看到之前在csdn 上写的摄像头驱动总结,首先得感谢摄像头驱动这个东西 让我在读书时挣到了一笔生活费!!------------
现在把文章简要拷贝过来,以及去掉之前的代码然后随便扯一下文件的map吧
驱动核心: 将摄像头驱动中的yuv数据map到用户空间,便于访问。read 性能不够!!
原理是:通过mmap将内核太buffer关联到用户空间,DMA拷贝yuv数据到内核buffer,此时应用层直接访问yuv数据!


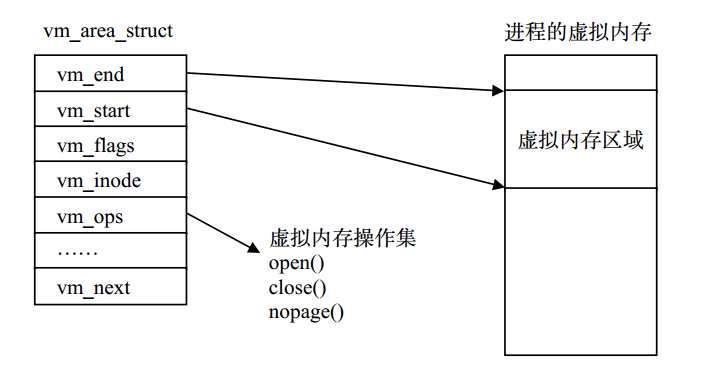
文件物理地址和进程虚拟地址的一一映射关系过程
- 进程在用户空间调用库函数mmap,原型:void *mmap(void *start, size_t length, int prot, int flags, int fd, off_t offset);
- 在当前进程的虚拟地址空间中,寻找一段空闲的满足要求的连续的虚拟地址;
- 为此虚拟区分配一个vm_area_struct结构,接着对这个结构的各个域进行了初始化;
- 将新建的虚拟区结构(vm_area_struct)插入进程的虚拟地址区域链表或树中
- 为映射分配了新的虚拟地址区域后,通过待映射的文件指针,在文件描述符表中找到对应的文件描述符,通过文件描述符,链接到内核“已打开文件集”中该文件的文件结构体(struct file),每个文件结构体维护着和这个已打开文件相关各项信息。
- 通过该文件的文件结构体,链接到file_operations模块,调用内核函数mmap,其原型为:int mmap(struct file *filp, struct vm_area_struct *vma),不同于用户空间库函数。
- 内核mmap函数通过虚拟文件系统inode模块定位到文件磁盘物理地址。
由于此时需要映射的fd 不是文件而是open的设备驱动!所以需要实现驱动的map系统调用!!总不能用文件的mmap吧
目前mmap的系统调用的入口函数都是:do_mmap
最后do_mmap都会调用do_mmap_pgoff
其核心代码为:
1、检测各种参数,具体不看了
2、创建新的vma区域之前先要寻找一块足够大小的空闲区域,所以调用get_unmapped_area函数查找没有映射过的空洞内存区,返回值addr就是这段空洞的起始地址
3、判断是文件映射还是匿名映射,如果是文件映射则赋值inode ;以及各种私有 共享属性设置/检测
4、创建新vma线性区,通过函数mmap_region实现;
- 检测当前映射的addr ---addr+end地址是否已经被映射;遍历该进程已有的vma红黑树,如果找到vma覆盖[addr, end]区域,然后去munmap已有的vma区域
- 是否可以复用以前老旧的VMA线性区;属性不同的区段不能共存于同一逻辑区间VMA,所以如果找不到可用的一样属性的vma 就需要单独建立一个逻辑区间(就相当于 堆栈 线性区不一样)------>也就是将多个属性的地址空间【addr----addr+end】 交给一个VMA管理;减少因为vma导致的slab消耗和虚拟内存的空洞
- vma = kmem_cache_alloc(vm_area_cachep, SLAB_KERNEL);创建一个单独的线性区
5、如果是新创建的vma;也就是不能复用之前的vma;就需要设置vma相关参数
/*初始化vma线性区成员*/ vma->vm_mm = mm; vma->vm_start = addr; vma->vm_end = addr + len; vma->vm_flags = vm_flags; vma->vm_page_prot = vm_get_page_prot(vm_flags); vma->vm_pgoff = pgoff; INIT_LIST_HEAD(&vma->anon_vma_chain);
6、如果是文件映射; error = file->f_op->mmap(file, vma)---------调用文件操作函数集的mmap成员
如果是匿名的话 就调用 对应的shmem_zero_setup 进行映射物理内存等
7、vma_link(mm, vma, prev, rb_link, rb_parent);----------------------------将新建的vma插入到进程地址空间的vma红黑树中,已经做一些计数更新等。
对于文件来说:比如ext2文件,其f_op->mmap 指向了generic_file_mmap
const struct vm_operations_struct generic_file_vm_ops = { .fault = filemap_fault, }; /* This is used for a general mmap of a disk file */ int generic_file_mmap(struct file * file, struct vm_area_struct * vma) { struct address_space *mapping = file->f_mapping; if (!mapping->a_ops->readpage) return -ENOEXEC; file_accessed(file); vma->vm_ops = &generic_file_vm_ops; vma->vm_flags |= VM_CAN_NONLINEAR; return 0; }
mmap映射执行流程
- 检查参数,并根据传入的映射类型设置
vma的flags. - 进程查找其虚拟地址空间,找到一块空闲的满足要求的虚拟地址空间.
- 根据找到的虚拟地址空间初始化
vma. - 设置
vma->vm_file. - 根据文件系统类型,将
vma->vm_ops设为对应的file_operations. - 将
vma插入mm的链表中.
实际上没有映射物理内存, 设置了一个缺页中断函数;当这个区间的一个页面首次受到访问时,会由于见面无映射而发生缺页异常,相应的处理函数是do_no_page()
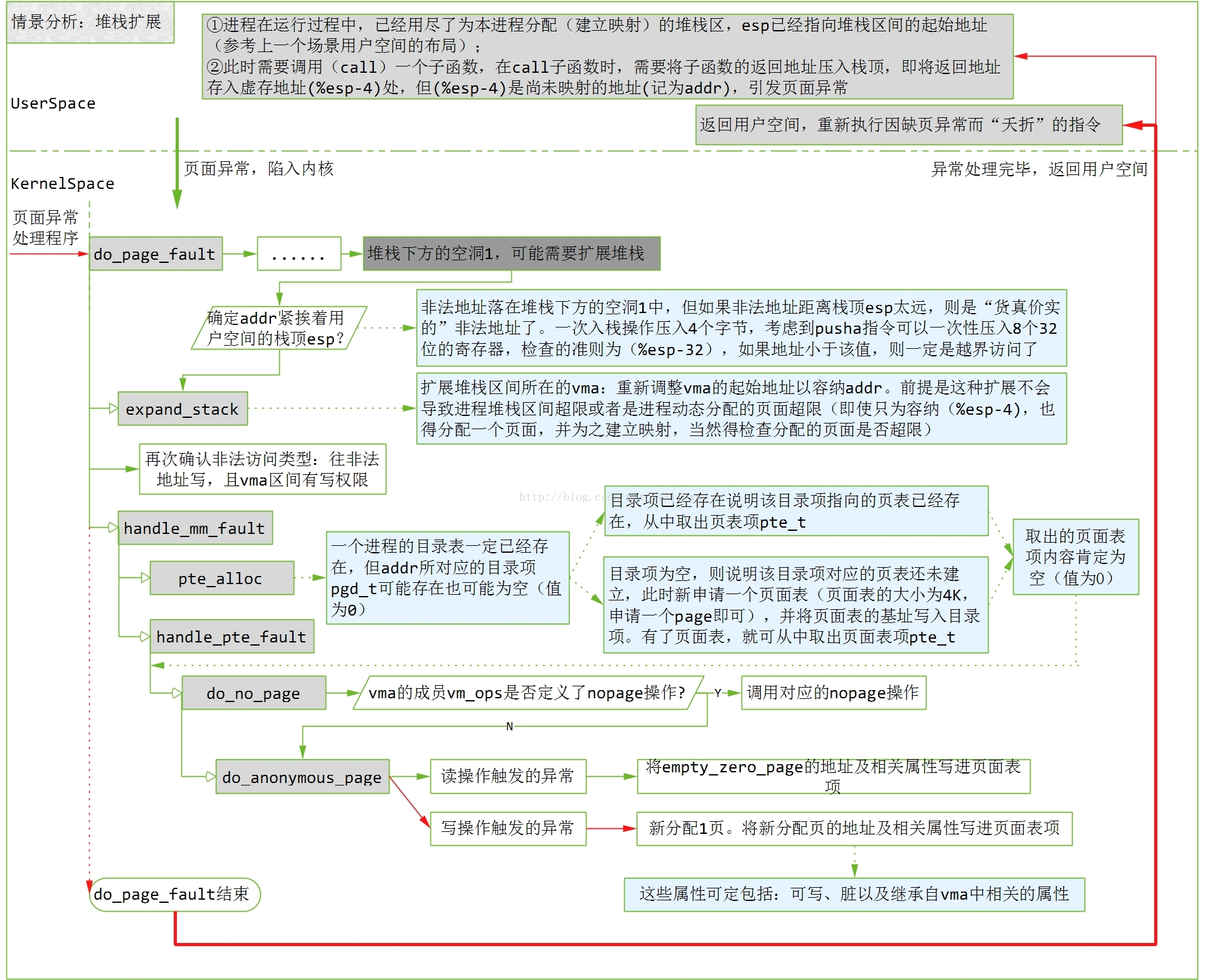
但是由于摄像头mmap肯定是用来缓存读取yuv数据的;何必不在一开始分配虚拟地址的时候就映射好呢?
使用remap_pfn_range一次建立所有页表;
所以 自己实现int (*mmap) (struct file *, struct vm_area_struct *) 函数时,直接调用
ret = remap_pfn_range(vma, vma->vm_start, paddr >> PAGE_SHIFT,
len, vma->vm_page_prot);
int remap_pfn_range(struct vm_area_struct *vma, unsigned long addr,unsigned long pfn, unsigned long size, pgprot_t prot) vma: 虚拟内存区域指针 virt_addr: 虚拟地址的起始值 pfn: 要映射的物理地址所在的物理页帧号,可将物理地址>>PAGE_SHIFT得到。 size: 要映射的区域的大小。 prot: VMA的保护属性。
常规文件操作需要从磁盘到页缓存再到用户主存的两次数据拷贝。而mmap操控文件,只需要从磁盘到用户主存的一次数据拷贝过程。
mmap的关键点是实现了用户空间和内核空间的数据直接交互而省去了空间不同数据不通的繁琐过程。因此mmap效率更高。
设备数据就是:摄像头芯片缓存数据DMA传输到内核空间----map到用户态-
来自:https://leviathan.vip/2019/01/13/mmap%E6%BA%90%E7%A0%81%E5%88%86%E6%9E%90/
unsigned long do_mmap(struct file *file, unsigned long addr, unsigned long len, unsigned long prot, unsigned long flags, vm_flags_t vm_flags, unsigned long pgoff, unsigned long *populate, struct list_head *uf) { struct mm_struct *mm = current->mm; /* 获取该进程的memory descriptor int pkey = 0; *populate = 0; /* 函数对传入的参数进行一系列检查, 假如任一参数出错,都会返回一个errno */ if (!len) return -EINVAL; /* * Does the application expect PROT_READ to imply PROT_EXEC? * * (the exception is when the underlying filesystem is noexec * mounted, in which case we dont add PROT_EXEC.) */ if ((prot & PROT_READ) && (current->personality & READ_IMPLIES_EXEC)) if (!(file && path_noexec(&file->f_path))) prot |= PROT_EXEC; /* force arch specific MAP_FIXED handling in get_unmapped_area */ if (flags & MAP_FIXED_NOREPLACE) flags |= MAP_FIXED; /* 假如没有设置MAP_FIXED标志,且addr小于mmap_min_addr, 因为可以修改addr, 所以就需要将addr设为mmap_min_addr的页对齐后的地址 */ if (!(flags & MAP_FIXED)) addr = round_hint_to_min(addr); /* Careful about overflows.. */ /* 进行Page大小的对齐 */ len = PAGE_ALIGN(len); if (!len) return -ENOMEM; /* offset overflow? */ if ((pgoff + (len >> PAGE_SHIFT)) < pgoff) return -EOVERFLOW; /* Too many mappings? */ /* 判断该进程的地址空间的虚拟区间数量是否超过了限制 */ if (mm->map_count > sysctl_max_map_count) return -ENOMEM; /* Obtain the address to map to. we verify (or select) it and ensure * that it represents a valid section of the address space. */ /* get_unmapped_area从当前进程的用户空间获取一个未被映射区间的起始地址 */ addr = get_unmapped_area(file, addr, len, pgoff, flags); /* 检查addr是否有效 */ if (offset_in_page(addr)) return addr; /* 假如flags设置MAP_FIXED_NOREPLACE,需要对进程的地址空间进行addr的检查. 如果搜索发现存在重合的vma, 返回-EEXIST。 这是MAP_FIXED_NOREPLACE标志所要求的 */ if (flags & MAP_FIXED_NOREPLACE) { struct vm_area_struct *vma = find_vma(mm, addr); if (vma && vma->vm_start < addr + len) return -EEXIST; } if (prot == PROT_EXEC) { pkey = execute_only_pkey(mm); if (pkey < 0) pkey = 0; } /* Do simple checking here so the lower-level routines won't have * to. we assume access permissions have been handled by the open * of the memory object, so we don't do any here. */ vm_flags |= calc_vm_prot_bits(prot, pkey) | calc_vm_flag_bits(flags) | mm->def_flags | VM_MAYREAD | VM_MAYWRITE | VM_MAYEXEC; /* 假如flags设置MAP_LOCKED,即类似于mlock()将申请的地址空间锁定在内存中, 检查是否可以进行lock*/ if (flags & MAP_LOCKED) if (!can_do_mlock()) return -EPERM; if (mlock_future_check(mm, vm_flags, len)) return -EAGAIN; if (file) { /* file指针不为nullptr, 即从文件到虚拟空间的映射 */ struct inode *inode = file_inode(file); /* 获取文件的inode */ unsigned long flags_mask; if (!file_mmap_ok(file, inode, pgoff, len)) return -EOVERFLOW; flags_mask = LEGACY_MAP_MASK | file->f_op->mmap_supported_flags; /* ... 根据标志指定的map种类,把为文件设置的访问权考虑进去。 如果所请求的内存映射是共享可写的,就要检查要映射的文件是为写入而打开的,而不 是以追加模式打开的,还要检查文件上没有上强制锁。 对于任何种类的内存映射,都要检查文件是否为读操作而打开的。 ... */ } else { switch (flags & MAP_TYPE) { case MAP_SHARED: if (vm_flags & (VM_GROWSDOWN|VM_GROWSUP)) return -EINVAL; /* * Ignore pgoff. */ pgoff = 0; vm_flags |= VM_SHARED | VM_MAYSHARE; break; case MAP_PRIVATE: /* * Set pgoff according to addr for anon_vma. */ pgoff = addr >> PAGE_SHIFT; break; default: return -EINVAL; } } /* * Set 'VM_NORESERVE' if we should not account for the * memory use of this mapping. */ if (flags & MAP_NORESERVE) { /* We honor MAP_NORESERVE if allowed to overcommit */ if (sysctl_overcommit_memory != OVERCOMMIT_NEVER) vm_flags |= VM_NORESERVE; /* hugetlb applies strict overcommit unless MAP_NORESERVE */ if (file && is_file_hugepages(file)) vm_flags |= VM_NORESERVE; } addr = mmap_region(file, addr, len, vm_flags, pgoff, uf); if (!IS_ERR_VALUE(addr) && ((vm_flags & VM_LOCKED) || (flags & (MAP_POPULATE | MAP_NONBLOCK)) == MAP_POPULATE)) *populate = len; return addr;
do_mmap()根据用户传入的参数做了一系列的检查,然后根据参数初始化vm_area_struct的标志vm_flags,vma->vm_file = get_file(file)建立文件与vma的映射, mmap_region()负责创建虚拟内存区域:
unsigned long mmap_region(struct file *file, unsigned long addr, unsigned long len, vm_flags_t vm_flags, unsigned long pgoff, struct list_head *uf) { struct mm_struct *mm = current->mm; // 获取该进程的memory descriptor struct vm_area_struct *vma, *prev; int error; struct rb_node **rb_link, *rb_parent; unsigned long charged = 0; /* Check against address space limit. */ /* 检查申请的虚拟内存空间是否超过了限制. */ if (!may_expand_vm(mm, vm_flags, len >> PAGE_SHIFT)) { unsigned long nr_pages; /* * MAP_FIXED may remove pages of mappings that intersects with * requested mapping. Account for the pages it would unmap. */ nr_pages = count_vma_pages_range(mm, addr, addr + len); if (!may_expand_vm(mm, vm_flags, (len >> PAGE_SHIFT) - nr_pages)) return -ENOMEM; } /* 检查[addr, addr+len)的区间是否存在映射空间,假如存在重合的映射空间需要munmap */ while (find_vma_links(mm, addr, addr + len, &prev, &rb_link, &rb_parent)) { if (do_munmap(mm, addr, len, uf)) return -ENOMEM; } /* * Private writable mapping: check memory availability */ if (accountable_mapping(file, vm_flags)) { charged = len >> PAGE_SHIFT; if (security_vm_enough_memory_mm(mm, charged)) return -ENOMEM; vm_flags |= VM_ACCOUNT; } /* 检查是否可以合并[addr, addr+len)区间内的虚拟地址空间vma*/ vma = vma_merge(mm, prev, addr, addr + len, vm_flags, NULL, file, pgoff, NULL, NULL_VM_UFFD_CTX); if (vma) /* 假如合并成功,即使用合并后的vma, 并跳转至out */ goto out; /* * Determine the object being mapped and call the appropriate * specific mapper. the address has already been validated, but * not unmapped, but the maps are removed from the list. */ /* 如果不能和已有的虚拟内存区域合并,通过Memory Descriptor来申请一个vma */ vma = vm_area_alloc(mm); if (!vma) { error = -ENOMEM; goto unacct_error; } /* 初始化vma */ vma->vm_start = addr; vma->vm_end = addr + len; vma->vm_flags = vm_flags; vma->vm_page_prot = vm_get_page_prot(vm_flags); vma->vm_pgoff = pgoff; if (file) { /* 假如指定了文件映射 */ if (vm_flags & VM_DENYWRITE) { /* 映射的文件不允许写入,调用deny_write_accsess(file)排斥常规的文件操作 */ error = deny_write_access(file); if (error) goto free_vma; } if (vm_flags & VM_SHARED) { /* 映射的文件允许其他进程可见, 标记文件为可写 */ error = mapping_map_writable(file->f_mapping); if (error) goto allow_write_and_free_vma; } /* ->mmap() can change vma->vm_file, but must guarantee that * vma_link() below can deny write-access if VM_DENYWRITE is set * and map writably if VM_SHARED is set. This usually means the * new file must not have been exposed to user-space, yet. */ vma->vm_file = get_file(file); /* 递增File的引用次数,返回File赋给vma*/ error = call_mmap(file, vma); /* 调用文件系统指定的mmap函数,后面会介绍 */
---》file->f_op->mmap(file, vma); if (error) goto unmap_and_free_vma; /* Can addr have changed?? * * Answer: Yes, several device drivers can do it in their * f_op->mmap method. -DaveM * Bug: If addr is changed, prev, rb_link, rb_parent should * be updated for vma_link() */ WARN_ON_ONCE(addr != vma->vm_start); addr = vma->vm_start; vm_flags = vma->vm_flags; } else if (vm_flags & VM_SHARED) { /* 假如标志为VM_SHARED,但没有指定映射文件,需要调用shmem_zero_setup() shmem_zero_setup()实际映射的文件是dev/zero */ error = shmem_zero_setup(vma); if (error) goto free_vma; } else { /* 既没有指定file, 也没有设置VM_SHARED, 即设置为匿名映射 */ vma_set_anonymous(vma); } /* 将申请的新vma加入mm中的vma链表*/ vma_link(mm, vma, prev, rb_link, rb_parent); /* Once vma denies write, undo our temporary denial count */ if (file) { if (vm_flags & VM_SHARED) mapping_unmap_writable(file->f_mapping); if (vm_flags & VM_DENYWRITE) allow_write_access(file); } file = vma->vm_file; out: perf_event_mmap(vma); /* 更新进程的虚拟地址空间mm */ vm_stat_account(mm, vm_flags, len >> PAGE_SHIFT); if (vm_flags & VM_LOCKED) { if ((vm_flags & VM_SPECIAL) || vma_is_dax(vma) || is_vm_hugetlb_page(vma) || vma == get_gate_vma(current->mm)) vma->vm_flags &= VM_LOCKED_CLEAR_MASK; else mm->locked_vm += (len >> PAGE_SHIFT); } if (file) uprobe_mmap(vma); /* * New (or expanded) vma always get soft dirty status. * Otherwise user-space soft-dirty page tracker won't * be able to distinguish situation when vma area unmapped, * then new mapped in-place (which must be aimed as * a completely new data area). */ vma->vm_flags |= VM_SOFTDIRTY; vma_set_page_prot(vma); return addr; unmap_and_free_vma: vma->vm_file = NULL; fput(file); /* Undo any partial mapping done by a device driver. */ unmap_region(mm, vma, prev, vma->vm_start, vma->vm_end); charged = 0; if (vm_flags & VM_SHARED) mapping_unmap_writable(file->f_mapping); allow_write_and_free_vma: if (vm_flags & VM_DENYWRITE) allow_write_access(file); free_vma: vm_area_free(vma); unacct_error: if (charged) vm_unacct_memory(charged); return error; }
mmap_region()调用了call_mmap(file, vma): call_mmap根据文件系统的类型选择适配的mmap()函数,我们选择目前常用的ext4:
ext4_file_mmap()是ext4对应的mmap, 功能非常简单,更新了file的修改时间(file_accessed(flie)),将对应的operation赋给vma->vm_flags:
三个操作函数的意义:
.fault: 处理Page Fault.map_pages: 映射文件至Page Cache.page_mkwrite: 修改文件的状态为可写
static const struct vm_operations_struct ext4_file_vm_ops = { .fault = ext4_filemap_fault, .map_pages = filemap_map_pages, .page_mkwrite = ext4_page_mkwrite, }; static int ext4_file_mmap(struct file *file, struct vm_area_struct *vma) { struct inode *inode = file->f_mapping->host; if (unlikely(ext4_forced_shutdown(EXT4_SB(inode->i_sb)))) return -EIO; /* * We don't support synchronous mappings for non-DAX files. At least * until someone comes with a sensible use case. */ if (!IS_DAX(file_inode(file)) && (vma->vm_flags & VM_SYNC)) return -EOPNOTSUPP; file_accessed(file); if (IS_DAX(file_inode(file))) { vma->vm_ops = &ext4_dax_vm_ops; vma->vm_flags |= VM_HUGEPAGE; } else { vma->vm_ops = &ext4_file_vm_ops; } return 0; }
mmap的源码我们发现在调用mmap()的时候仅仅申请一个vm_area_struct来建立文件与虚拟内存的映射,并没有建立虚拟内存与物理内存的映射。假如没有设置MAP_POPULATE标志位,Linux并不在调用mmap()时就为进程分配物理内存空间,直到下次真正访问地址空间时发现数据不存在于物理内存空间时,触发Page Fault即缺页中断,Linux才会将缺失的Page换入内存空间. 后面的文章我们会介绍Linux的缺页(Page fault)处理和请求Page的机制