前期已经实现通过kettle将车辆定位数据从oracle增量同步入到hbase里,运行了一段时间还算稳定。但是kettle毕竟跟cdh是两套体系,而cdh里自带了streamsets,是其体系下“正牌”etl工具。考虑到以后都通过cdh来管理维护更方便,决定尝试通过streamsets来实现数据etl。
由于车辆定位数据在oracle里有,在kafka里也有,考虑到以后更加通用性的方式以及不对源系统数据库造成影响,这次打算从kafka里获取数据存入hbase。
进入cdh的streamsets配置界面,增加一个pipeline,配置如下3个组件:

1、kafka consumer:
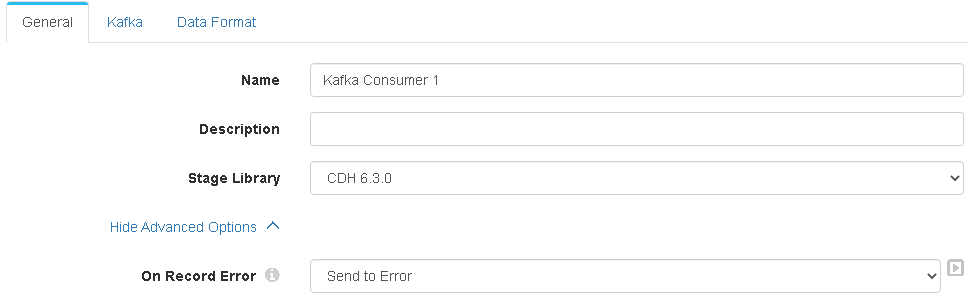
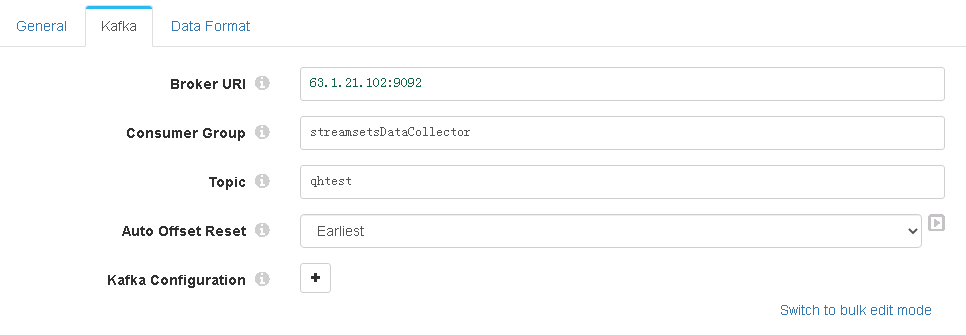
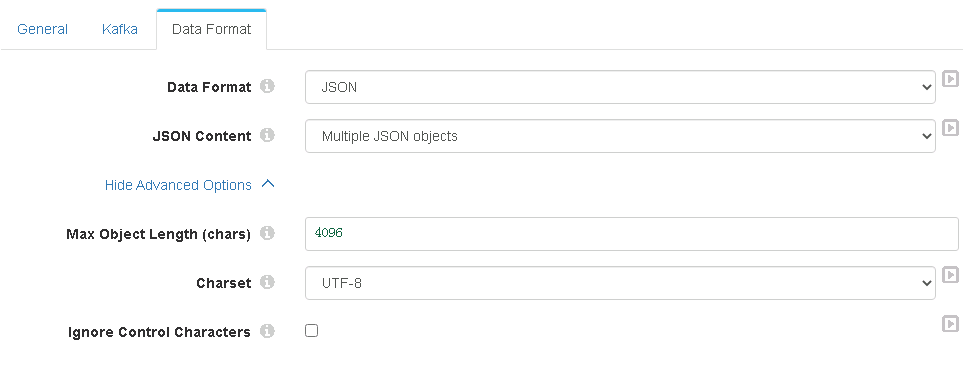
要注意的是 Dataformat选择的是json,这个是因为kafka的生产者在往kafka里插入消息的时候,数据格式就是json。其他没有什么特别注意的点。
2、JavaScript evaluator:

JavaScript evaluator主要是用来在入hbase前,做一些数据的加工处理的。我们入到hbase里的rowkey是由3个字段拼接而成的,所以需要预处理一下。我这里使用了一个存在kafka里,但是不需要入到hbase里的字段ptbm,用它来临时存储一下拼接后的rowkey值(其实本来没打算增加这组件的,因为在后面的hbase组件里没找到设置拼接字段的地方,所以才加了这个组件:P)。
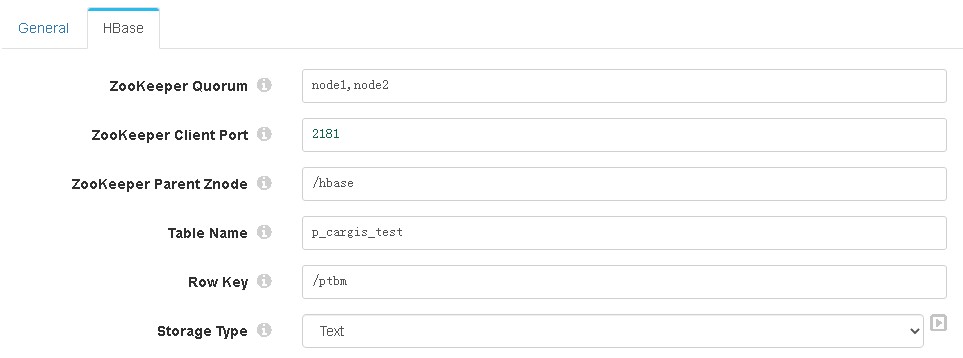
3、hbase:
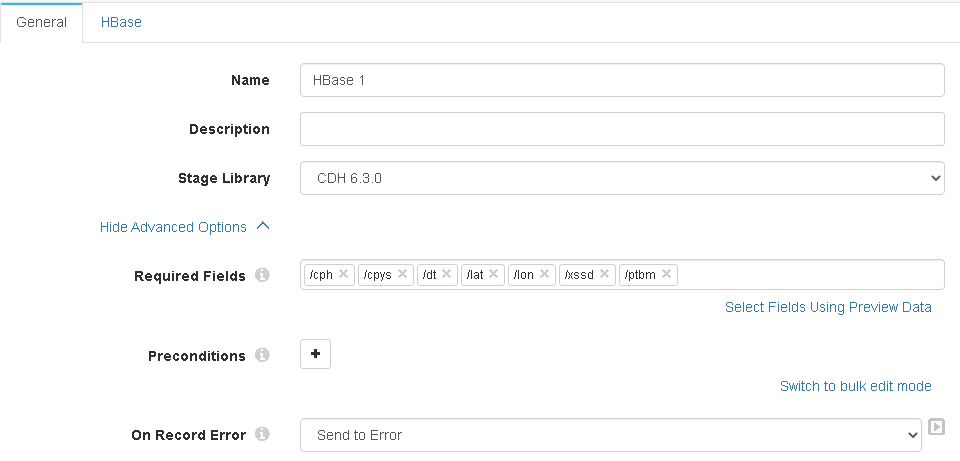
hbase组件有几个地方要说明一下:
——General选项卡里的required fields,需要通过“select fields using preview data”选择一下,否则后面的rowkey、fields path等字段设置不起效,在运行中会出错“Missing row key field '/ptbm' in record”错误。网上有帖子说rowkey要写成“/Data/xxxx”的形式,但测试无效,不知是不是版本的问题。
——Hbase选项卡中的Table name,要在hbase里预先创建好。
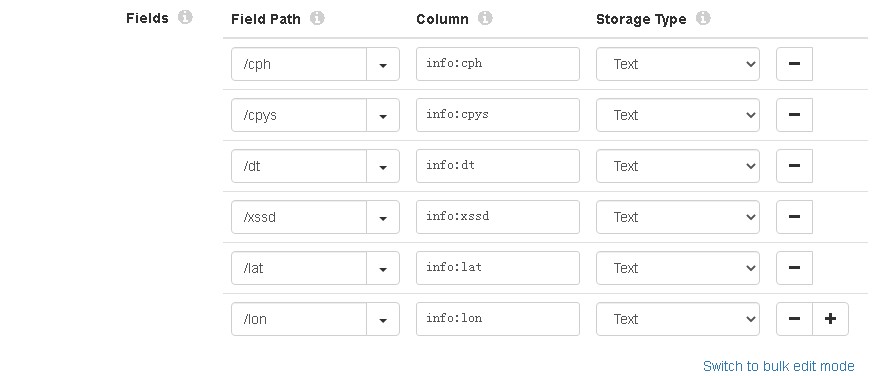
——Rowkey、Fields path字段需要带上斜杠'/',其实就是跟required fields里的格式一直就好。
——Column字段要带上族名称,如“info:cph”。
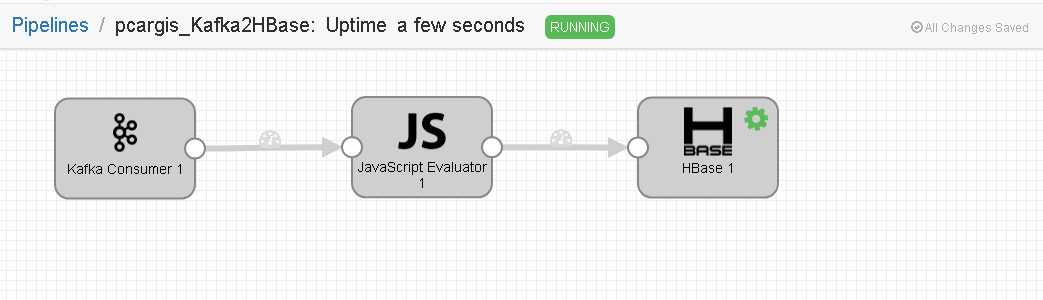
没问题就可以run起来了。感觉入库效率比kettle要高(显示1秒钟入库约900条,而kettle约650~700条)。
待解决:
观察一段时间发现hbase似乎支撑不住数据入库的压力,30分钟后集群挂了...看来hbase的配置还需要调整一下。应该跟streamsets无关了。暂未找到原因,先把streamsets停了。
补充:查看日志提示内存溢出。去配置里看了一下Hbase默认配置的RegionServer的内存大小只有1G。改成了32G,跑了一天很稳定,没问题了。

