公号:码农充电站pro
主页:https://codeshellme.github.io
DSL(Domain Specific Language)查询也叫做 Request Body 查询,它比 URI 查询更高阶,能支持更复杂的查询。
1,分页
默认情况下,查询按照算分排序,返回前 10 条记录。
ES 也支持分页,分页使用 from-size:
- from:从第几个文档开始返回,默认为 0。
- size:返回的文档数,默认为 10。
示例:
POST /index_name/_search
{
"from":10,
"size":20,
"query":{
"match_all": {}
}
}
1.1,深度分页问题
ES 是一个分布式系统,数据保存在多个分片中,那么查询时就需要查询多个分片。
比如一个查询 from = 990; size = 10,那么 ES 需要在每个分片上都获取 1000 个文档:
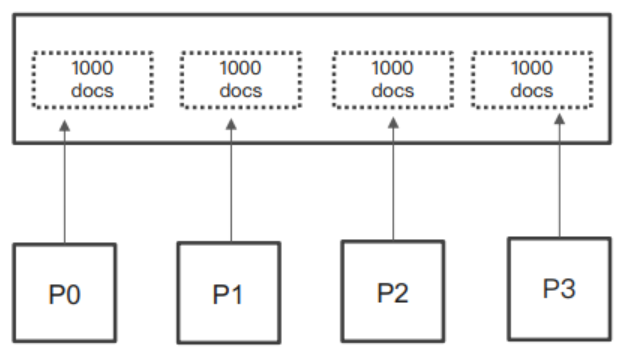
然后通过 Coordinating 节点汇总结果,最后再通过排序获取前 1000 个文档。
这种方式,当页数很深的时候,就会占用很多内存,从而给 ES 集群带来很大的开销,这就是深度分页问题。
因此,ES 为了避免此类问题带来的巨大开销,有个默认的限制 index.max_result_window,from + size 必须小于等于 10000,否则就会报错。
比如:
POST index_name/_search
{
"from": 10000, # 报错
"size": 1,
"query": {
"match_all": {}
}
}
POST index_name/_search
{
"from": 0, # 报错
"size": 10001,
"query": {
"match_all": {}
}
}
为了解决深度分页问题,ES 有两种解决方案:Search After 和 Scroll。
1.2,Search After
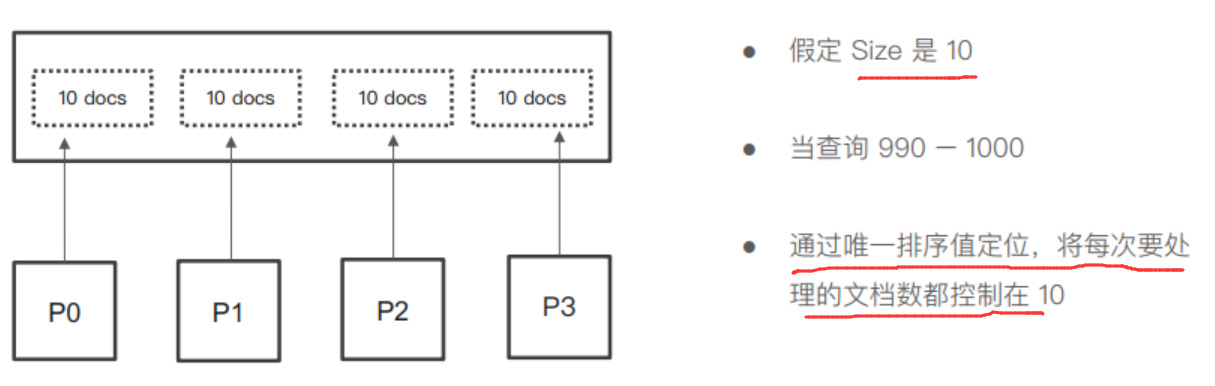
Search After 通过实时获取下一页的文档信息来实现,使用方法:
- 第一步搜索需要指定 sort,并且保证值是唯一的(通过sort by id 来保证)。
- 随后的搜索,都使用上一次搜索的最后一个文档的 sort 值进行搜索。
Search After 的方式不支持指定页数,只能一页一页的往下翻。
Search After 的原理:
示例:
# 插入一些数据
DELETE users
POST users/_doc
{"name":"user1","age":10}
POST users/_doc
{"name":"user2","age":11}
POST users/_doc
{"name":"user2","age":12}
POST users/_doc
{"name":"user2","age":13}
# 第一次搜索
POST users/_search
{
"size": 1, # size 值
"query": {
"match_all": {}
},
"sort": [
{"age": "desc"} ,
{"_id": "asc"} # sort by id
]
}
# 此时返回的文档中有一个 sort 值
# "sort" : [13, "4dR-IHcB71-f4JZcrL2z"]
# 之后的每一次搜索都需要用到上一次搜索结果的最后一个文档的 sort 值
POST users/_search
{
"size": 1,
"query": {
"match_all": {}
},
"search_after": [ # 上一次搜索结果的最后一个文档的 sort 值放在这里
13, "4dR-IHcB71-f4JZcrL2z"],
"sort": [
{"age": "desc"} ,
{"_id": "asc"}
]
}
1.3,Scroll
Scroll 通过创建一个快照来实现,方法:
- 每次查询时,输入上一次的
Scroll Id。
Scroll 方式的缺点是,当有新的数据写入时,新写入的数据无法被查到(第一次建立快照时有多少数据,就只能查到多少数据)。
示例:
# 写入测试数据
DELETE users
POST users/_doc
{"name":"user1","age":10}
POST users/_doc
{"name":"user2","age":20}
# 第一次查询前,先建立快照,快照存在时间为 5 分钟,一般不要太长
POST /users/_search?scroll=5m
{
"size": 1,
"query": {
"match_all" : {}
}
}
# 返回的结果中会有一个 _scroll_id
# 查询
POST /_search/scroll
{
"scroll" : "1m", # 快照的生存时间,这里是 1 分钟
"scroll_id" : "xxx==" # 上一次的 _scroll_id 值
}
# 每次的查询结果都会返回一个 _scroll_id,供下一次查询使用
# 所有的数据被查完以后,再查询就得不到数据了
1.4,不同分页方式的使用场景
分页方式共 4 种:
- 普通查询(不使用分页):需要实时获取顶部的部分文档。
- From-Size(普通分页):适用于非深度分页。
- Search After:需要深度分页时使用。
- Scroll:需要全部文档,比如导出全部数据。
2,排序
ES 默认使用算分进行排序,我们可以使用 sort-processor(不需要再计算算分)来指定排序规则;可以对某个字段进行排序,最好只对数字型和日期型字段排序。
示例:
POST /index_name/_search
{
"sort":[{"order_date":"desc"}], # 单字段排序
"query":{
"match_all": {}
}
}
POST /index_name/_search
{
"query": {
"match_all": {}
},
"sort": [ # 多字段排序
{"order_date": {"order": "desc"}},
{"_doc":{"order": "asc"}},
{"_score":{ "order": "desc"}} # 如果不指定 _score,那么算分为 null
]
}
对 text 类型的数据进行排序会发生错误,可以通过打开 fielddata 参数(一般不建议这么做),来对 text 类型进行排序:
# 打开 text的 fielddata
PUT index_name/_mapping
{
"properties": {
"customer_full_name" : { # 字段名称
"type" : "text",
"fielddata": true, # 打开 fielddata
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
}
}
}
3,字段过滤
可以使用 _source 设置需要返回哪些字段。示例:
POST /index_name/_search
{
"_source":["order_date", "xxxxx"],
"query":{
"match_all": {}
}
}
_source 中可以使用通配符,比如 ["name*", "abc*"]。
4,脚本字段
可以使用脚本进行简单的表达式运算。
POST /index_name/_search
{
"script_fields": { # 固定写法
"new_field": { # 新的字段名称
"script": { # 固定写法
"lang": "painless", # 固定写法
"source": "doc['order_date'].value+'hello'" # 脚本语句
}
}
},
"query": {
"match_all": {}
}
}
5,查询与过滤
查询会有相关性算分;过滤不需要进行算分,可以利用缓存,性能更好。
参考这里。
6,全文本查询
全文本(Full text)查询会对搜索字符串进行分词处理。
全文本查询有以下 9 种:
- intervals 查询:可以对匹配项的顺序和接近度进行细粒度控制。
- match 查询:全文本查询中的标准查询,包括模糊匹配、短语和近似查询。
- match_bool_prefix 查询:
- match_phrase 查询:
- match_phrase_prefix 查询:
- multi_match 查询:
- common terms 查询:
- query_string 查询:
- simple_query_string 查询:
6.1,Match 查询
Match 查询是全文搜索的标准查询,与下面的几种查询相比,更加强大,灵活性也更大,最常使用。
Match 查询会先对输入字符串进行分词,然后对每个词项进行底层查询,最后将结果合并。
例如对字符串 "Matrix reloaded" 进行查询,会查到包含 "Matrix" 或者 "reloaded" 的所有结果。
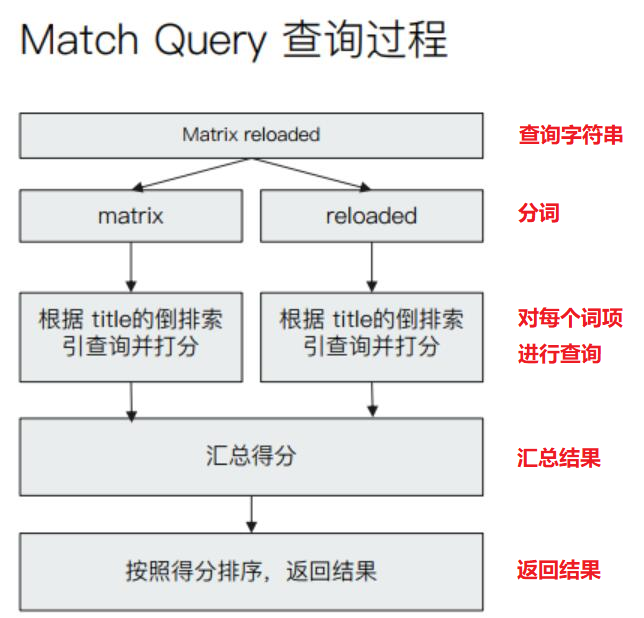
示例:
POST index_name/_search
{
"query": {
"match": {
"title": "last christmas" # 表示包含 last 或 christmas
}
}
}
POST index_name/_search
{
"query": {
"match": {
"title": { # 表示包含 last 且 包含 christmas,不一定挨着
"query": "last christmas",
"operator": "and"
}
}
}
}
6.2,Match Phrase 查询
使用 match_phrase 关键字。示例:
POST index_name/_search
{
"query": {
"match_phrase": {
"title":{
"query": "one love" # "one love" 相当于一个单词
}
}
}
}
POST index_name/_search
{
"query": {
"match_phrase": {
"title":{
"query": "one love",
"slop": 1 # "one" 和 "love" 之间可以有 1 个字符
}
}
}
}
6.3,Query String 查询
使用 query_string 关键字。示例:
POST index_name/_search
{
"query": {
"query_string": {
"default_field": "name", # 默认查询字段,相当于 URI 查询中的 df
"query": "Ruan AND Yiming" # 可以使用逻辑运算符
}
}
}
# 多 fields 与 分组
POST index_name/_search
{
"query": {
"query_string": {
"fields":["name","about"], # 多个 fields
"query": "(Ruan AND Yiming) OR (Java AND Elasticsearch)" # 支持分组
}
}
}
POST index_name/_search
{
"query":{
"query_string":{
"fields":["title","year"],
"query": "2012"
}
}
}
6.4,Simple Query String 查询
使用 simple_query_string 关键字。
特点:
- query 字段中不支持
AND OR NOT,会当成普通字符串。AND用+替代OR用|替代NOT用-替代
- Term 之间默认的关系是
OR,可以指定default_operator来修改。
示例:
# Simple Query 默认的 operator 是 OR
POST index_name/_search
{
"query": {
"simple_query_string": {
"query": "Ruan AND Yiming", # 这里的 AND 会当成普通的字符串
"fields": ["name"]
}
}
}
POST index_name/_search
{
"query": {
"simple_query_string": {
"query": "Ruan Yiming",
"fields": ["name"],
"default_operator": "AND"
}
}
}
GET index_name/_search
{
"query":{
"simple_query_string":{
"query":"Beautiful +mind",
"fields":["title"]
}
}
}
6.5,Multi-match 查询
一个字符串在多个字段中查询的情况,如何匹配最终的结果。(还有一个 dis-max 查询也是针对这种情况的)
一个字符串在多个字段中查询的情况,Multi-match 有 6 种处理方式,如下:
- best_fields:最终得分为分数最高的那个字段,默认的处理方式。
- most_fields:算分相加。不支持 AND 操作。
- cross_fields:跨字段搜索,将一个查询字符串在多个字段(就像一个字段)上搜索。
- phrase:
- phrase_prefix:
- bool_prefix:
示例:
POST index_name/_search
{
"query": {
"multi_match" : { # multi_match 查询
"query": "brown fox", # 查询字符串
"type": "best_fields", # 处理方式
"fields": [ "subject", "message" ], # 在多个字段中查询,fields 是一个数组
"tie_breaker": 0.3
}
}
}
7,Term 查询
Term 查询与全文本查询不同的是,Term 查询不会对查询字符串进行分词处理,Term 查询会在字段匹配精确值。
Term 查询输入字符串作为一个整体,在倒排索引中查找匹配的词项,并且会计算相关性评分。
Term 查询包括以下 11 种:
- exists 查询
- fuzzy 查询
- ids 查询
- prefix 查询
- range 查询
- regexp 查询
- term 查询:如果某个文档的指定字段包含某个确切值,则返回该文档。
- terms 查询
- terms_set 查询
- type 查询
- wildcard 查询
7.0,结构化数据与查询
结构化查询是对结构化数据的查询,可以使用 Term 语句进行查询。
结构化数据有着固定的格式,包括:
- 日期:日期比较,日期范围运算等。
- 布尔值:逻辑运算。
- 数字:数字大小比较,范围比较等。
- 某些文本数据:比如标签数据,关键词等。
结构化查询是对结构化数据的逻辑运算,运算结果只有“是”和“否”。
7.1,term 查询
如果某个文档的指定字段包含某个确切值,则返回该文档。
1,示例 1 精确匹配
下面举一个 term 查询的例子,首先插入一个文档:
POST /products/_bulk
{ "index": { "_id": 1 }}
{ "productID" : "XHDK-A-1293-#fJ3","desc":"iPhone" }
该文档插入时,会使用默认的分词器进行分词处理。
使用 term 查询:
POST /products/_search
{
"query": {
"term": {
"desc": {
# "value": "iPhone" # 会对 iPhone 精确匹配查询。
# 文档插入时,iPhone 变成了 iphone
# 所以查 iPhone 查不到任何内容
"value":"iphone" # 查 iphone 能查到
}
}
}
}
keyword 子字段
ES 默认会对 text 类型的数据建立一个 keyword 子字段,用于精确匹配,这称为 ES 的多字段属性。
keyword 子字段将原始数据原封不动的存储了下来。
可以通过 mapping 查看,如下所示:
"desc" : { # 字段名称
"type" : "text", # text 数据类型
"fields" : {
"keyword" : { # keyword 子字段
"type" : "keyword", # keyword 子类型
"ignore_above" : 256
}
}
}
下面使用 keyword 子字段进行查询:
POST /products/_search
{
"query": {
"term": {
"desc.keyword": { # 在 desc 字段的 keyword 子字段中查询
"value": "iPhone" # 能查到
//"value":"iphone" # 查不到
}
}
}
}
2,示例 2 查询布尔值
term 查询有算分:
POST index_name/_search
{
"query": { # 固定写法
"term": { # term 查询,固定写法
"avaliable": true # 查询 avaliable 字段的值为 true 的文档
}
}
}
如果不需要算分,可以使用 constant_score 查询,示例:
POST index_name/_search
{
"query": {
"constant_score": { # constant_score 查询,固定写法
"filter": { # 固定写法
"term": { # constant_score 包装一个 term 查询,就没有了算分
"avaliable": true
}
}
}
}
}
7.2,range 查询
range 查询中有几个常用的比较运算:
| 运算符 | 含义 |
|---|---|
| gt | 大于 |
| gte | 大于等于 |
| lt | 小于 |
| lte | 小于等于 |
1,数字类型 range 查询
示例:
POST index_name/_search
{
"query": { # 固定写法
"range": { # range 查询
"age": { # 字段名称
"gte": 10, # 10 <= age <= 20
"lte": 20
}
}
}
}
2,日期类型 range 查询
对于日期类型有几个常用的符号:
| 符号 | 含义 |
|---|---|
| y | 年 |
| M | 月 |
| w | 周 |
| d | 天 |
| H / h | 小时 |
| m | 分钟 |
| s | 秒 |
| now | 现在 |
示例:
POST index_name/_search
{
"query" : { # 固定写法
"range" : { # range 查询
"date" : { # 字段名称
"gte" : "now-10y" # 10年之前
}
}
}
}
7.3,exists 查询
exists 语句可以判断文档是否存在某个字段。
搜索存在某个字段的文档,示例:
POST index_name/_search
{
"query" : {
"exists": { # 存在 date 字段的文档
"field": "date"
}
}
}
搜索不存在某个字段的文档,需要使用布尔查询。
示例:
POST index_name/_search
{
"query": {
"bool": { # 布尔查询
"must_not": { # 不存在
"exists": { # 不存在 date 字段的文档
"field": "date"
}
}
}
}
}
7.4,terms 查询
terms 语句用于处理多值查询,相当于一个多值版的 term 语句,可以一次查询多个值。
示例:
POST index_name/_search
{
"query": {
"terms": { # terms 查询
"productID.keyword": [ # 字段名称
"QQPX-R-3956-#aD8", # 多个值
"JODL-X-1937-#pV7"
]
}
}
}
8,复合查询
复合查询(Compound)能够包装其他复合查询或叶查询,以组合其结果和分数,更改其行为或者将查询转成过滤。
复合查询有以下 5 种:
8.1,bool 查询
bool 查询是一个或多个子查询的组合,共包含以下 4 种子句:
- must:必须匹配,属于查询,贡献算分。
- filter:必须匹配,属于过滤器,不贡献算分。
- should:选择性匹配,只要有一个条件匹配即可,属于查询,贡献算分。
- must_not:必须不匹配,属于过滤器,不贡献算分。
bool 查询的多个子句之间没有顺序之分,并且可以嵌套。
示例:
POST index_name/_search
{
"query": {
"bool" : {
"must" : {
"term" : { "user.id" : "kimchy" }
},
"filter": {
"term" : { "tags" : "production" }
},
"must_not" : {
"range" : {
"age" : { "gte" : 10, "lte" : 20 }
}
},
"should" : [ # 是一个数组
{ "term" : { "tags" : "env1" } },
{ "term" : { "tags" : "deployed" } }
],
"minimum_should_match" : 1,
"boost" : 1.0
}
}
}
8.2,boosting 查询
boosting 查询会给不同的查询条件分配不同的级别(positive / negative),不同的级别对算分有着不同的印象,从而影响最终的算分。
positive 级别会对算分有正面影响, negative 级别会对算分有负面影响。
我们可以使用 boosting 查询给某些文档降级(降低算分),而不是将其从搜索结果中排除。
示例:
GET index_name/_search
{
"query": {
"boosting": { # boosting 查询
"positive": { # positive 级别
"term": { # 匹配 apple 的会对算分有正面影响
"text": "apple"
}
},
"negative": { # negative 级别
"term": { # 匹配这个的会对算分有负面影响
"text": "pie tart fruit crumble tree"
}
},
"negative_boost": 0.5 # 降级的力度
}
}
}
8.3,constant_score 查询
constant_score 查询可以将查询转成一个过滤,可以避免算分(降低开销),并有效利用缓存(提高性能)。
示例:
POST /index_name/_search
{
"query": {
"constant_score": { # constant_score 查询
"filter": { # 过滤器,固定写法
"term": { # 包装了一个 term 查询,将 term 查询转成了过滤
"productID.keyword": "XHDK-A-1293-#fJ3"
}
}
}
}
}
8.4,dis_max 查询
一个字符串在多个字段中查询的情况,如何匹配最终的结果。(还有一个 Multi-match 查询也是针对这种情况的)
示例:
POST index_name/_search
{
"query": {
"bool": {
"should": [ # should 语句会综合所有的字段的分数,最终给出一个综合分数
{ "match": { "title": "Brown fox" }},
{ "match": { "body": "Brown fox" }}
]
}
}
}
POST index_name/_search
{
"query": {
"dis_max": { # dis_max 语句不会综合所有字段的分数,而把每个字段单独来看
"queries": [ # 最终结果是所有的字段中分数最高的
{ "match": { "title": "Quick pets" }},
{ "match": { "body": "Quick pets" }}
]
}
}
}
8.5,function_score 查询
function_score 查询可以在查询结束后,对每一个匹配的文档进行重新算分,然后再根据新的算分进行排序。
它提供了以下 5 种算分函数:
- script_score:自定义脚本。
- weight:为文档设置一个权重。
- random_score:随机算分排序。
- field_value_factor:使用该数值来修改算分。
- decay functions: gauss, linear, exp:以某个字段为标准,距离某个值越近,得分越高。
1,field_value_factor 示例
首先插入测试数据:
DELETE blogs
PUT /blogs/_doc/1
{
"title": "About popularity",
"content": "In this post we will talk about...",
"votes": 0
}
PUT /blogs/_doc/2
{
"title": "About popularity",
"content": "In this post we will talk about...",
"votes": 100
}
PUT /blogs/_doc/3
{
"title": "About popularity",
"content": "In this post we will talk about...",
"votes": 1000000
}
查询示例1:
新的算分 = 老的算分 * 投票数
POST /blogs/_search
{
"query": {
"function_score": {
"query": {
"multi_match": { # 该查询会有一个算分
"query": "popularity",
"fields": [ "title", "content" ]
}
},
"field_value_factor": { # 最终的算分要乘以 votes 字段的值
"field": "votes"
}
}
}
}
上面这种算法当出现这两种情况的时候,会出现问题:
- 投票数为 0
- 投票数特别大
查询示例2,引入平滑函数:
新的算分 = 老的算分 * 平滑函数(投票数)
POST /blogs/_search
{
"query": {
"function_score": {
"query": {
"multi_match": {
"query": "popularity",
"fields": [ "title", "content" ]
}
},
"field_value_factor": {
"field": "votes",
"modifier": "log1p" # 在原来的基础上加了一个平滑函数
} # 新的算分 = 老的算分 * log(1 + 投票数)
}
}
}
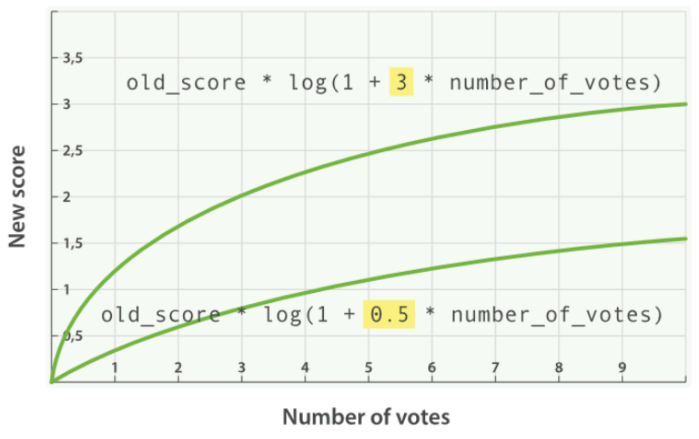
平滑函数有下面这些:

查询示例3,引入 factor :
新的算分 = 老的算分 * 平滑函数(factor * 投票数)
POST /blogs/_search
{
"query": {
"function_score": {
"query": {
"multi_match": {
"query": "popularity",
"fields": [ "title", "content" ]
}
},
"field_value_factor": {
"field": "votes",
"modifier": "log1p" ,
"factor": 0.1
}
}
}
}
引入 factor 之后的算分曲线:
2,Boost Mode 和 Max Boost 参数
Boost Mode:
- Multiply:算分与函数值的乘积。
- Sum:算分与函数值的和。
- Min / Max:算分与函数值的最小/最大值。
- Replace:使用函数值替代算分。
Max Boost 可以将算分控制在一个最大值。
示例:
POST /blogs/_search
{
"query": {
"function_score": {
"query": {
"multi_match": {
"query": "popularity",
"fields": [ "title", "content" ]
}
},
"field_value_factor": {
"field": "votes",
"modifier": "log1p" ,
"factor": 0.1
},
"boost_mode": "sum",
"max_boost": 3
}
}
}
3,random_score 示例
示例:
POST /blogs/_search
{
"query": {
"function_score": {
"random_score": { # 将原来的查询结果随机排序
"seed": 911119 # 随机种子
}
}
}
}
(本节完。)
推荐阅读:
欢迎关注作者公众号,获取更多技术干货。
