1 回顾
上一节我们证明了,当假设空间的大小是M时,可以得到概率上界:
![]()
即,只要训练数据量N足够大,那么训练集上的Ein与真实的预测错误率Eout是PAC(大概率)接近的。
但是,我们上面的理论只有在假设空间大小有限时才成立,如果假设空间无限大,右边的概率上界就会变成无限大。
事实上,右边的边界是一个比较弱的边界,这一节我们要找出一个更强的边界,来证明我们的机器学习算法对于假设空间无限大的情形仍然是可行的。我们将会用一个m来代替大M,并且证明当假设空间具有break point时,m具有N的多项式级别的上界。
2 成长函数
对于一组给定的训练集x1,x2,...,xN。定义函数H(x1,x2,......,xN),表示使用假设空间H里面的假设函数h,最多能把训练集划分成多少种圈圈叉叉组合(即产生多少种Dichotomy,最大是2^N)。
例如,假设空间是平面上的所有线,训练数据集是平面上的N个点,则有:
N = 1 时,有2种划分方式:

N = 2时,有4种划分方式:

N = 3 时, 有8种划分方式:

N = 4时,有14种划分方式(因为有两种是不可能用一条直线划分出来的):

…………
另外,划分数与训练集有关,(例如N=3时,如果三个点共线,那么有两种划分就不可能产生,因此只有6种划分而不是8种):

为了排除对于训练数据的依赖性,我们定义成长函数:

因此,成长函数的意义就是:使用假设空间H, 最多有多少种对训练集(大小为N)的划分方式。成长函数只与两个因素有关:训练集的大小N,假设空间的类型H。
下面列举了几种假设空间的成长函数:

3 break point
这里我们定义break point。所谓break point,就是指当训练集的大小为k时,成长函数满足:
![]()
即假设空间所不能shatter的训练集容量。
容易想到,如果k是break point,那么k + 1, k + 2....也是break point。
4 成长函数的上界
由于第一个break point会对后面的成长函数有所限制,于是我们定义上界函数B(N,k),表示在第一个break point是k的限制下,成长函数mH(N)的最大可能值:

现在我们开始推导这个上界函数的上界:
首先,B(N,k)产生的Dichotomy可以分为两种类型,一种是前N-1个点成对的出现,一种是前N-1个点只出现一次:
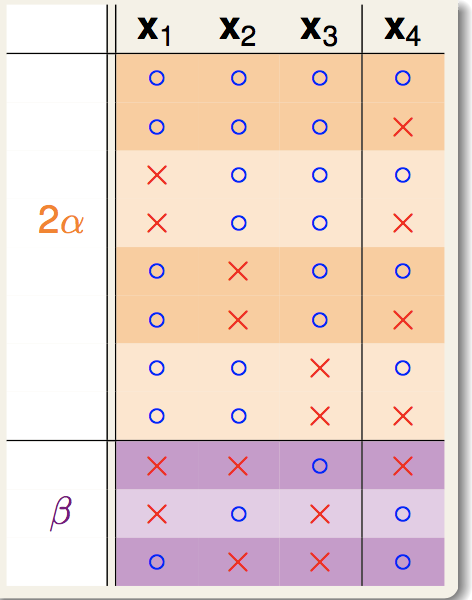
因此显然有:
![]()
然后,对于前N-1个点在这里产生的所有情况:
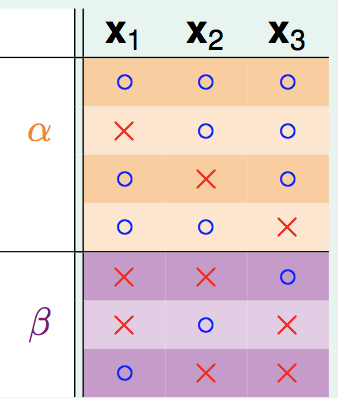
显然这里的个数就是α+β,显然,这前N-1个点产生的Dichotomy数仍然要受限于break point是k这个前提,因此:
![]()
然后,对于成对出现的Dichotomy的前N-1个点:

我们可以说,这里的前N-1个点将会受限于break point是k-1。反证法:如果这里有k-1个点是能够shatter的,那么配合上我们的第N个点,就能找出k个点能shatter,这与B(N,k)的定义就矛盾了。因此我们有:
![]()
综合上面,我们有:

利用这个递推关系以及边界情形,我们可以用数学归纳法简单证明得到(事实上可以证明下面是等号关系):

因此成长函数具有多项式级别的上界。
5 VC-Bound
这里我们不涉及严格的数学证明,而是用一种通俗化的方法来引出VC-Bound。也就是如何用m来替换M。
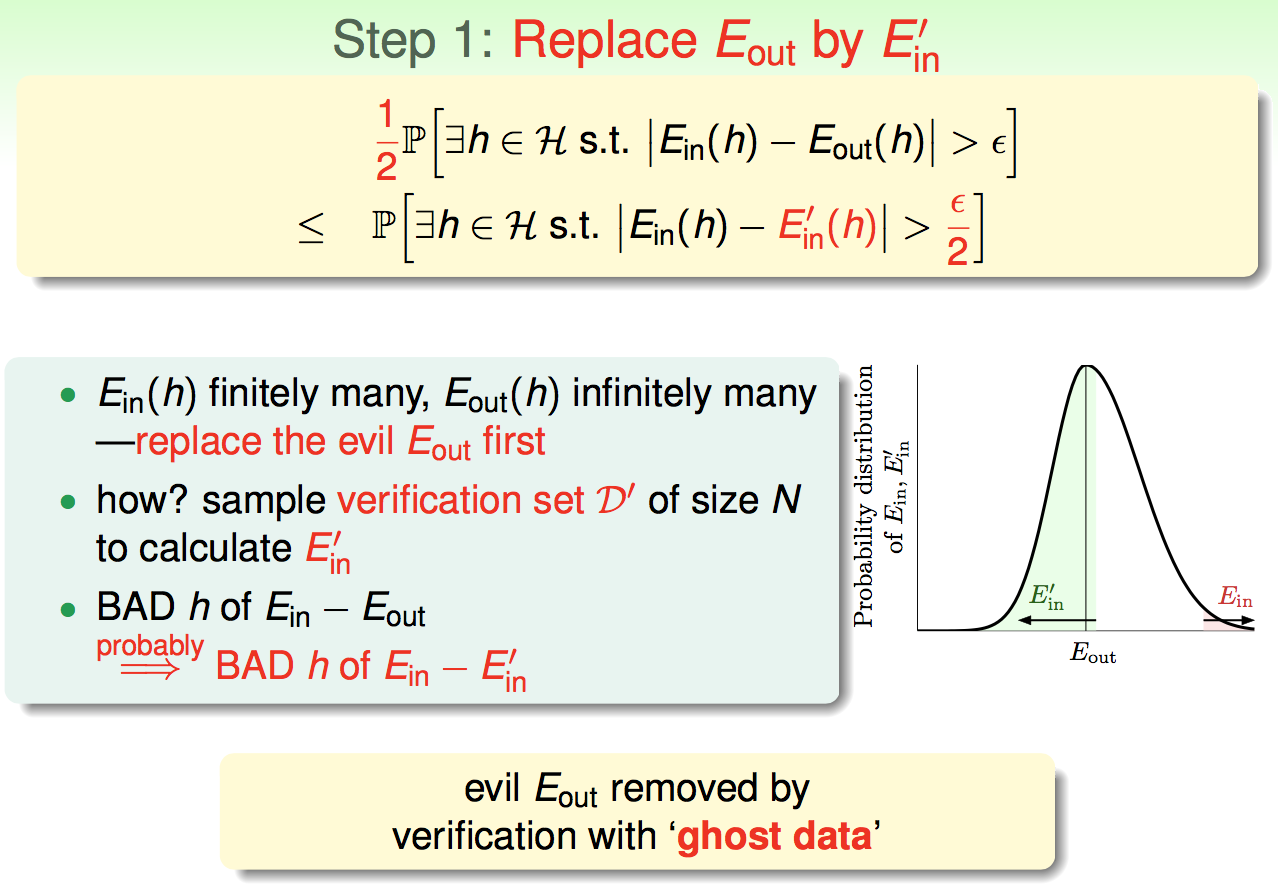
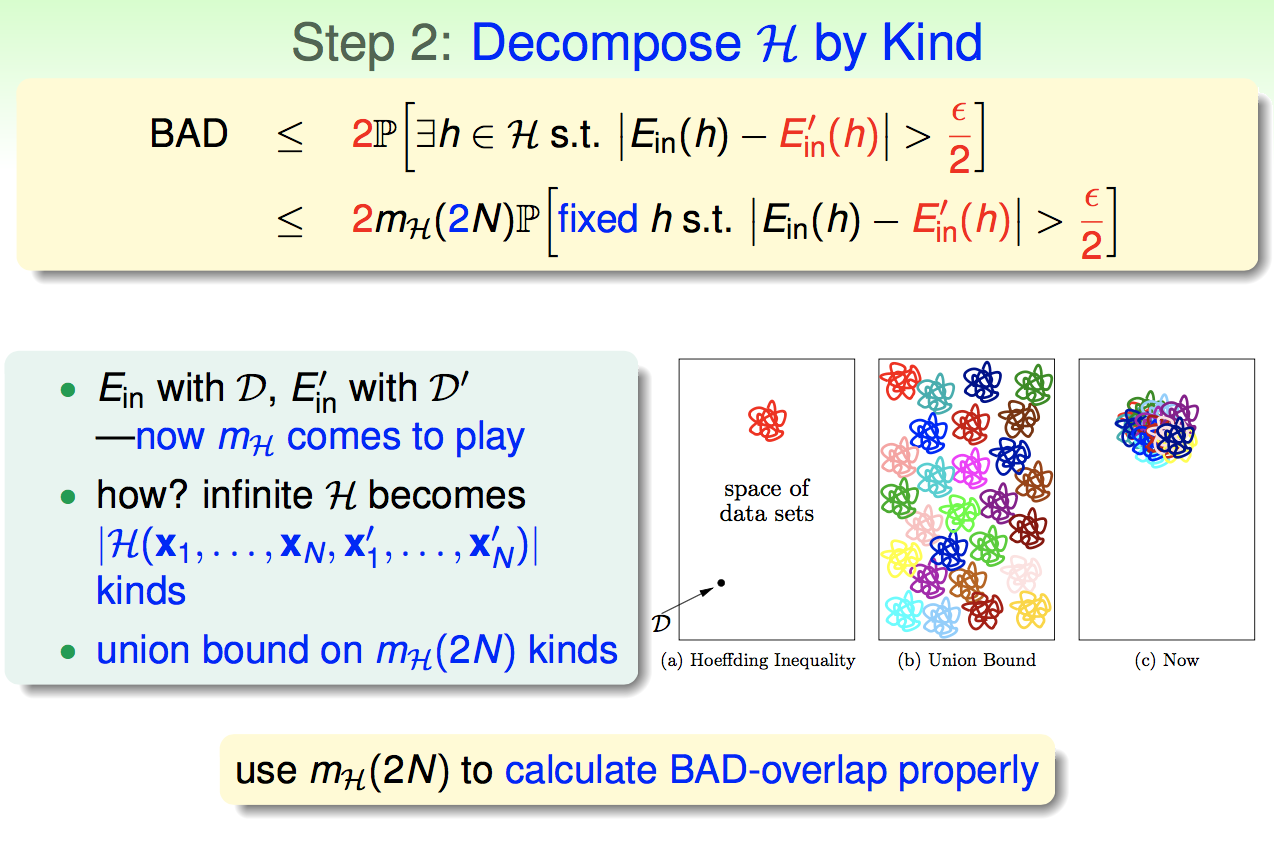

于是我们就得到了机器学习问题的PAC概率上界,称为VC-Bound:

因此我们得到了更强的边界,当右边的成长函数具有break point时,它的上界是N^k-1级别的,只要我们的N足够大,“存在一个假设函数h使得坏情况发生”这件事的几率就会很小。
6 结论
结论:当假设空间的成长函数具有break point时,只要N足够大,我们能PAC地保证训练集是一个好的训练集,所有h在上面的Ein和Eout都是近似的,算法可以对这些h做自由选择。也就是机器学习算法确实是能work的。
通俗的说,机器学习能work的条件:
1 好的假设空间。使得成长函数具有break point。
2 好的训练数据集。使得N足够大。
3 好的算法。使得我们能选择在训练集上表现好的h。
4 好的运气。因为还是有一定小概率会发生坏情况。