三、读和写
mapreduce的输入数据一般来自较大的文件,通常为GB或TB级。MapReduce的基本处理原则是将输入数据分割成块,这些块可以在计算机上并行处理。块的大小需要权衡,如果太大,则并行粒度就会较大,如果太小,则启动和停止处理每个块所需时间就会占去很大部分执行时间。
1、InputFormat
Hadoop分割与读取输入文件的方式被定义在InputFormat借口的一个实现中,TextInputFormat是InputFormat的默认实现,当你想要一次性读取一行数据,而且数据没有确定的键值时,这种数据结构会很有用。
常用InputFormat类如下
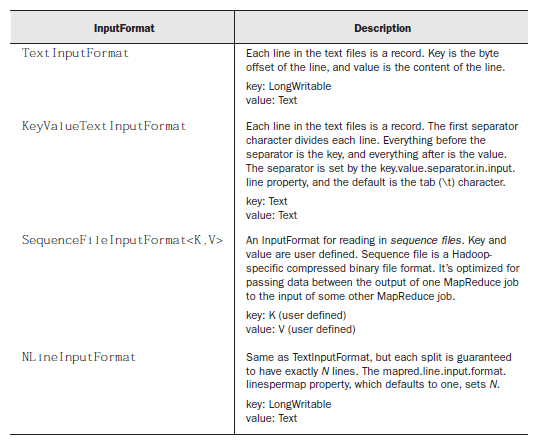
要设置相应的InputFormat 类可以用JobConf对象,如
JobConf conf = new JobConf(*.class); conf.setInputFormat(KeyValueTextInputFormat);
当我们期望采用与标准InputFormat类不同的方式读取数据时,我们可以自己定制InputFormat类。InputFormat是一个包含两个方法的接口:
这个方法总结了InputFormat需要执行的两个功能:
public interface InputFormat<K, V> { InputSplit[] getSplits(JobConf job, int numSplits) throws IOException; RecordReader<K, V> getRecordReader(InputSplit split,JobConf job,Reporter reporter) throws IOException; }
· 确定所有要输入数据的文件,并将之分割为分片。每个map任务分配一个分片。
· 提供一个对象(RecordReader),循环提取给定分片中的记录,并解析每个记录为预定义类型的健和值。
因为考虑将文件划分为分片是一项很繁重的工作,所以在创建自己的InputFormat类的时候,最好从负责文件分割的FiliInputFormat类中继承一个子类。
2、OutputFormat
与InputFormat相似。每个reducer将它的输出写入自己的文件中,输出无需分片。Hadoop提供了几个标准的FileOutputFormat实现,可以通过调用JobConf对象中的setOutputFormat()定制OutputFormat。

默认的OutputFormat是TextOutputFormat,它将每个记录写为一行文本。每个记录的key和value通过toString()转化为字符串,并通过制表符 分割。