1.集合:集合无序,不重复,可以用set(列表) 方法将列表转换为集合,实现去重
对比列表:集合是{}包围,列表是[]包围
对比字典:集合是没有key的,字典是有key的
set_1 = {1, 2, 3}
set_2 = {1, 2, 4, 5, 7}
set_3 = {1, 2, 3, 4, 5, 6, 7, 8}
set_4 = {4, 5, 6}
# set_1 跟 set_2 的交集
print(set_1.intersection(set_2))
print(set_1 & set_2)
# set_1 跟 set_2 的并集
print(set_1.union(set_2))
print(set_1 | set_2)
# set_1 跟 set_2 的差集:取出set_1有的而set_2没有的集合 = set_1 - 两者交集
print(set_1.difference(set_2))
print(set_1 - set_2)
# set_1 跟 set_2 的对称差集:取出set_1跟set_2互相没有的集合 = 两者并集 - 两者交集
print(set_1.symmetric_difference(set_2))
print(set_1 ^ set_2)
# 判断set_1 是否为 set_3的子集
print(set_1.issubset(set_3))
# 判断set_3 是否为 set_1的父集
print(set_3.issuperset(set_1))
# 判断set_1 跟set_4 是否没有交叉数据,即无交集返回True,有交集返回Flase
print(set_1.isdisjoint(set_4))
# set添加一个
set_1.add(999)
print(set_1)
# set添加多个
set_1.update([777, 888, "aa", "bb"])
print(set_1)
# set删除方法1,key不存在报错
set_1.remove("aa")
print(set_1)
# set删除方法2,key不存在也不报错
set_1.discard("ddd")
print(set_1)
# 判断字符是否在集合(字符串,列表,字典)里面
print("bb" in set_1)
# 判断字符是否不在集合(字符串,列表,字典)里面
print("cc" not in set_1)
2.文件操作的几种方式
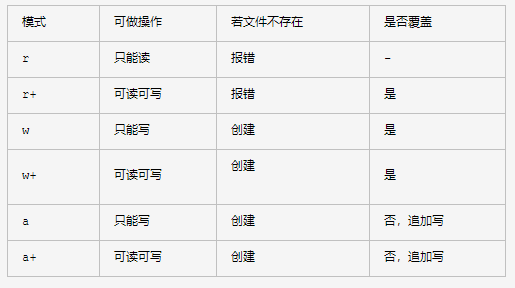
打开二进制文件只需要后面加b字符,如rb, rb+, wb, wb+, ab, ab+,二进制文件一般用于网络传输,视频文件之类。
# tell(): 返回当前文件指针的位置 # seek(): 回到指定指针位置 # 读模式,找不到文件报错,不可写入 file = open("测试数据3", mode="r", encoding="utf-8") # eg1 read()里面可带整型参数,表示读取个字符个数,不写表示全读 data = file.read() print(data) file.close() # eg2 读一行,清除一行,保证内存只有一行,(Python内部优化) for data in file: print(data) file.close() # eg3 一次以列表形式全部读取到内存上,小文件可以这样做,大文件有可能撑爆内存 for data in file: print(data) file.close() # 写模式,找不到文件则创建,找到则覆盖,相当于清空内容 file = open("测试数据", mode="w", encoding="utf-8") file.write("END END END") file.close() # 追加模式,找不到文件则创建,找到同名文件不会覆盖,同时可以追加写入 file = open("测试数据55", mode="a", encoding="utf-8") file.write("abc") file.close() # 读写模式,找不到文件则创建,找到同名文件不会覆盖,同时可以追加写入 file = open("测试数据2", "a+", encoding="utf-8") print(file.readline()) file.write("end ") file.close() # 写读模式,找不到文件则创建,找到同名文件则覆盖,同时可以追加写入 file = open("测试数据", "w+", encoding="utf-8") file.write("end1 ") file.write("end2 ") file.seek(2) file.write("aaaaaa ") print(file.readline()) file.close() # 追加读写模式,找不到文件报错,找到同名文件则覆盖,覆盖写入 file = open("测试数据2", "r+", encoding="utf-8") file.write("abc ") file.write("ddd ") file.write("aaa ") file.close()
with语法:
# with 打开文件,可以自动关闭,防止忘记关闭,同时可以打开多个 with open("测试数据", "r", encoding="utf-8") as file: for line in file: print(line) # 等价于上面 file = open("测试数据", "r", encoding="utf-8") for line in file: print(line) file.close() # with 打开多个文件 with open("测试数据", "r", encoding="utf-8") as file, open("测试数据2", "r", encoding="utf-8") as file2: for line in file: print(line) for line in file2: print(line)
3.函数
① 声明一个函数: def 函数名(函数参数):
# 写函数操作
def fun_name(): print("this is a fun")
② 函数参数:
在 python 中,类型属于对象,变量是没有类型的:
a=[1,2,3] a="Runoob"
以上代码中,[1,2,3] 是 List 类型,"Runoob" 是 String 类型,而变量 a,变量a,变量a,它就是一个变量,变量没有类型,变量只能指向一个对象的引用(一个指针),该指针可以指向 strings, tuples, numbers, list, dict。
然而,Python中参数分为可更改对象(mutable) 跟不可以更改对象(ummutable)
strings, tuples, 和 numbers 是不可更改的对象,而 list,dict 等则是可以修改的对象,所以将 strings,tuples,numbers作为函数参数传过去的时候,操作这个参数只是操作了参数的副本,对原本值没有影响,但如果将 list,dict作为参数传过去,再操作这个参数,就会影响原本的值了。
③参数类型,不重复写,引用此文
④注意的点, *args,**kwargs:主要用于定义函数的可变参数。
*args:发送一个非键值对的可变数量的参数列表给函数
**kwargs:发送一个键值对的可变数量的参数列表给函数
如果要同时使用*args和**kwargs时,*args必须写在**kwargs之前,否则报错