目录
- 三个经典网络
- 残差网络
- 1x1卷积
- google inception网络
- 迁移学习
- 数据增强
- 如何使用开源代码
一、三个经典网络
- LeNet
[LeCun et al., 1998. Gradient-based learning applied to document recognition]
这篇文章较早,比如现在常用max,而当时用avg,当时也没有softmax
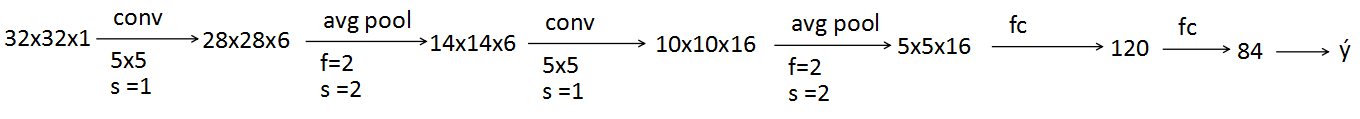
- AlexNet
[Krizhevsky et al., 2012. ImageNet classification with deep convolutional neural networks]
这篇文章让CV开始重视深度学习的使用,相对于LeNet-5,它的优点有两个:更大,使用ReLU
same表示使用same过滤器,也就是输入和输出维度一致
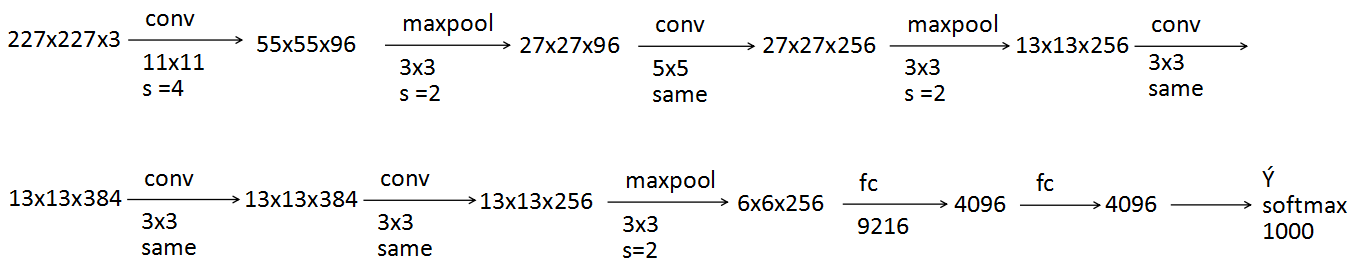
- VGG-16
[Simonyan & Zisserman 2015. Very deep convolutional networks for large-scale image recognition]
16表示总共有16个CONV和FC,这篇文章指出了信道数和维度变化的规律性(随网络增加/减少),缺点是参数实在太多了

阅读论文顺序:2-3-1
二、残差网络
[He et al., 2015. Deep residual learning for image recognition]
- 残差网络基础
残差网络由残差块组成,它使得网络可以变得更深。蓝色为正常路径,紫色为短路/跳跃连接,$a^{[l]}$的信息会直接作为$a^{[l+2]}$计算的输入(残差)。插入的位置是线性计算后,激活前
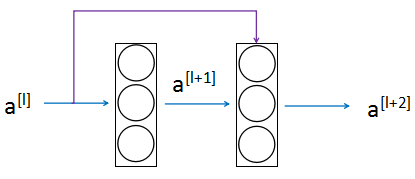
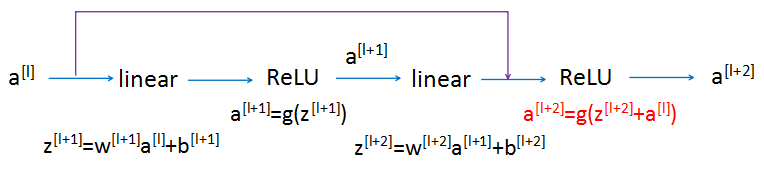
- plain network的问题
plain network指一般的网络。在plain network中随着深度增加,优化算法更难执行,所以可能会出现错误率先降后升的情况
网络越深越难训练:梯度消失/爆炸的问题
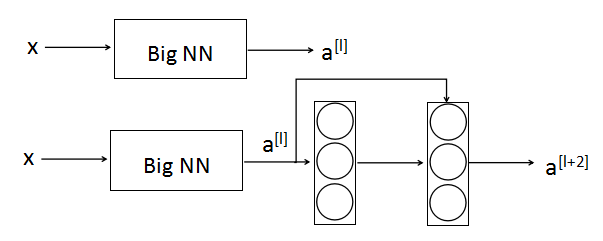
- 为什么Residual网络有用
假设对一个大型网络再增加两层(构成残差块)
|
$a^{[l+2]}=g(a^{[l]}+z^{[l+2]})\=g(a^{[l]}+w^{[l+2]}a^{[l+1]}+b^{[l+2]})$ 如果让$w^{[l+2]}=0$,$b^{[l+2]}=0$,则$a^{[l+2]}=g(a^{[l]})$ 如果$g(x)$用ReLU激活函数,则$a^{[l+2]}=a^{[l]}$ 所以,在原来的网络上加上两层,再通过残差网络,还是可以很容易学习到恒等关系 如果不用残差网络,$a^{[l+2]}=g(z^{[l+2]})=g(w^{[l+2]}a^{[l+1]}+b^{[l+2]})$,要用这个学习到$a^{[l+2]}=a^{[l]}$,明显会比上面的方式难 当$a^{[l+2]}$和$a^{[l]}$形状不同时,$a^{[l+2]}=W_sa^{[l]}$,增加一个$W_s$矩阵。这个矩阵可以是学习的矩阵/参数,或固定矩阵(只是对$a^{[l]}$用0进行填充,使得变成想要的矩阵) |
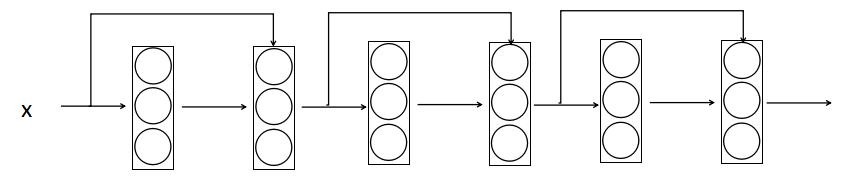
- 残差网络的结构图
三、1x1卷积Network in network
[Lin et al., 2013, Network in network]
- 1x1卷积
当channel=1时,1x1没有什么效果
当channel=$n_c$时,$ReLU(n_hxn_wxn_c * (1x1xn_c)n_oc + b)=ReLU(n_hxn_wxn_oc + b)$,相当于对输入的元素运用了ReLU(非线性函数)
- 1x1卷积的作用
通过增加一个非线性函数使得信道数减少或保持不变(压缩信道的方法),以减少计算量
而池化层只能是对高度/宽度进行压缩
28x28x192 --ReLU(conv 1x1x32)-->28x28x32
四、google Inception网络
[Szegedy et al. 2014. Going deeper with convolutions]
Inception可以帮你决定应该采用什么样的过滤器,是否需要pool层等
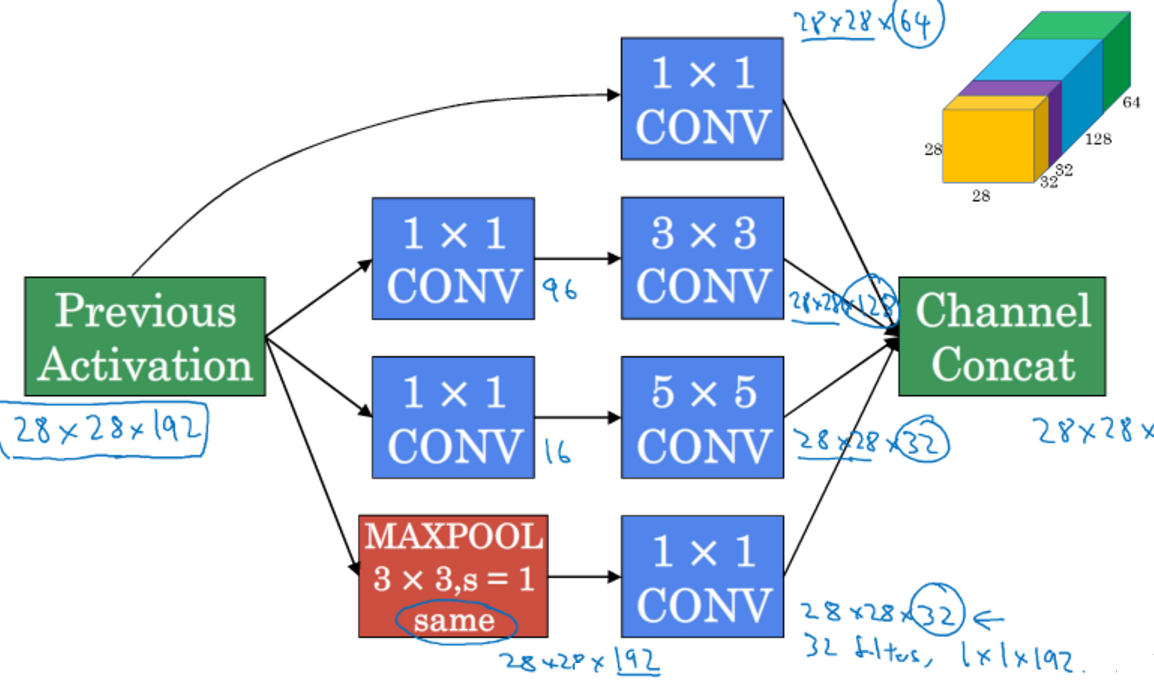
它的做法是把各种过滤器的结果堆叠在一起
下例中的维度是自己定义的,这样最后输出的结果中会有256个信道
下图是一样Inception的一个基础块

- 问题:计算量很大
以上例中5x5过滤器为例,就需要计算120M次乘法
例 Input: 28x28x192 filter: 5x5 same 32 output:28x28x32
计算次数=5x5x32x28x28x32约等于120M
解决方法:加一个1x1过滤器,也称为bottleneck层(瓶颈层,是网络中是小的层)
28x28x192--conv 1x1x192 16-->28x28x16--conv 5x5x16 32-->28x28x32
计算次数=28x28x192x16 + 5x5x16x28x28x32 约等于12.4M下例中计算量就会降成12.4M
- 一个更完整些的Inception模块
大型的Inception网络结构:
其实就是把上面的模块重复连接。另外,网络后面几层会有一些分支。它们也和最后的输出一样进行输出,也就是说隐藏层也参与了最后输出的计算,这样可以避免过拟合的问题
小故事:Inception原名是googlenet,是为了向LeNet致敬,而后引用了Inception(盗梦空间),意在建议更深的网络
五、迁移学习
在CV中经常会用到迁移学习:利用已经训练好的网络来学习其它问题。一般推荐使用开源的网络来做,而非从0开始。根据拥有的数据量不同,有不同的处理方式
当数据量很小的时候,可以把最后一层softmax替换掉,而把前面所有的层不变(一般有参数如trainable, freeze可以用于设置参数不变),只训练最后一层
当数据量大一些的时候,可以多训练几层,也就是把前几层freeze,而后面几层进行训练
当数据量很大时,可以对整个网络进行训练,原来训练好的结果作为初始值, 这样就不用用随机初始化
六、数据扩充(augmentation)
对于CV应用,一般来说数据越多,网络性能越好。对于其它应用可能不一定,但是对计算机视觉,数据量是一个重要的因素。数据扩充就是对原有数据进行处理以获得更多的数据
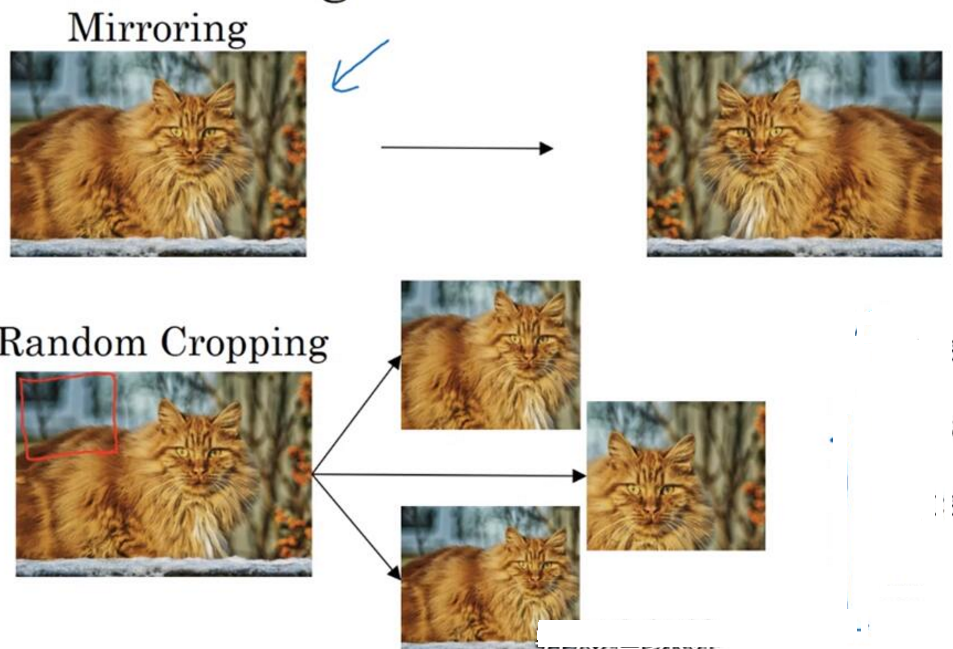
- 常用的方法
mirror(镜像)/random crop(随机裁剪)/rotation(旋转)/shearing(切变)/local warping(局部扭曲变形)
改变颜色(PCA(主成分分析))
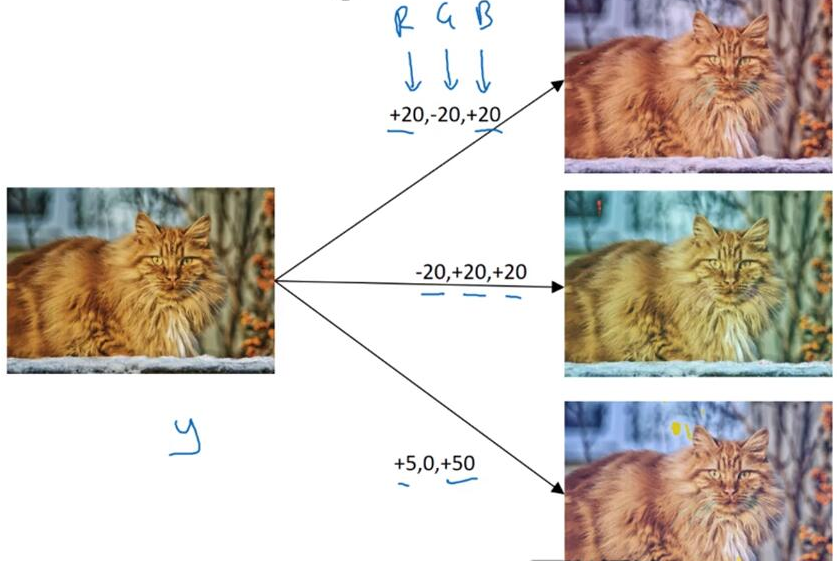
- data augmentation(增强)的实现
采用多线程,一个线程读取数据并修改,改后的数据传递给其它线程训练,实现数据处理与网络训练并行
超参数:颜色要改变多少,裁剪什么位置等
七、如何使用开源代码
使用网络框架
尽可能使用开源的实现
使用预训练好的模型,并在自己的数据集上fine-tune