目的
1) 提取下厨房关键词为(早餐,午餐,晚餐)的菜谱
2) 获取“菜谱链接,图片地址,菜名,材料,七天内多少人做过,作者“,存储到MONGODB
3) 对每个菜谱进行网页截图,保存到本地
2. 目标站点分析
网址:
输入关键词“早餐”,发现是跳转链接(暂时没想到这种怎么处理比较好,就单独拿出来处理吧)
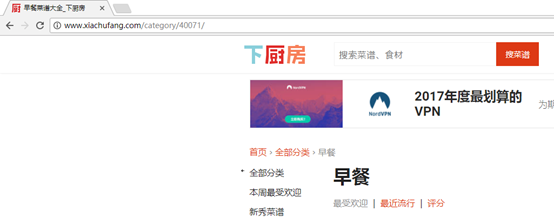
午餐和晚餐的网址就比较一致
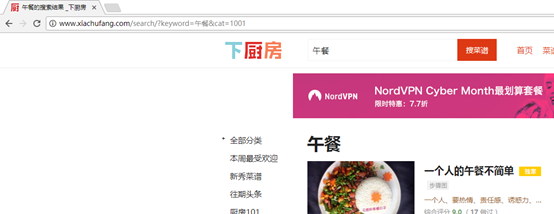
3. 爬取思路(以午餐为例)
1) 根据午餐关键词,组合url,请求得到第一页结果
2) 解析第一页结果,使用正则表达式获取,提取详情页信息和其他信息
3) 根据详情页信息的url获取详情页,截图保存,文件夹使用详情页URL的ID_菜名
4) 改变page参数,获取多页内容
4. 需要处理的
1) 早餐的url独立处理(跳转的url还没学过怎么处理)
2) 有一些菜谱存在综合评分的数字,有些不存在,无法用正则表达式统一提取,待改进
3) 获取的菜谱名和用户名几乎都会存在windows下文件夹不能存在的特殊字符,使用链式replace替换
4) page用于多线程处理
5) 截图使用selenium和Phantomjs完成,暂时只会截取全屏,还没研究过怎么截取需要的部分
6) 增量更新,包括数据库和网页截图的方法(做法变化或者作者更新删除等的判断),这些还没学会怎么做(虽然现在的爬虫框架比如Scrapy/Pyspider都提供了去重的功能,但是具体实现还没研究过),这是一个造轮子的过程
5. 代码部分
1) 解析每一页,得到“菜谱链接,图片地址,菜名,材料,七天内多少人做过,作者”

2) 解析详情页,并截图
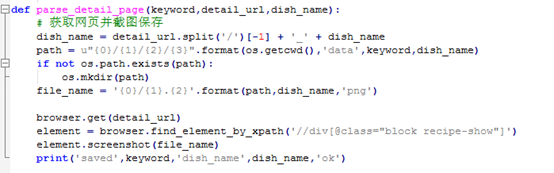
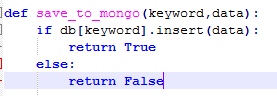
3) 存到MongoDB
4) 开启多线程

以前写个爬虫要1天时间,现在好了一点,2小时能撸完一个简单的爬虫,再接再厉
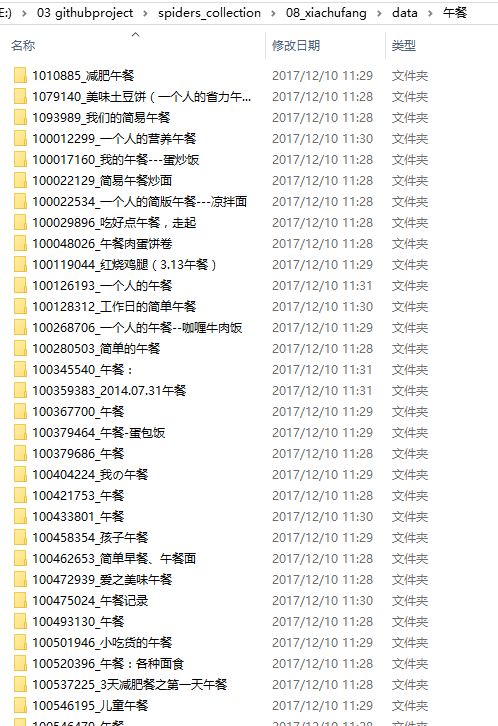
爬取效果:
18页结果一共运行了5分半钟(4核处理器)
代码地址:
https://github.com/copywang/spiders_collection/tree/master/08_xiachufang