1.具名组匹配
正则表达式使用圆括号进行组匹配
const RE_DATE = /(d{4})-(d{2})-(d{2})/
const matches = RE_DATE.exec('1995-06-20')
console.log(matches);
上面代码中,正则表达式中有三组圆括号。使用exec()方法,就可以将这三组匹配结果提取出来。
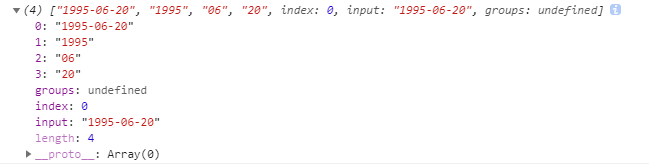
这样的一个问题就是,每一组的匹配含义不容易看出来,而且只能使用数字需要(如:match[0])表示出来,要是组的顺序变了,引用的时候就必须修改序号。
ES2018引入了具名组匹配(Named Capture Group),允许为每一个组匹配指定一个名字,既便于阅读代码,又便于引用。
const RE_DATE = /(?<year>d{4})-(?<month>d{2})-(?<day>d{2})/
const matches = RE_DATE.exec('1995-06-20')
console.log(matches);

上面的代码中:?<xxx>的作用就是为这个匹配定义一个组名,在匹配的groups属性中可以查看到匹配的组名
这里可以使用解构赋值直接从匹配结果上为变量赋值。
2.先行断言 & 后行断言
(1)先行断言
- 先行断言:是x只有在y前面才匹配,必须写成/x(?=y)/。例如,匹配百分号之前的数字,要写成/d+(?=%)/.
- 先行否定断言:是x只有不在y前面才匹配,必须写成/x(?!y)/。例如,只匹配不在百分号之气那的数字,要写成/d+(?!%)/
示例:
const pat1 = /d+(?=%)/ const match1 = pat1.exec('100% of US presidents have been male') console.log(match1); // ['100'] const pat2 = /d+(?!%)/ const match2 = pat2.exec('that’s all 44 of them, aaa 12% bbb') console.log(match2); // ['44']
(2)后行断言
- 后行断言:与先行断言相反,x只有在y后面才匹配,必须写成/(?<=y)x/。例如,只匹配美元符号后面的数字,要写成/(?<=$)d+/.
- 后行否定断言:与先行否定断言相反,x只有不在y后面才匹配,必须写成/(?<!y)x/。例如,只匹配不在美元符号后面的数字,要写成/(?<!$)d+/
示例:
const pat1 = /(?<=$)d+/ const match1 = pat1.exec('Benjamin Franklin is on the $100 bill') console.log(match1); // ['100'] const pat2 = /(?<!$)d+/ const match2 = pat2.exec('it’s is worth about €90') console.log(match2); // ['90']
说明:
- 先行断言与后行断言中()内的部分都不计入返回结果
(3)使用先行断言或后行断言进行字符串替换
示例:
const RE_DOLLAR_PREFIX = /(?<=$)foo/g; '$foo %foo foo'.replace(RE_DOLLAR_PREFIX, 'bar'); // '$bar %foo foo'
上面代码中,只有在$符号后面的foo才会被替换。
后行断言的实现,需要先匹配/(?<=y)x/的x,然后再回到左边,匹配y的部分。这“先右后左”的执行顺序,与所有其他正则操作相反,导致了一些不符合于其的行为。
(1)后行断言的组匹配,与正常情况下结果是不一样的。
/(?<=(d+)(d+))$/.exec('1053') // ["", "1", "053"]
/^(d+)(d+)$/.exec('1053') // ["1053", "105", "3"]
上面代码中,需要捕捉两个组匹配。没有后行断言时,第一个括号是贪婪模式,第二个括号只能捕获一个字符,所以结果是105和3。而后行断言时,由于执行顺序是从右到左,第二个括号是贪婪模式,第一个括号只能捕获一个字符,所以结果是1和053.
(2)后行断言的反斜杠引用,也与通常的顺序相反,必须放在对应的那个括号之前。
/(?<=(o)d1)r/.exec('hodor') // null
/(?<=1d(o))r/.exec('hodor') // ["r", "o"]
上面代码中,如果后行断言的反斜杠引用(1)放在括号的后面,就不会得到匹配结果,必须放在前面才可以。因为后行断言是先从左到右扫描,发现匹配以后再回过头,从右到左完成反斜杠引用。(没懂)