一,需求说明
我们有一个老系统,每天日志量挺大的(有可能是1G左右),比如要搜索某一个订单从生成到关闭完成,其中有很多步骤,而且有时候订单是批量操作的,如果某一个订单出现问题,从大量日志中排查的话,比较困难。1G的日志文件,我们拉下来取分析的话,电脑配置不行会很卡~而且为了找一个订单号要从头到尾,查找一遍,过程十分痛苦。
所以,想到能不能把日志文件拆分部分来分析,当时使用了一下“文件杀手”这个工具,不过我的电脑配置比较差,虽然分成4小部分,依然觉得卡。后来想能不能根据原文件根据订单号把有关系的部分全部展示出来,中间一大批没关系的部分剔除掉就ok!
二,实现思路
首先,我们需要用一个固定大小的集合(队列)来存放我们需要的关键字上下相关部分的内容,特点:先进先出,保持存储的是关键字上下行内容;
然后,定一个afterCount计数关键字后面紧跟的行数,行数达到阀值(关键字行处于队列中间位置)可以输出整个队列并清空;
最后,有几种特殊情况,比如两个关键字行相邻比较近,做法是将前一个关键字在队列中填充空白元素行,使前一个关键字移动到队列中间并全部输出队列,后一个关键字继续放到队列中;
三,代码部分
固定长度队列
package utils.queue; import java.util.Collection; import java.util.Iterator; import java.util.LinkedList; import java.util.Queue; /** * 固定长度队列 * * @author gary */ public class LimitQueue<E> implements Queue<E> { //队列长度 private int limit; Queue<E> queue = new LinkedList<E>(); public LimitQueue(int limit) { this.limit = limit; } /** * 入队 * * @param e */ @Override public boolean offer(E e) { if (queue.size() >= limit) { //如果超出长度,入队时,先出队 queue.poll(); } return queue.offer(e); } /** * 出队 * * @return */ @Override public E poll() { return queue.poll(); } /** * 获取队列 * * @return */ public Queue<E> getQueue() { return queue; } /** * 获取限制大小 * * @return */ public int getLimit() { return limit; } @Override public boolean add(E e) { return queue.add(e); } @Override public E element() { return queue.element(); } @Override public E peek() { return queue.peek(); } @Override public boolean isEmpty() { return queue.size() == 0 ? true : false; } @Override public int size() { return queue.size(); } @Override public E remove() { return queue.remove(); } @Override public boolean addAll(Collection<? extends E> c) { return queue.addAll(c); } @Override public void clear() { queue.clear(); } @Override public boolean contains(Object o) { return queue.contains(o); } @Override public boolean containsAll(Collection<?> c) { return queue.containsAll(c); } @Override public Iterator<E> iterator() { return queue.iterator(); } @Override public boolean remove(Object o) { return queue.remove(o); } @Override public boolean removeAll(Collection<?> c) { return queue.removeAll(c); } @Override public boolean retainAll(Collection<?> c) { return queue.retainAll(c); } @Override public Object[] toArray() { return queue.toArray(); } @Override public <T> T[] toArray(T[] a) { return queue.toArray(a); } }
队列写入到新文件
public static void writeDealInfo(String newFile, LimitQueue<String> allQueue) { try { FileWriter fw = new FileWriter(newFile, true); //队列已满 写入 for (String item : allQueue) { if (item != null) { // writeDealInfo(item, newFile); //遍历写入新文件 fw.write(item + " "); } } allQueue.clear(); //达到lqueue的大小后,清空一下lqueue fw.close(); } catch (Exception e) { System.out.println("书写日志发生错误:" + e.toString()); } }
具体逻辑
public static void getFile(String srcFile, String newFile, Integer queueSize, String search) throws IOException { FileInputStream inputStream = new FileInputStream(srcFile); //设置inputStreamReader的构造方法并创建对象设置编码方式为gbk //BufferedReader bufferedReader = new BufferedReader(new InputStreamReader(inputStream, "gbk")); BufferedReader bufferedReader = new BufferedReader(new InputStreamReader(inputStream, "utf-8")); String str = null; //新建一个指定大小的队列,用来存储指定 int allQueueSize = queueSize * 2 + 1; LimitQueue<String> allQueue = new LimitQueue<>(allQueueSize); //大的queue //计行器 int afterCount = 0; //用于统计关键字行后面紧跟的添加到queue中的行数, boolean hasKey = false; //默认队列中没有关键字的行 while ((str = bufferedReader.readLine()) != null) { allQueue.offer(str); //前置将当前行加入queue,(这里不用管前面有多少个只用管关键字后面是否满足20个) //1.判断是否包含关键字, if (str.indexOf(search) > -1) { // 这里存在可能将前面一大堆都输出情况,比如队列是2*20+1,如果队列前40个都没有关键字,41个有,此时afterCount为0,强行塞入20个空串到队列中来保持前后20行数据 //这里要将队列中之前存在的关键字行前后的数据输出 if (hasKey) { if (afterCount < queueSize) { //如果队列中关键字后面行数不够,添加空行 addBlank(allQueue, (queueSize - afterCount)); } //输出大队列 writeDealInfo(newFile, allQueue); } hasKey = true; afterCount = 0;//归0 } else { //不包含关键字 if (hasKey) { //如果队列中有关键字才能计数加1 afterCount++; } } //判断afterCount是否=20,输出 if (afterCount == queueSize) { writeDealInfo(newFile, allQueue); //输出大队列 afterCount = 0;//归0 hasKey = false; } } //关流 inputStream.close(); bufferedReader.close(); } //给队列添加count个空串元素,直到afterCount=阀值 private static void addBlank(LimitQueue<String> allQueue, int n) { while (n > 0) { allQueue.add(null); n--; } }
测试代码
@Test public void test1() throws IOException { String srcFile = "TestLog.txt"; //原日志文件 String newFile = "TestLogNew.txt"; //搜索出来的关键字行 Integer queueSize = 3; //表示截取 搜索的关键字-前后3行-的文本信息 String search = "AA"; //关键字 getFile(srcFile, newFile, queueSize, search); }
原日志文本样式 TestLog.txt(红色部分是需要截取出来的关键字行)
1 2 3 AA 5 6 AA 8 9 10 11 12 13 14 AA 16 17 18 19 20 21 22 23 24
测试结果:
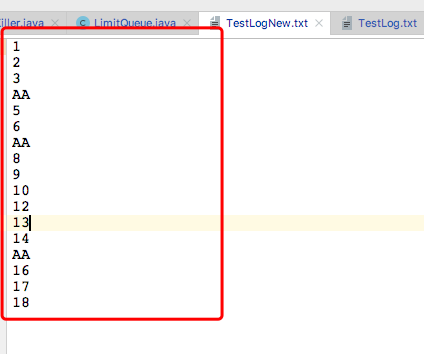
四,总结
1.多学习,从问题提出到我现在解决问题大概有几个月时间,最近一直忙于软考,从中也学习到很多解决问题的方法,比如复杂问题可以化繁为简。
2.多思考,上面的实现代码,我个人觉得可能有要优化的部分,特别是关于IO操作部分。
3.多动手,我曾将这个问题抛出给一个同学(Java),问问他能不能实现,他表示这个很麻烦,不愿意动手~ 然而个人能力的提升很重要的就是自己动手和积累!
4.上面的代码是用JAVA实现的,如果其他语言的效率更高可以试一试,比如Python。