1、Mapper
一个类要作为mapper必须实现Mapper接口,并且继承MapReduceBase类。
Mapper负责数据处理阶段,形式为Mapper<K1,V1,K2,V2>,Mapper只有一个方法map,用于处理一个单独的key/value对。Hadoop预定义了一些非常有用的Mapper

2、Reducer
一个类要作为Reducer必须实现Reducer接口,并且继承MapReduceBase类。当reducer接受来自各个mapper的输出时,将按照key值对输入数据进行排序,并按照排序结果输出给不同的reducer。
同样,Hadoop预定义了一些非常有用的reducer类

3、Partitioner:重定向Mapper输出
在笔记(1)中我提到了,在map和reduce阶段中间还有一个非常重要的阶段:将mapper的结果输出给不同的reducer,这就是partitioner的工作。
默认的做法是对key进行散列来确定reducer,hadoop通过HashPartitioner类强制执行这个策略。但是有时我们想通过key值中的某个属性进行排序,而不是key的整体,使用HashPartitioner就会出错。所以我们需要自己定制partitionger。如前面提到的Edge类,我们希望通过departure属性排序,而不是key((DepartureNode,arrivalNode))进行排序。
public class EdgePartitioner implements Partitioner<Edge, Writable> { @Override public int getPartition(Edge key, Writable value, int numPartitions) { return key.getDepartureNode().hashCode() % numPartitions; } @Override public void configure(JobConf conf) { } }
这张图也许能更好的帮助理解partitioner:
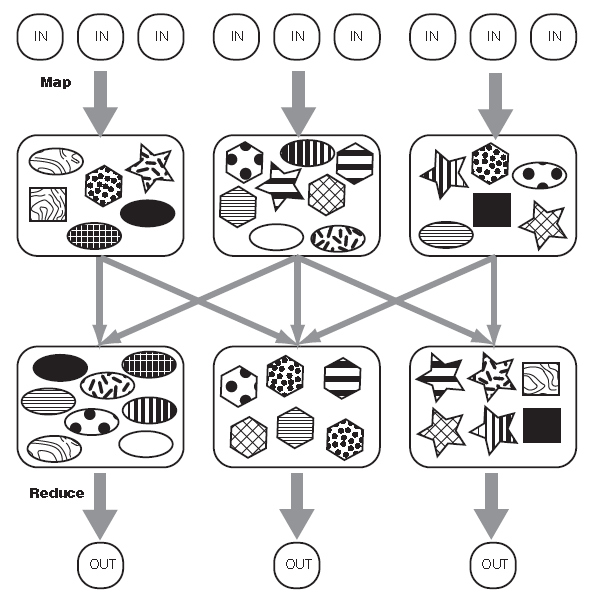
每个图是一个key/value对,形状代表key。内部图案代表value。shuffling过后,相同key的图标放入相同的reducer,不同的键也可以放入同一个reducer。partitioner决定放入的位置。
4、Combiner:本地Reducer
combiner是在map结束后输出之前进行本地reducer,这样可以减少传输量,提高性能。
5、使用预定义的mapper和reducer类重写WordCount
public class WordCount2 { public static void main(String[] args) { JobClient client = new JobClient(); JobConf conf = new JobConf(WordCount2.class); FileInputFormat.addInputPath(conf, new Path(args[0])); FileOutputFormat.setOutputPath(conf, new Path(args[1])); conf.setOutputKeyClass(Text.class); conf.setOutputValueClass(LongWritable.class); conf.setMapperClass(TokenCountMapper.class); conf.setCombinerClass(LongSumReducer.class); conf.setReducerClass(LongSumReducer.class); client.setConf(conf); try { JobClient.runJob(conf); } catch (Exception e) { e.printStackTrace(); } } }
注意:以上代码使用hadoop旧的API写成,有许多在新API中不建议使用的类和接口。