公号:码农充电站pro
主页:https://codeshellme.github.io
1,常见的集群部署方式
ES 有以下不同类型的节点:
- Master(eligible)节点:只有 Master eligible 节点可以成为 Master 节点。
- Master 节点用于维护索引信息和集群状态。
- Data 节点:负责数据存储。
- Ingest 节点:数据预处理。
- Coordinating 节点:处理用户请求。
- ML 节点:机器学习相关功能。
在开发环境中,一个节点可以承担多种角色。
但是在生产环境,建议一个节点只负责单一角色,以达到高可用性及高性能。同时根据业务需求和硬件资源来合理分配节点。
1.1,节点配置参数
在默认情况下,一个节点会同时扮演 Master eligible Node,Data Node 和 Ingest Node。
各类型的节点配置参数如下:
| 节点类型 | 配置参数 | 默认值 |
|---|---|---|
| Master eligible | node.master | true |
| Data Node | node.data | true |
| Ingest Node | node.ingest | true |
| Coordinating | 无 | - |
| ML | node.ml | true(需要 enable x-pack) |
默认情况下,每个节点都是一个 Coordinating 节点,可以将 node.master,node.data 和 node.ingest 同时设置为 false,让一个节点只负责 Coordinating 节点的角色。
1.2,配置单一角色
默认情况下,一个节点会承担多个角色,可以通过配置让一个节点只负责单一角色。
单一职责节点配置:
- Master 节点:从高可用和避免脑裂的角度考虑,生产环境可配置 3 个 Master节点。
- node.master:
true - node.ingest:
false - node.data:
false
- node.master:
- Data 节点
- node.master:
false - node.ingest:
false - node.data:
true
- node.master:
- Ingest 节点
- node.master:
false - node.ingest:
true - node.data:
false
- node.master:
- Coordinating 节点
- node.master:
false - node.ingest:
false - node.data:
false
- node.master:
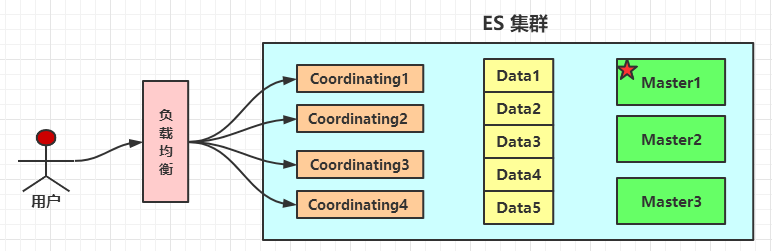
1.3,水平扩展架构
集群的水平扩展:
- 当需要更多的磁盘容量和读写能力时,可以增加 Data Node;
- 当系统有大量的复杂查询和聚合分析时,可以增加 Coordinating Node。
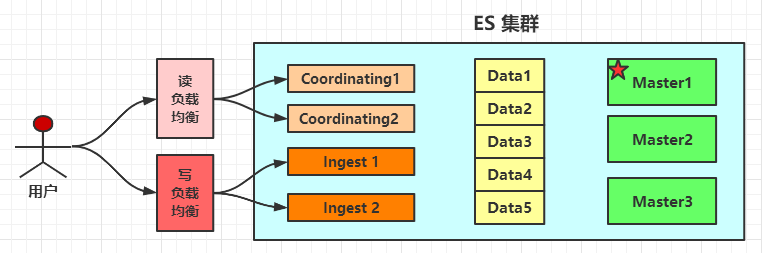
1.4,读写分离架构
使用 Ingest 节点对数据预处理。
2,分片设计与管理
ES 中的文档存储在索引中,索引的最小存储单位是分片,不同的索引存储在不同的分片中。
当讨论分片时,一般是基于某个索引的,不同索引之间的分片互不干扰。
分片分为主分片和副本分片两种;副本分片是主分片的拷贝,主要用于备份数据。
关于主副分片数的设置:
- 主分片数:主分片数在索引创建时确定,之后不能修改。
- 在 ES 7.0 以后,一个索引默认有一个主分片。
- 一个索引的主分片数不能超过 1024。
- 副本分片数:副本分片数在索引创建之后可以动态修改。
- 副本分片数默认为 1。
关于每个节点上的分片数的设置,可参考这里。
2.1,主分片的设计
如果某个索引只有一个主分片:
- 优点:查询算分和聚合不精准的问题都可避免。
- 缺点:集群无法实现水平扩展。
- 因为索引(不管该索引的数据量达到了多大)只能存储在一个主分片上(一个分片不能跨节点存储/处理);
- 对于单个主分片的索引来说,即使有再多的数据节点,它也无法利用。
如果某个索引有多个主分片:
- 优点:集群可以实现水平扩展。
- 对于拥有多个主分片的索引,该索引的数据可以分布在多个主分片上,不同的主分片可以分布在不同的数据节点中;这样,该索引就可以利用多个节点的读写能力,从而处理更多的数据。
- 如果当前的数据节点数小于主分片数,当有新的数据节点加入集群后,这些主分片就会自动被分配到新的数据节点上,从而实现水平扩容。
- 缺点:但是主分片数也不能过多,因为对于分片的管理也需要额外的资源开销。主要会带来以下问题:
- 每次搜索/聚合数据时需要从多个分片上获取数据,并汇总;除了会带来精准度问题,还会有性能问题。
- 分片的 Meta 信息由 Master 节点维护管理,过多的分片,会增加 Master 节点的负担。
对于分片的设计建议:
- 从分片的存储量考虑:
- 对于日志类应用,单个分片不要大于 50G;
- 对于搜索类应用,单个分片不要大于 20G;
- 从分片数量考虑:
- 一个 ES 集群的分片(包括主分片和副本分片)总数不超过 10 W。
2.2,副本分片的设计
副本分片是主分片的备份:
- 优点:
- 可防止数据丢失,提高系统的可用性;
- 可以分担主分片的查询压力,提高系统的查询性能。
- 缺点:
- 与主分片一样,需要占用系统资源,有多少个副本,就会增加多少倍的存储消耗。
- 会降低系统的写入速度。
3,集群容量规划
容量规划指的是,在一个实际项目中:
- 一个集群需要多少节点,以及节点类型分配。
- 一个索引需要几个主分片,几个副本分片。
3.1,要考虑的因素
做容量规划时要考虑的因素:
- 机器的软硬件配置
- 数据量:
- 单条文档的尺寸
- 文档的总数量
- 索引的总数量
- 业务需求:
- 文档的复杂度、数据格式
- 写入需求
- 查询需求
- 聚合需求
- 等
3.2,硬件配置
对系统整体性能要求高的,建议使用 SSD,内存与硬盘的比例可为 1:10。
对系统整体性能要求一般的,可使用机械硬盘,内存与硬盘的比例可为 1:50。
JVM 配置为机器内存的一半,建议 JVM 内存配置不超过 32 G。
单个节点的数据建议控制在 2TB 以内,最大不超过 5 TB。
3.3,常见应用场景
有如下常见应用场景:
- 搜索类应用:
- 总体数据集大小基本固定,数据量增长较慢。
- 日志类应用:
- 每日新增数据量比较稳定,数据量持续增长,可预期。
1,处理时间序列数据
ES 中提供了 Date Math 索引名用于写入时间序列的数据。
示例:
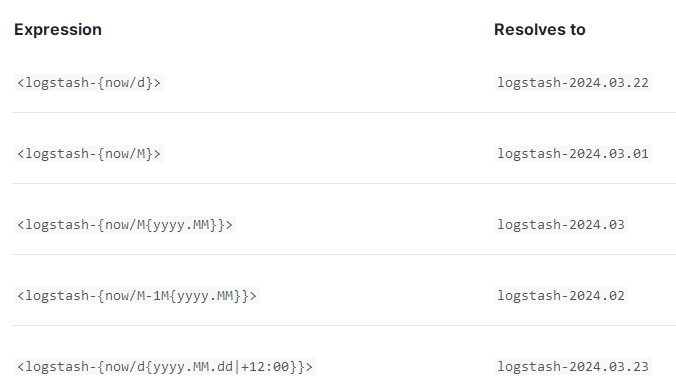
请求 URI 要经过 URL 编码:
# PUT /<my-index-{now/d}>
# 经过 URL 编码后
PUT /%3Cmy-index-%7Bnow%2Fd%7D%3E
查询示例:
# POST /<logs-{now/d}/_search
POST /%3Clogs-%7Bnow%2Fd%7D%3E/_search
# POST /<logs-{now/w}/_search
POST /%3Clogs-%7Bnow%2Fw%7D%3E/_search
4,ES 开发模式与生产模式
从 ES 5 开始,ES 支持开发模式与生产模式,ES 可通过配置自动选择不同的模式去运行:
- 开发模式配置:
- http.host:localhost
- transport.bind_host:localhost
- 生产模式配置:
- http.host:真实 IP 地址
- transport.bind_host:真实 IP 地址
4.1,Booststrap 检测
在生产模式启动 ES 集群时,会进行 Booststrap 检测(只有检测通过才能启动成功),它包括:
- JVM 检测
- Linux 检测:只在 Linux 环境进行
4.2,JVM 配置
JVM 通过 config 目录下的 jvm.options 文件进行配置,需要注意以下几点:
- 将 Xms 和 Xmx 设置成一样;
- Xmx 不要超过物理内存的 50%,最大内存建议不超过 32G;
- JVM 有 Server 和 Client 两种模式,在 ES 的生产模式必须使用 Server 模式;
- 需要关闭 JVM Swapping
4.3,更多的 ES 配置
更多的关于 ES 的配置可参考其官方文档,包括:
5,监控集群状态
集群状态为 Green 只能代表分片正常分配,不能代表没有其它问题。
ES 提供了很多监控相关的 API:
- _cluster/health:集群健康状态。
- _cluster/state:集群状态。
- _cluster/stats:集群指标统计。
- _cluster/pending_tasks:集群中正在执行的任务。
- _tasks:集群任务。
- _cluster/allocation/explain:查看集群分片的分配情况,用于查找原因。
- _nodes/stats:节点指标统计。
- _nodes/info:节点信息。
- _index/stats:索引指标统计。
- 一些 cat API。
5.1,Slow log
ES 的 Slow log 可以设置一些阈值,当写入时间或者查询时间超过这些阈值后,会将相关操作记录日志。
5.2,集群诊断
需要监控的指标:
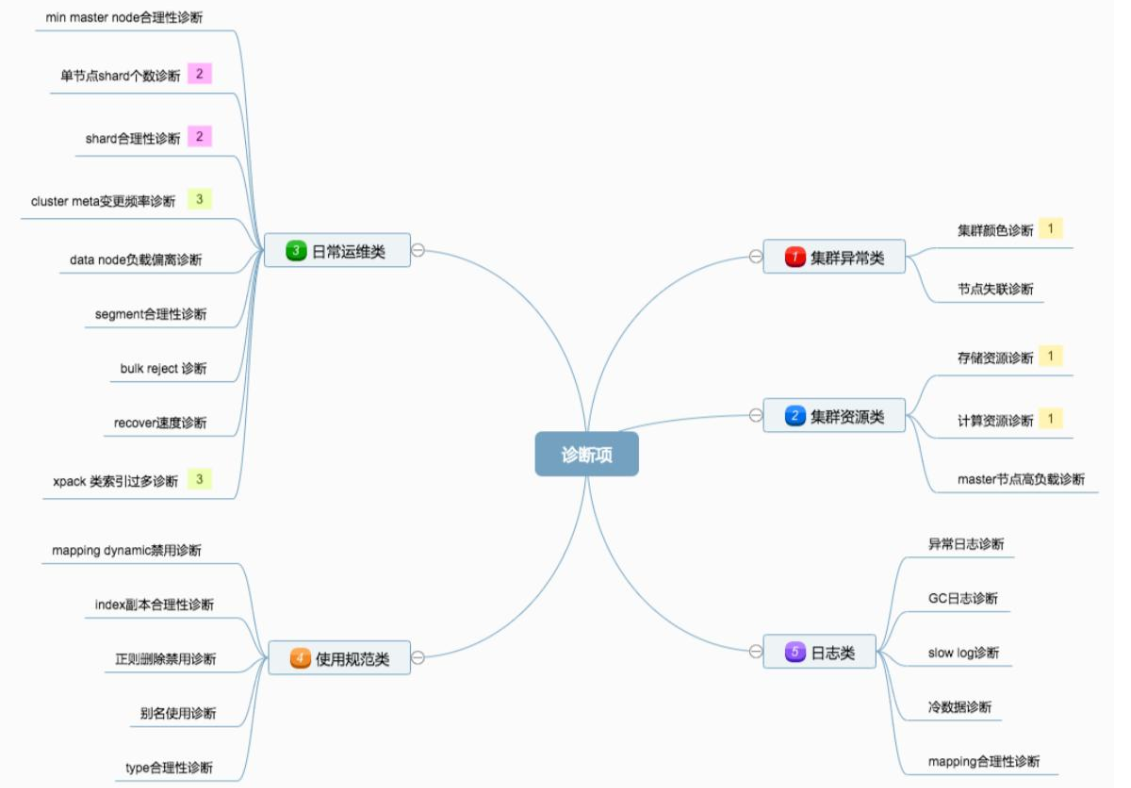
一个集群诊断工具 Support Diagnostics。
(本节完。)
推荐阅读:
欢迎关注作者公众号,获取更多技术干货。
