一、 Collection与Map继承结构图
Collection继承结构图
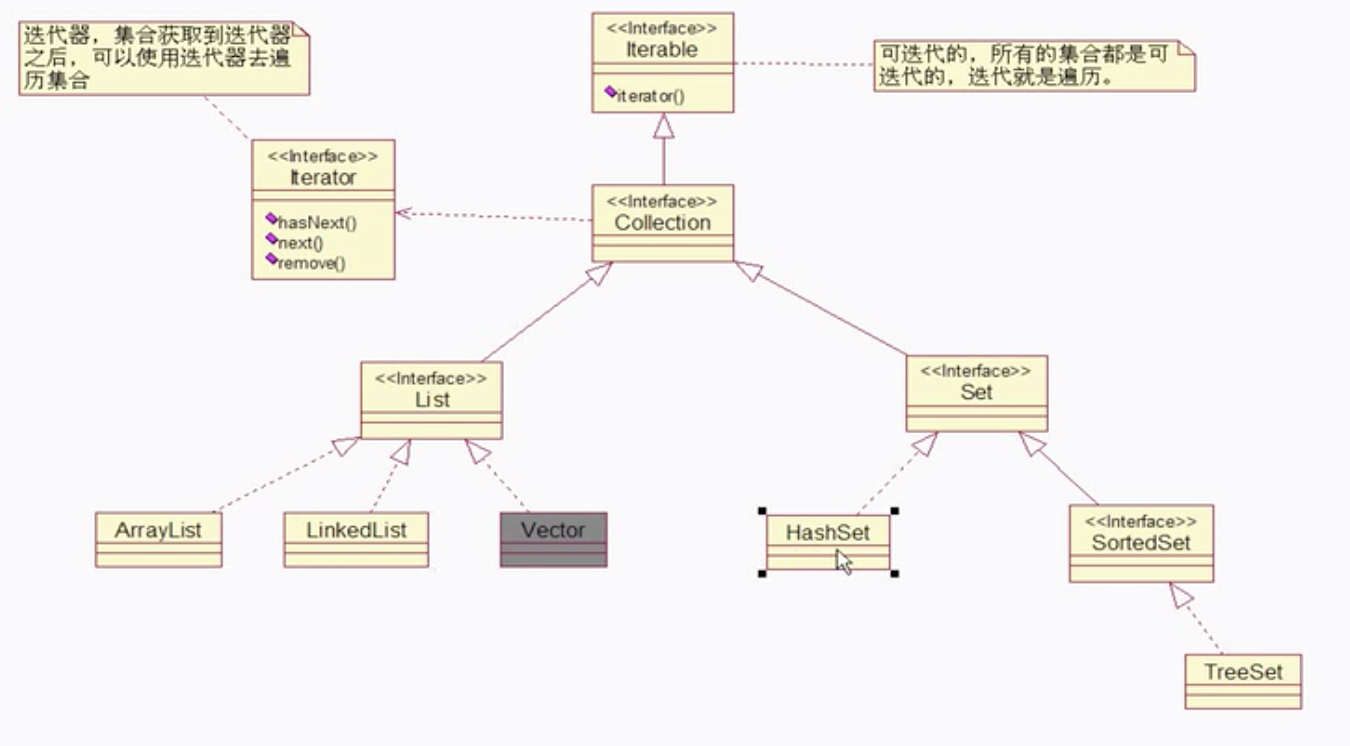
实现Collection接口的类只能存储引用类型!所以set.add(10)会有自动装箱的过程,把int 转成 Integer类型。
类:
- ArrayList 底层数组
- LinkedList 底层双向链表
- (Vector 底层与ArrayList相同,但是线程安全的。但由于在多线程效率低,现很少使用,我们也一般不使用自身的机制来保证线程安全。)
- HashSet 底层是哈希表/散列表
- TreeSet
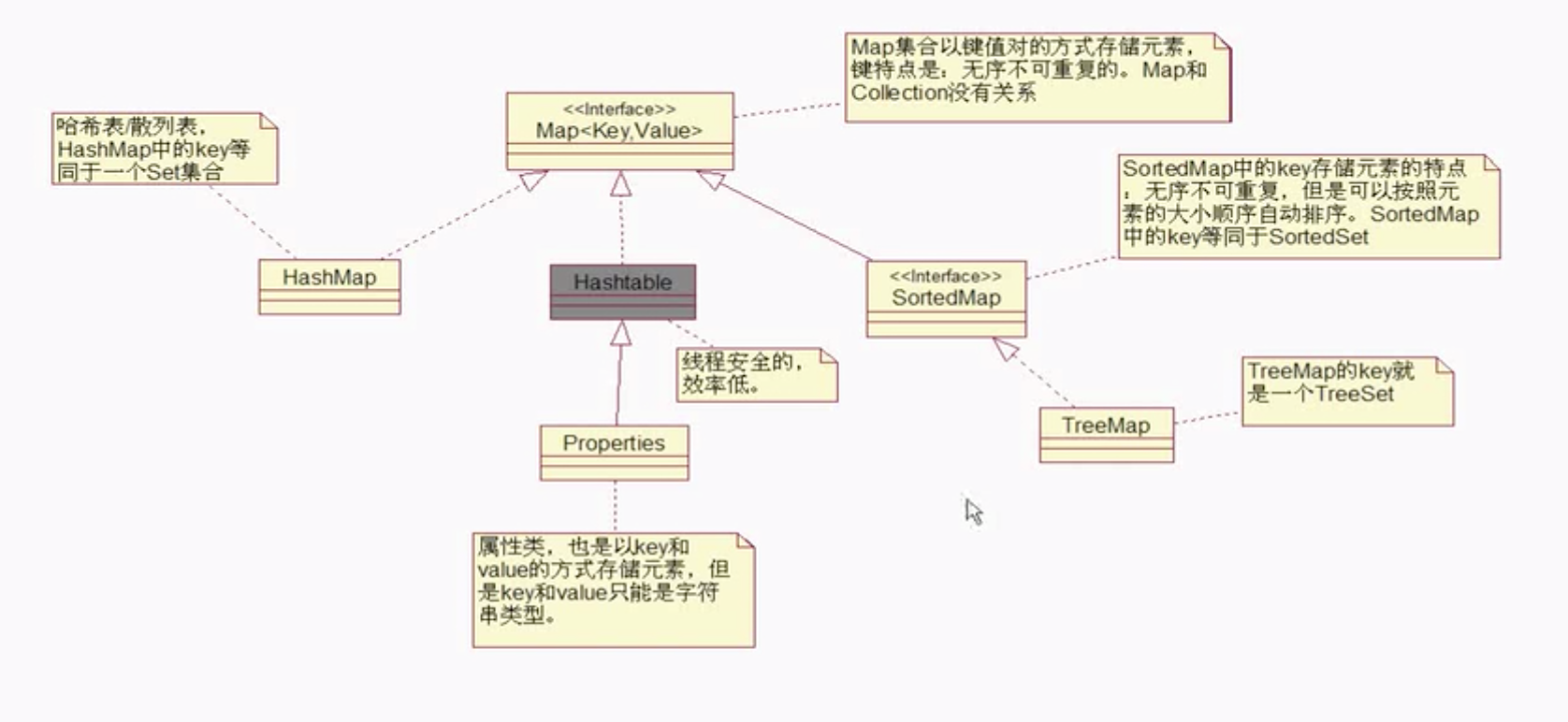
Map继承结构图
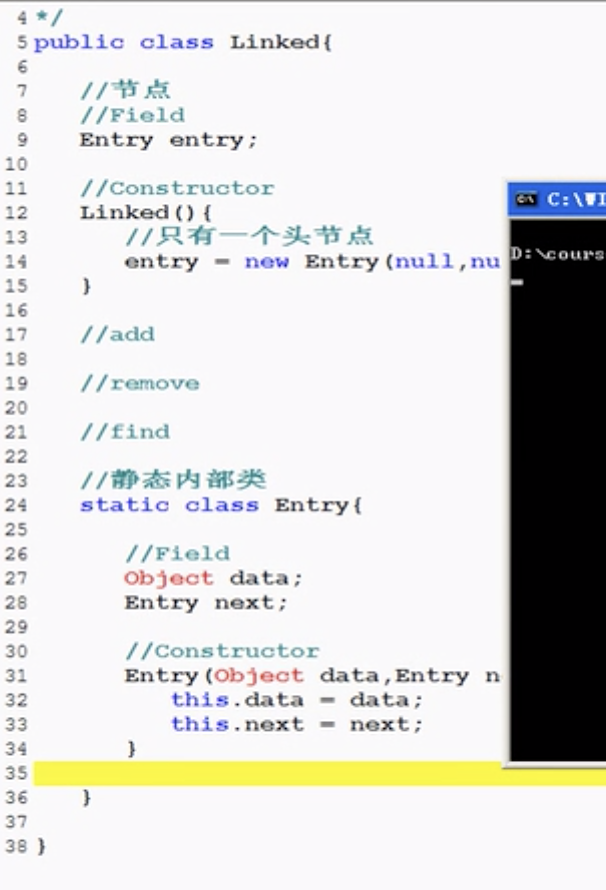
Java实现链表

二、 Collection接口的方法

1 iterator
关于iterator
- Java中的iterator完全不同于C++中的iterator:C++中迭代器可以不需要查找操作就进行位置变更,但Java中查找操作和位置变更是紧密相连的,在执行查找操作的同时迭代器的位置随之移动。
- 因此应该认为Java迭代器是位于两个元素之间。调用next时,迭代器就越过下一个元素,并返回越过的元素的引用。
格式:
Iterator<Integer> it=c.iterator();
//用迭代器遍历
while(it.hasNext()) {
Object elm=it2.next();
System.out.println(elm);
}
2 contains && 放在集合中的类必须要重写equals方法。
- 原因:若不重写equals方法,以下的c.contains(s2)会输出false,contains调equals方法时比较的是两个对象的内存地址。这不符合业务逻辑,所以要在累中重写equals方法。
Collection<Student> c=new ArrayList<Student>();
Student s=new Student(10,"gaga");
c.add(s);
Student s2=new Student(10,"gaga");
System.out.println(c.contains(s));
System.out.println(c.contains(s2));
- 重写equals方法格式:
//重写equals方法
public boolean equals(Object ob) {
if(this==ob) {
return true;
}
if(ob instanceof Student) {
Student s=(Student)ob;
if(this.no==s.no&&this.name==s.name) {
return true;
}
}
return false;
}
3 it.remove()
- 使用迭代器的remove()函数可以边遍历边删除,建议使用;而使用集合的remove()函数会抛异常,不建议使用。
- 例子
while(it.hasNext()) {
Object sTemp=it.next();
it.remove();
}
三、 List
- List特有方法
get(idx),add(idx,elem) - List是有序的,故可以通过下标访问。
- ArrayList底层是数组,LinkedList底层是双向链表。
- ArrayList底层默认初始化容量=10,扩容后容量是原容量的1.5倍。
Vector底层默认初始化容量=10,扩容后容量是原容量的2倍。
故为了优化ArrayList和Vector,建议在创建集合时指定初始容量,以尽量减少扩容操作,扩容需要数组拷贝,很耗内存。
四、 hashSet
hashSet底层是hashmap,相当于hashmap的key的部分,hashmap是由散列表/哈希表实现。
hashSet和hashMap初始容量是16,默认加载因子是0.75,即元素填满了0.75就开始扩容。
1 【散列表】
- 散列表是元素是单向链表的数组。查询和插入删除操作的效率都非常高。
- 每个节点的结构是:
Class Entry{
Object key;
Object value;
final int hash;
Entry next;
}
- key要求不可重复,
- final int hash :是key通过【hashCode】方法得到的值再通过【hashfunction】得出的值,代表数组的下标,同一个链表上的节点hash值相同。
- hashmap有用于查找节点的方法:Object get(Object key)
用key计算出hash值,在数组对应链表查找元素。 - hashmap有用于插入节点的方法:void put(Object key,Object value)
若key对应的hash不在数组中(调用key.hashCode方法计算key对应的hash),则在数组尾部加节点;否则,并且链表中不存在该元素(调用key.equals方法),则插入链表;否则,不插入该节点。
hashSet
放入hashSet和heshMap的类必须重写public int hashCode()方法和public boolean equals()方法。
指导思想:hashCode的返回值要尽量分布均匀。
String类是带hashCode()方法的。
五、SortedSet接口下的TreeSet类
无序不可重复,但可以按照元素大小自动排列。
- 第一种实现比较器方法:
**放在TreeSet中的类必须实现java.lang.Compareble接口,实现接口就要实现接口内的全部方法,故要实现public int compareTo(Object o)方法。 - 第二种实现比较器方法:
创建TreeSet集合的时候提供一个比较器,SortedSet products=new treeSet(new productsComparator()),其中productsComparator类是自己实现的Comparator接口。
六、Map 中的常用方法。(略,需要的话查)
-
map中的key重复,则value覆盖。
-
map中的key需要重写hashCode 和 equals 方法。
-
HashMap继承Map类
-
HashMap默认初始容量16,加载因子0.75.
七、Properties类 属性类
- 继承HashTable类
- HashTable类初始容量11,加载因子0.75。
- Properties Key和value都必须是字符串类型
- 有getProperties(key)方法和setProperties(key,value)方法
八、SortedMap
- 无序不可重复,但存进去的元素按大小自动排列
- 要实现自动排序:法1:key部分要实现Compareble接口(重写其中的compareTo方法)。或法2:单独写一个比较器,可以结合匿名内部类的方式写。
九、集合工具类java.utils.Collections (不是Collection接口)
- sort(List) 函数 :实现排序,若是set可先将set转换成List。
- synchronizedList(ArrayList)函数:将ArrayList转成线程安全的。
十、其他
泛型
- 泛型是JDK 5.0新特性,编译期概念。
- 引入泛型原因:使集合元素类型统一,进而避免遍历时大量类型强制转换。
- ArrayList
list=new ArrayyList (); - 自定义泛型
Class MyClass<T>{
public void m(T t){
System.out.println(t);
}
}
增强for循环
- JDK5.0新特性
for (String name:strs){
System.out.println(name);
}