图神经网络

node embedding
回顾了之前node2vec的例子以及深度学习卷积的一些基础
浅层encoder的局限性:
参数数量O(v):节点间没有共享参数,每个节点有自己的embedding
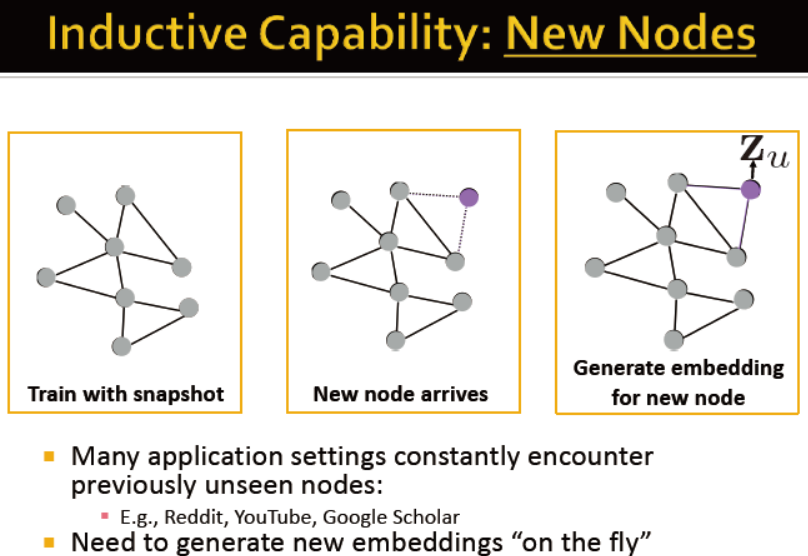
不能表征未见过的节点
没有综合考虑节点特征

本节学习图神经网络,多层的非线性的


那么,在图中,如何做卷积?
如果输入是邻接矩阵,那么模型不能适配各种规模的网络;对节点的顺序也没有敏感性

图的深度学习基础


起初,对于一个图G
V:节点集合
A:邻接矩阵
X:节点的特征向量

图卷机网络
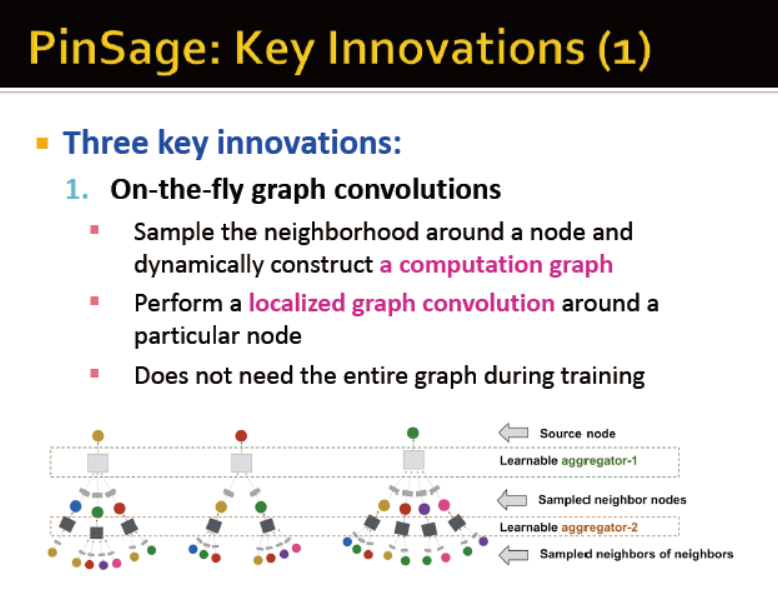
思路:图的邻居定义计算图
信息传播→计算节点特征
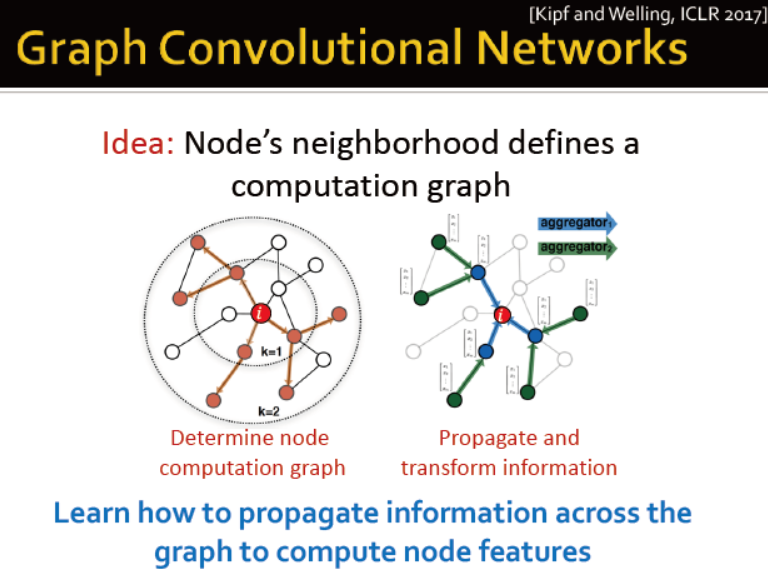
邻居聚合:局部网络邻居
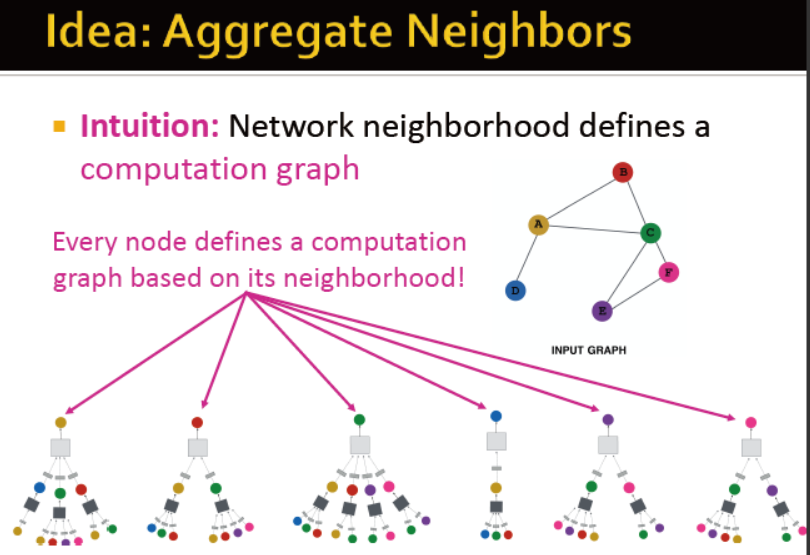
intuition:节点通过神经网络,从邻居聚合信息
intuition:网络的邻居定义计算图→每个节点基于自身的邻居定义计算图


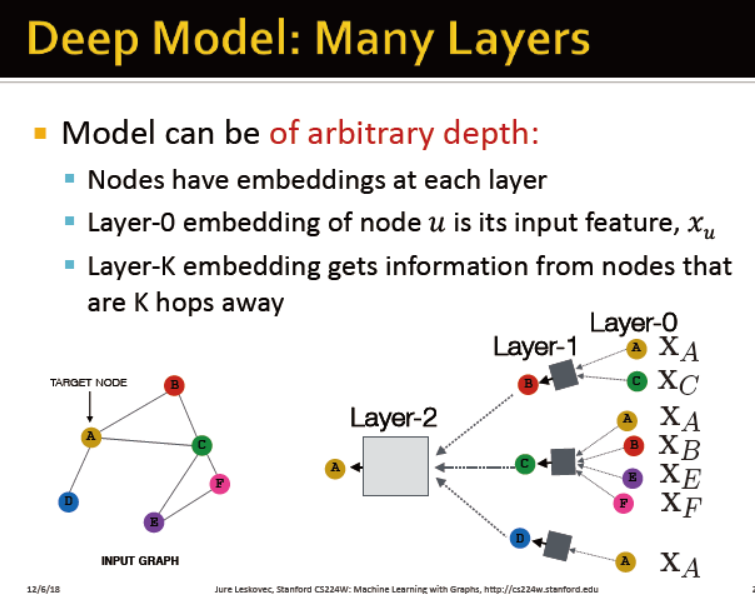
深度模型:多层结构
模型可以是任意深度的:
节点在每一层都有embedding
第0层的embedding是输入特征x
第k层的embedding得到的信息是通过经过k跳的节点而得
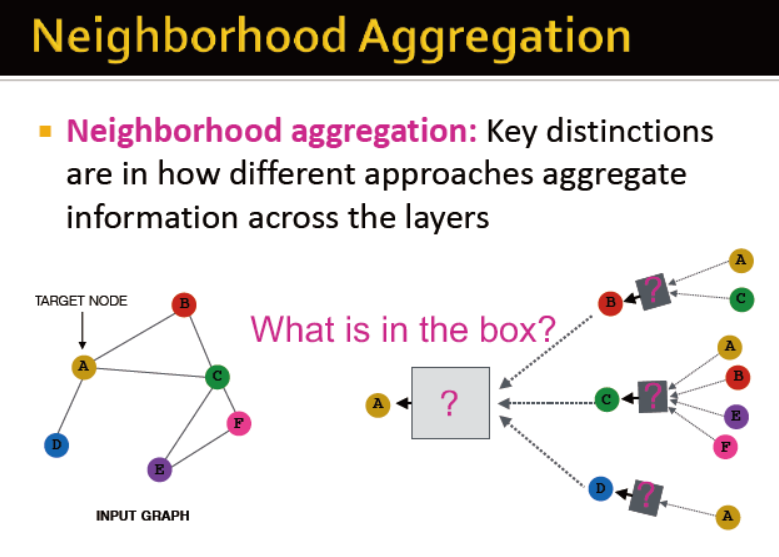
关键的区分在于信息通过不同的层是如何聚合的?
基础的方法:平均+神经网络
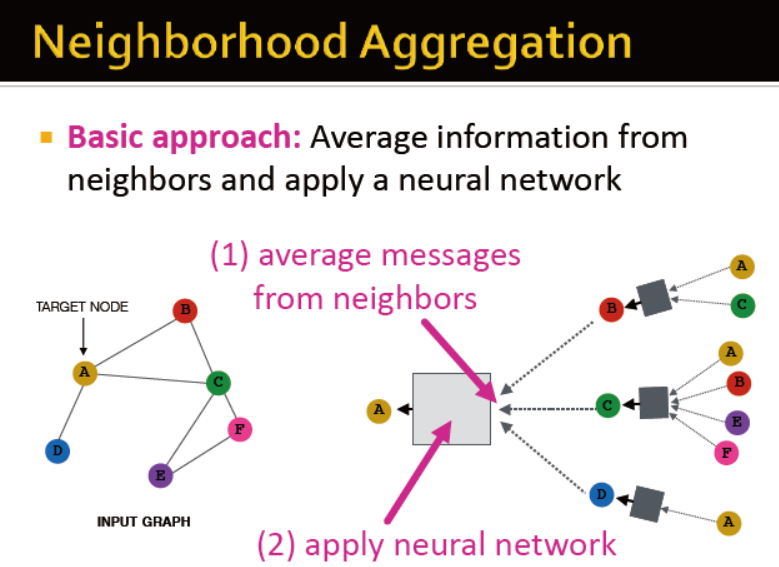
第0层初始化为节点的特征
公式如下

那么如何训练模型?定义损失函数?
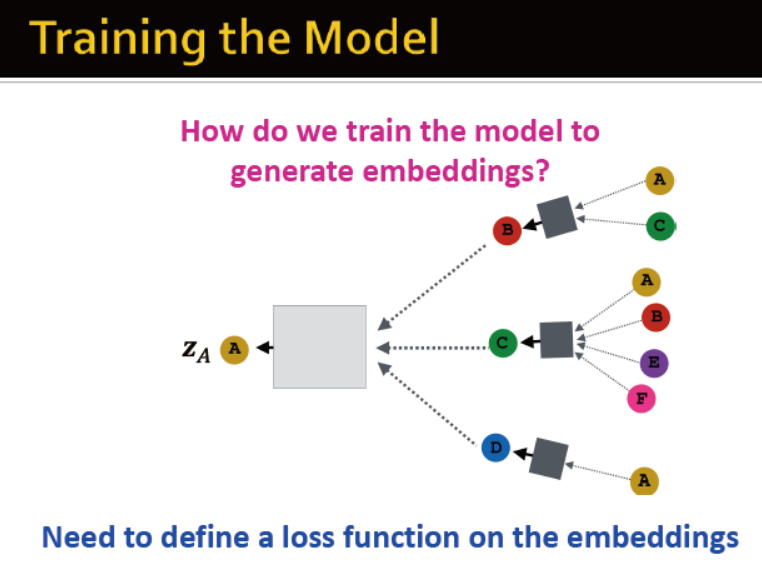

非监督的学习
模型参数
W B
随机梯度下降,训练得到参数
相似的节点有相似的embedding

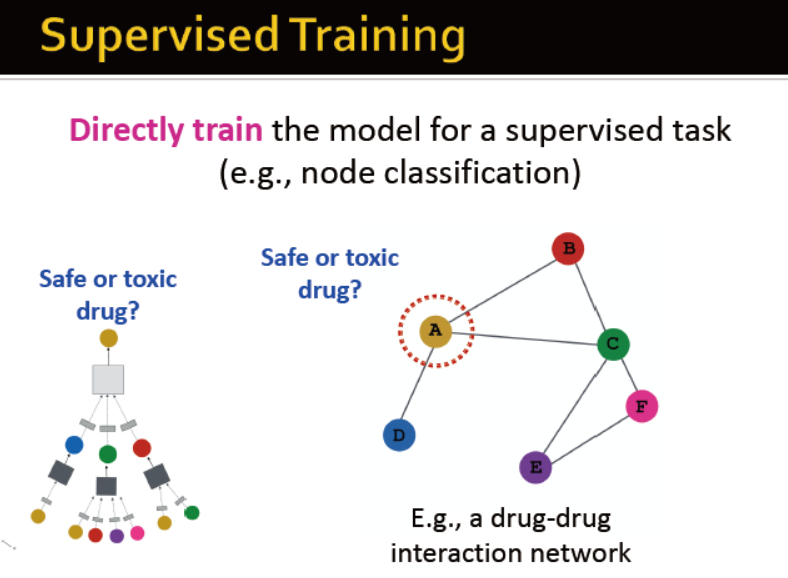
监督学习:训练模型用于节点分类
例如,药品是否有毒

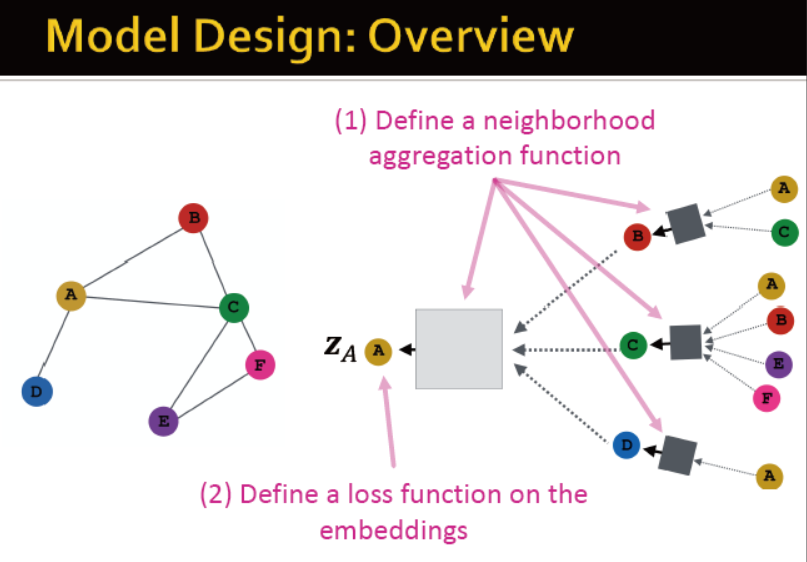
模型设计:
定义邻居聚合函数;定义loss函数;训练:生成节点的embedding

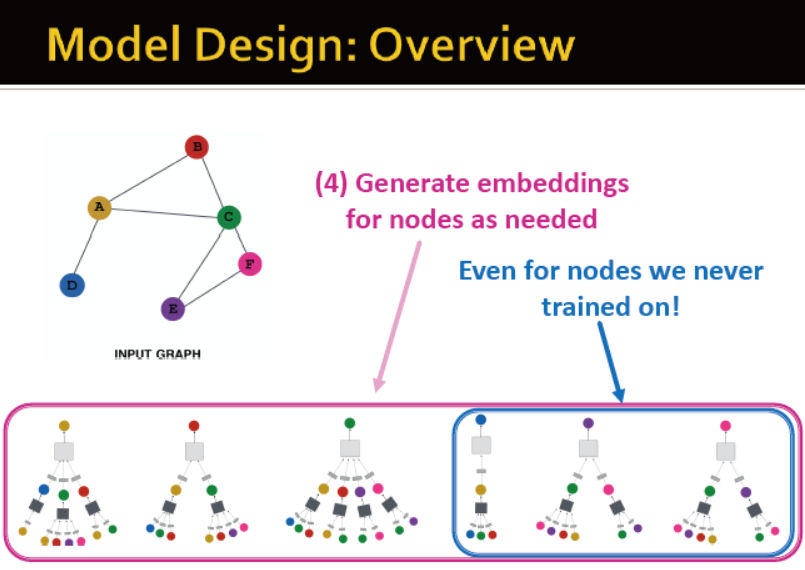
聚合参数是所有节点共享的
因此可为未见过的节点生成embedding;甚至是为相近的全新网络生成embedding


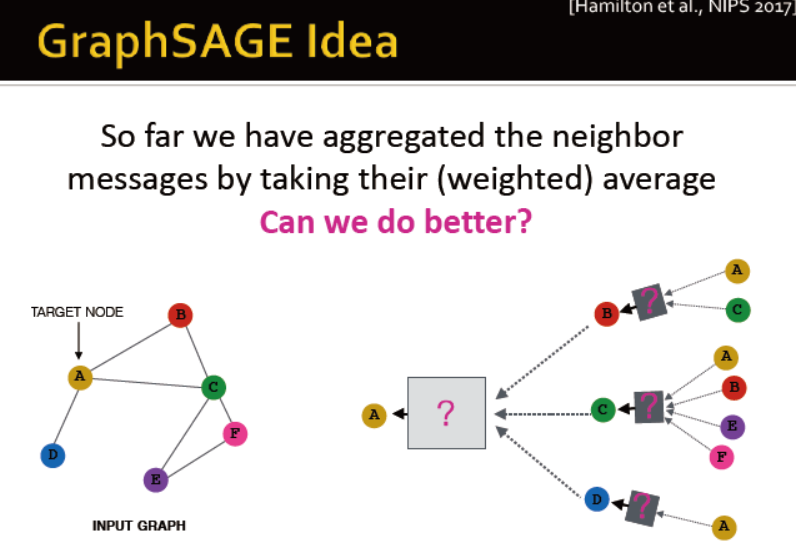
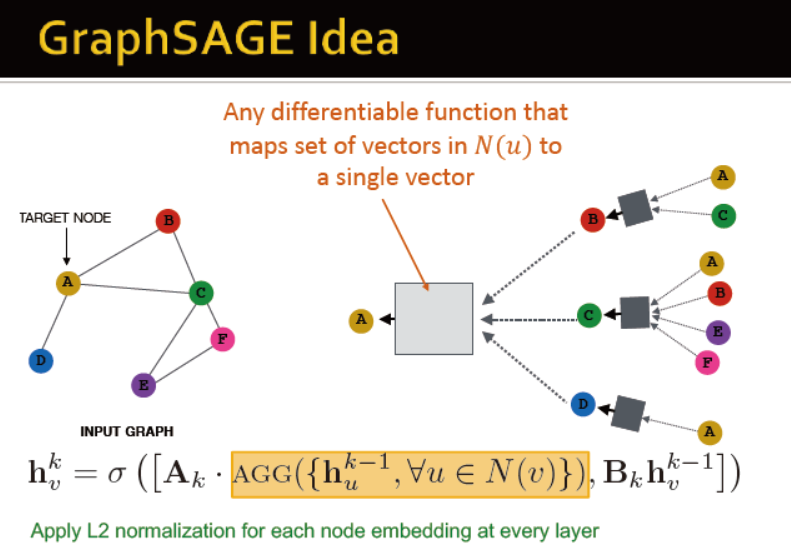
图卷积网络和GraphSAGE

有比平均更好的聚合方法吗?
对每一层的embedding进行L2正则化
不相加而是拼接

3中聚合方法:平均;池化;LSTM

小结:

高效的实现
通过对稀疏矩阵的操作

更多的图卷积网络

Graph Attention Network (GAT)


每个节点的贡献力是否可以使用权重来区分




例子:
引用网络

应用例子

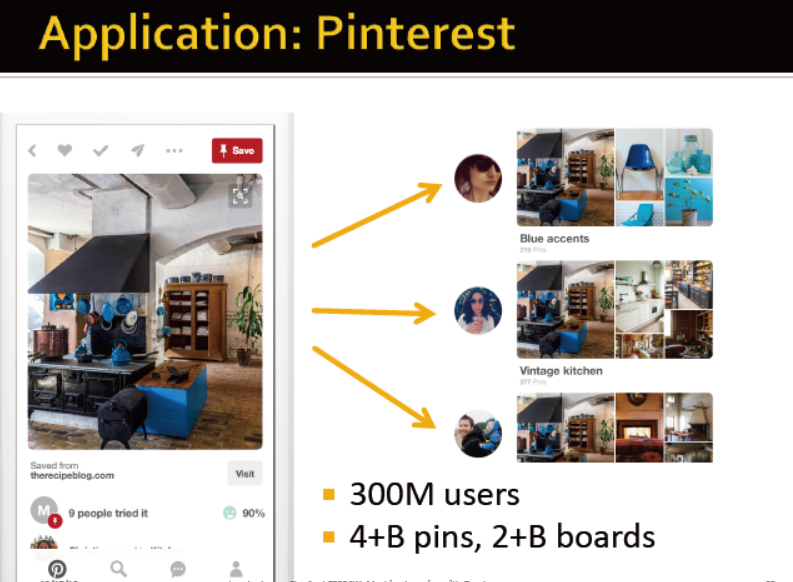
拼趣:Pinterest采用的是瀑布流的形式展现图片内容,无需用户翻页,新的图片不断自动加载在页面底端,让用户不断的发现新的图片。
Pinterest堪称图片版的Twitter,网民可以将感兴趣的图片在Pinterest保存,其他网友可以关注,也可以转发图片。索尼等许多公司也在Pinterest建立了主页,用图片营销旗下的产品和服务。

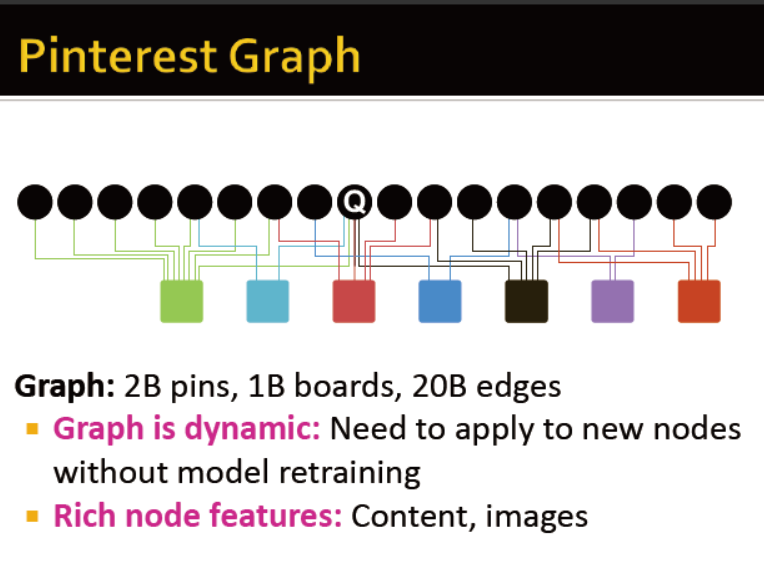
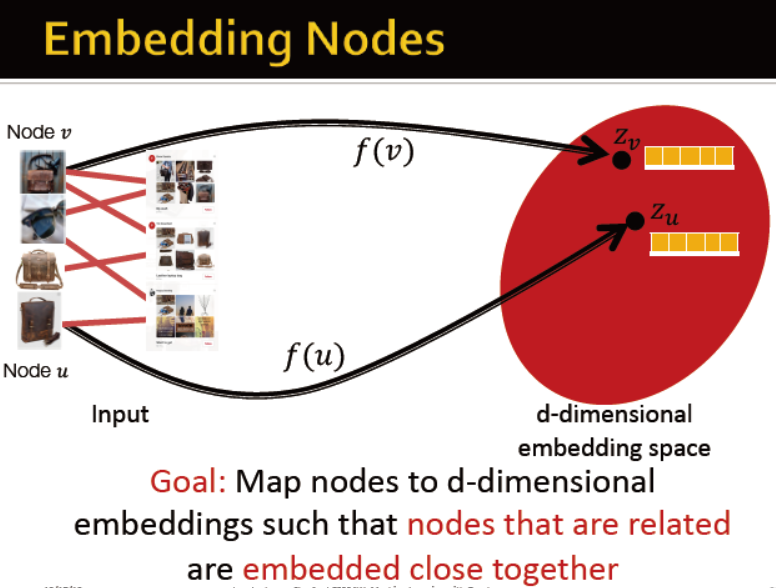
为每个节点生成一个embedding
从相邻的节点借用信息

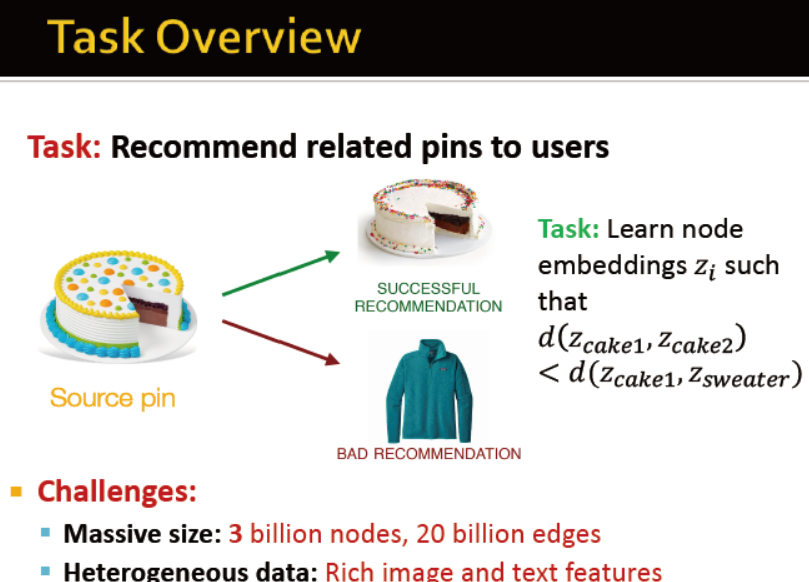
给用户推荐相关的pins




使用小贴士
数据预处理是非常重要的:正则化;变量规模的初始化;网络数据的清洗
训练优化器
relu可以获得较好的成效
输出层不需要激活函数
每一层需要偏置
GCN的层在64或128已经很好了,不需要过深

模型:
在训练集上需要过拟合!!
仔细检查loss函数
仔细检查可视化
