参考摘取原文:https://www.sohu.com/a/281740874_99987664(感谢大佬)
https://www.cnblogs.com/zhaobowen/p/13807092.html(感谢大佬)
https://www.jb51.net/article/139671.htm(感谢大佬)
背景:
Python 中可以读取 word 文件的库有 python-docx 和 pywin32。
优点缺点python-docx跨平台只能处理 .docx 格式,不能处理.doc格式pywin32仅限 windows 平台.doc 和 .docx 都能处理。
一. pywin32模块
这个库很强大,不仅仅可以读取 word,但是网上介绍用 pywin32 读取 .doc 的文章真不多,因为,真心不好用。
以下是 pywin32 读取 .doc 的代码示例,但是读取表格有问题,输出全是空,原因不明,因为不打算用所以没有深入研究。另外,如果表格中有纵向合并单元格,会报错:“无法访问此集合中单独的行,因为表格有纵向合并的单元格。”
源码:
from win32com.client import Dispatch
word = Dispatch('Word.Application') # 打开word应用程序
# word = DispatchEx('Word.Application') # 启动独立的进程
word.Visible = 0 # 后台运行,不显示
word.DisplayAlerts = 0 # 不警告
path = r'E:abc est.doc'
doc = word.Documents.Open(FileName=path, Encoding='gbk')
for para in doc.paragraphs:
print(para.Range.Text)
for t in doc.Tables:
for row in t.Rows:
for cell in row.Cells:
print(cell.Range.Text)
doc.Close()
word.Quit
但是 pywin32 有另外一个功能,就是将 .doc 格式另存为 .docx 格式,这样我们就可以使用 python-docx 来处理了。
(1)首先把pywin32模块安装上,并引入

(2)其次将doc文件转换为docx文件,然后读取内容
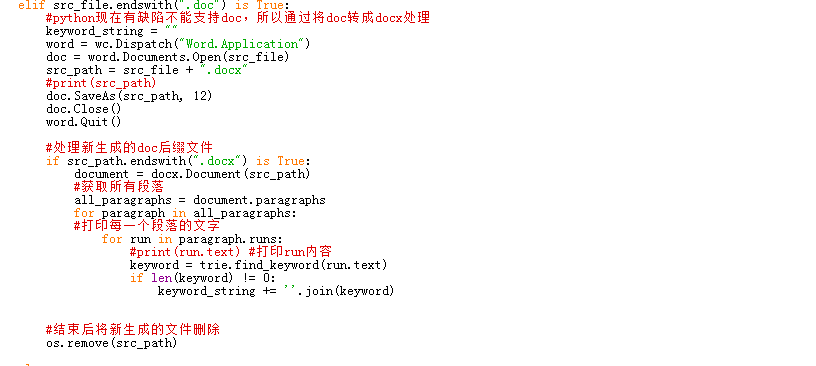
【下面的比较详细,仅供自己学习】
python-docx读取doc,docx文档
API: http://python-docx.readthedocs.io/en/latest/#api-documentation
1.将doc转为docx
python3.8中win32com 要安装pypiwin32 pip install pypiwin32
from win32com import client as wc
word = wc.Dispatch("Word.Application")
doc = word.Documents.Open(路径+名称.doc)
doc.SaveAs(路径+名称.docx, 12) 12为docx
doc.Close()
word.Quit()
2.读取段落
import docx
docStr = Document(docName) 打开文档
for paragraph in docStr.paragraphs:
parStr = paragraph.text
--》paragraph.style.name == 'Heading 1' 一级标题
--》paragraph.paragraph_format.alignment == 1 居中显示
--》paragraph.style.next_paragraph_style.paragraph_format.alignment == 1 下一段居中显示
--》paragraph.style.font.color
3.读取表格
numTables = docStr.tables
for table in numTables:
#行列个数
row_count = len(table.rows)
col_count = len(table.columns)
for i in range(row_count):
row = table.rows[i].cells
i行j列内容:row[j].text
或者:
row_count = len(table.rows)
col_count = len(table.columns)
for i in range(row_count):
for j in range(col_count):
print(table.cell(i,j).text)
4.按样式读取
读取标题
for p in doc.paragraphs:
if p.style.name=='Heading 1':
print(p.text)
import re
for p in doc.paragraphs:
if re.match("^Heading d+$",p.style.name):
print(p.text)
读取正文
for p in doc.paragraphs:
if p.style.name=='Normal':
print(p.text)
获取docx支持的样式
from docx.enum.style import WD_STYLE_TYPE
for i in s:
if i.type==WD_STYLE_TYPE.PARAGRAPH:
print(i.name)
5.获取文字格式信息
paragraph 对象 里还有更小的 run 对象,run 对象才包含了段落对象的文字信息。
paragraph.text 方法也是通过 run 对象的方法获取到文字信息的:
paragraph.text 方法源码:
def text(self):
text = ''
for run in self.runs:
text += run.text
return text
文字的字体、大小、下划线等信息都包含在 run 对象中(不清楚的看前面的博客):
获取段落的 run 对象列表
runs = par0.runs
print(runs)
获取 run 对象
run_0 = runs[0]
print(run_0.text) # 获取 run 对象文字信息
打印结果:
坚持因地制宜,差异化打造特色小镇,
文档 段落 和 run 对象示意:
获取文字格式信息:
# 获取文字格式信息
print('字体名称:',run_0.font.name)
# 字体名称: 宋体
print('字体大小:',run_0.font.size)
# 字体大小: 152400
print('是否加粗:',run_0.font.bold)
# 是否加粗: None
print('是否斜体:',run_0.font.italic)
# 是否斜体: True
print('字体颜色:',run_0.font.color.rgb)
# 字体颜色: FF0000
print('字体高亮:',run_0.font.highlight_color)
# 字体高亮: YELLOW (7)
print('下划线:',run_0.font.underline)
# 下划线: True
print('删除线:',run_0.font.strike)
# 删除线: None
print('双删除线:',run_0.font.double_strike)
# 双删除线: None
print('下标:',run_0.font.subscript)
# 下标: None
print('上标:',run_0.font.superscript)
# 上标: None
LIK2
6.设置首行缩进
from docx.shared import Inches,Pt
par2 = doc.add_paragraph('段落文本')
# 左缩进,0.5 英寸
par2.paragraph_format.left_indent = Inches(0.5)
# 右缩进,20 磅
par2.paragraph_format.right_indent = Pt(20)
# 首行缩进
par2.paragraph_format.first_line_indent = Inches(1)
查看首行缩进单位
from docx import Document
from docx.shared import Inches
from docx.oxml.ns import qn
from docx.shared import Cm, Pt
from docx.enum.text import WD_PARAGRAPH_ALIGNMENT
from docx.shared import RGBColor
myDocument = Document('2020年建交集团3月分析报告.docx')
for paragraph in myDocument.paragraphs:
print(paragraph.paragraph_format.first_line_indent)
print(dir(paragraph))【批量的读取doc文档】
解决方案:利用python将大批.doc文件转化为.docx文件,再读写.docx文件
问题分析:python利用python-docx (0.8.6)库可以读取.docx文件或.txt文件,且一路畅通无阻,而对.doc文件本身python是无能为力的,那有很多同学就不服气,我手动把.doc文件的后缀名改为.docx或.txt不就解决问题了吗?答案是不能的,简单修改后缀名,那么文件就被你玩坏了,别说打不开,就是打开也是天书啊(乱码)。python无法操作.doc文件是他的先天不足,但是我们不要钻牛角尖一定要在互联网上找到一种源码直接读取.doc文件,一调用就好了,但是不幸的是,你可能在网上也找不到解决方案。正当我一筹莫展之时,我将.doc文档利用手动的方式“另存为”.docx文档,就能够成功打开转化后的.docx文档,于是我就尝试利用代码方式完成这个手动的“另存为”功能,问题得以解决。
直接上python代码(首先你需要先安装pypewin32库):
|
1
2
3
4
5
6
7
8
|
# -*- coding: utf-8 -*-:import sysimport pickleimport reimport codecsimport stringimport shutilfrom win32com import client as wc |
|
1
|
def doSaveAas(): # 想批处理文件,你就用for循环呗,我一次性处理了100多个文件,代码执行不超过2分钟,可以解决问题,目标文件路径可以自由改动,大家注意SaveAs方法中的参数,好多啊,别写错了 |
|
1
2
3
4
5
|
word = wc.Dispatch('Word.Application')doc = word.Documents.Open(u'C:\Users\X\PycharmProjects\1\大家好.doc') # 目标路径下的文件doc.SaveAs(u'C:\Users\X\PycharmProjects\1\我是一枚小小的程序员X007.docx', 12, False, "", True, "", False, False, False, False) # 转化后路径下的文件 doc.Close()word.Quit() |
转化为.docx文件后,在处理.docx文件,一路畅通无阻。