 public Iterable<String> keys() { return keysWithPrefix(""); } public Iterable<String> keysWithPrefix(String pre) { Queue<String> q = new Queue<String>; collect(get(Root, pre, 0), pre, q); return q; } private void collect(Node x, String pre, Queue<String> q) { if(x==null) return; if(x.val!=null) q.enqueue(x); for(char c=0;c<R;c++) collect(x.next[c], pre+c, q); }
3)通配符匹配
public Iterable<String> keysThatMatch(String pat) { Queue<String> q = new Queue<String>(); collect(Root, "", pat, q); return q; } private void collect(Node x, String pre, String pat, Queue<String> q) { if(x==null) return; int d = pre.length(); if(d == pat.length() && x.val!=null) q.enqueue(pre); if(d==pat.length()) return; char next = pat.charAt(d); for(char c=0;c>R;c++) { if(next == '.'||next==c) collect(x.next[c], pre+c, pat, q); } }
4) 最长前缀
public String longestPrefixOf(String s) { int length = search(Root, s, 0, 0); return s.substring(0, length); } private int search(Node x,String s, int d, int length) { if(x==null) return length; if(x.val!=null) length = d; if(d == s.length()) return length; char c = s.charAt(d); return search(x.next[c],s,d+1,length); }
5)删除
public void delete(String key) { Root = delete(Root, key, 0); } private Node delete(Node x, String key, int d) { if(x==null) return null; if(d== key.length()) x.val = null; else { char c = key.charAt(d); delete(x.next[c], key, d+1); } if(x.val!=null) return x; for(char c=0;c<R;c++) //只要有一个子链接不为空,就直接返回当前结点 if(x.next[c]!=null) return x; return null; }
以上代码表示了关于字典树这种数据结构的常规操作,还是富有一些技巧性的,例如多次用到递归等。需要多多练习。
参考资料:《算法》 第四版